LikwidMarkerAPIPitfalls
Most users of LIKWID that want to measure just a region of their code, like to use LIKWID's MarkerAPI. The MarkerAPI is a set of macros/functions that can be embedded in the code and turned on and off at compile time. In contrast to other tools that support measuring regions of code, the MarkerAPI just specifies where to measure but not what to measure. The configuration is done from the outside by using LIKWID's likwid-perfctr or by setting the appropriate environment variables.
Although the MarkerAPI has only a few calls, it is crucial where to put them and maybe how to restructure the code to make it work. This page gives some hints about the operations done by the calls and some tricky examples with explainations.
If you stick to the 4 basic calls and the region is traversed only once, it is quite simple to add the MarkerAPI. The example uses OpenMP:
LIKWID_MARKER_INIT;
#pragma omp parallel #pragma omp parallel
{ {
LIKWID_MARKER_START("do_op");
#pragma omp for -> #pragma omp for
for (i = 0; i < N; i++) for (i = 0; i < N; i++)
do_op(i); do_op(i);
LIKWID_MARKER_STOP("do_op");
} }
LIKWID_MARKER_CLOSE;
If you use only the 4 basic calls, those are the rules:
- Call
LIKWID_MARKER_INITonly once in your application. Recommendation is the beginning of themainroutine of your code. There is a guard inside that should prevent problems when it is called multiple times, but don't do it. - Call
LIKWID_MARKER_CLOSEonly once in your application. Recommendation is the end of themainroutine of your code. There is NO guard if you call it multiple times and will overwrite the output file, skewing up results if you measure between two calls toLIKWID_MARKER_CLOSE, so don't do it. -
LIKWID_MARKER_START(str)andLIKWID_MARKER_STOP(str)should be called once per application thread. There is some logic inside if it is called not by all application threads, but there might be problems.
- Recommended usage of
LIKWID_MARKER_REGISTER - Placement of
LIKWID_MARKER_INIT - My code region is quite short
- The measured times for multiple threads vary although all perform the same operation
- What about
LIKWID_MARKER_THREADINIT? - How to use
LIKWID_MARKER_SWITCH? - How to get the measured values in my application?
- Resetting the results of a region
- LIKWID measures FP operations with MarkerAPI for non-FP code
- My application hangs when using the MarkerAPI
- My application calls a function in a library that does the threading
One of the major recommendation, that can solve already many problems you might have with the MarkerAPI, is the usage of LIKWID_MARKER_REGISTER(). With increasing core counts of modern CPU architectures, the overhead to start up the access layer of LIKWID can be quite high. If it is part of the first execution of LIKWID_MARKER_START(), it might skew the results. Therefore register all regions before in a separate parallel region spanning all threads with a barrier in the end/afterwards (The OpenMP parallel construct contains an implicit barrier in the end).
The MarkerAPI get initialized with LIKWID_MARKER_INIT. This does not only include the MarkerAPI logic itself but sets up the whole LIKWID stack including register access checks, starting of separate processes and other quite expensive operations. It is recommended to execute it early in the execution process (for C/C++ projects: put it in the beginning of main) because loaded libraries might affect this initialization. We got reports of deadlocks if LIKWID_MARKER_INIT is located after the first OpenMP call. So, to avoid problems, call LIKWID_MARKER_INIT early in the execution and LIKWID_MARKER_CLOSE late in the exection.
It is simple to put instrumentation calls inside your application, but always remember, they have overhead which (in most cases) does not come from LIKWID directly but the system calls to access the hardware counters. Independent of the ACCESSMODE you selected at config.mk, system calls are executed. Of course, if you use more events, the overhead is getting larger.
Let's look at some code (excerpt from McCalpin's STREAM benchmark):
for (k=0; k<NTIMES; k++)
{
// copy
#pragma omp parallel for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
c[j] = a[j];
// scale
#pragma omp parallel for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
b[j] = scalar*c[j];
}
Even if the STREAM_ARRAY_SIZE is large, each execution of the copy or scale loop is not taking long. Additionally, the OpenMP parallel region is not opened once but each loop is a separate parallel region. If we put MarkerAPI calls there, it would look like this:
LIKWID_MARKER_INIT;
for (k=0; k<NTIMES; k++)
{
// copy
#pragma omp parallel
{
LIKWID_MARKER_START("copy");
#pragma omp for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
c[j] = a[j];
LIKWID_MARKER_STOP("copy");
}
// scale
#pragma omp parallel
{
LIKWID_MARKER_START("scale");
#pragma omp for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
b[j] = scalar*c[j];
LIKWID_MARKER_STOP("scale");
}
}
LIKWID_MARKER_CLOSE;
So, the MarkerAPI regions are traversed NTIMES and we get the results. But execute the original code and see how fast you get the results, especially if you leave the defaults of NTIMES=10 and STREAM_ARRAY_SIZE=10000000 (76MB). That's only slightly larger than todays server-class CPU caches.
So, if the STREAM_ARRAY_SIZE is reasonable large, you will get proper results. Of course, the MarkerAPI calls increase the total runtime but the loop of interest is not affected much.
If STREAM_ARRAY_SIZE is small, the MarkerAPI calls are using a higher fraction of the loop's runtime. If you have timing routines (like STREAM) and calculate some time-based metric (like bandwidths), the results might be wrong because the time contains also the MarkerAPI calls, if you place the MarkerAPI calls inside the timed region. The way to disturb the run in minimal way requires some code restructuring and failed validation (in case of STREAM). Here only the copy part:
LIKWID_MARKER_INIT;
#pragma omp parallel
{
LIKWID_MARKER_START("copy");
for (k=0; k<NTIMES; k++)
{
// copy
#pragma omp for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
c[j] = a[j];
}
LIKWID_MARKER_STOP("copy");
}
LIKWID_MARKER_CLOSE;
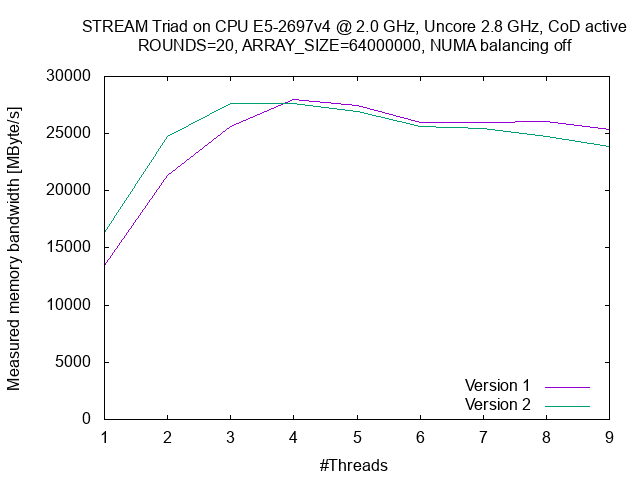
This way, the benchmark can execute the array copy without influences from the MarkerAPI. The result of this loop is different to the one before but it performs the same operation. If you want reliable results, make sure the whole region is executed a reasonable amount of time (like above one second). When you measure the region, you might be surprised that (in case of memory counter measurements with the MEM group especially) the bandwidths decrease with increasing thread counts.
In some cases, you might see measurements like this:
Let's look at one output (just an excerpt):
+-------------------+----------+----------+----------+----------+----------+----------+
| Region Info | Core 0 | Core 1 | Core 2 | Core 3 | Core 4 | Core 5 |
+-------------------+----------+----------+----------+----------+----------+----------+
| RDTSC Runtime [s] | 1.227251 | 0.975324 | 0.995353 | 1.005493 | 0.975347 | 0.975315 |
| call count | 20 | 20 | 20 | 20 | 20 | 20 |
+-------------------+----------+----------+----------+----------+----------+----------+
The problem with this code is that the first LIKWID_MARKER_START performs some operations that increases the runtime of the master thread (Core 0). You can see this especially if ACCESSMODE=accessdaemon because each application thread requires it's own instance of the access daemon to perform simultaneous access to the hardware registers (UNIX sockets connection between library and access daemon is not thread-safe). Other operations are the creation of hash table entries for the string copy. To fix this, we can tell the MarkerAPI, to do these operations already in a separate part of the application using LIKWID_MARKER_REGISTER():
LIKWID_MARKER_INIT;
#pragma omp parallel
{
LIKWID_MARKER_REGISTER("copy");
}
#pragma omp parallel
{
LIKWID_MARKER_START("copy");
for (k=0; k<NTIMES; k++)
{
// copy
#pragma omp for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
c[j] = a[j];
}
LIKWID_MARKER_STOP("copy");
}
LIKWID_MARKER_CLOSE;
Although LIKWID_MARKER_REGISTER() is optional, it is highly recommended to register all regions before by all threads. Between the calls of LIKWID_MARKER_REGISTER() and LIKWID_MARKER_START() should be a barrier, either implicit or explicit, or you will have the same effect as not using LIKWID_MARKER_REGISTER() at all. The above code contains an implicit barrier as the closing of an OpenMP parallel region executes a barrier. Another method would be like this:
LIKWID_MARKER_INIT;
#pragma omp parallel
{
LIKWID_MARKER_REGISTER("copy");
#pragma omp barrier
for (k=0; k<NTIMES; k++)
{
LIKWID_MARKER_START("copy");
// copy
#pragma omp for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
c[j] = a[j];
LIKWID_MARKER_STOP("copy");
}
}
LIKWID_MARKER_CLOSE;
If we look at an output with LIKWID_MARKER_REGISTER, the runtime variation is gone:
+-------------------+----------+----------+----------+----------+----------+----------+
| Region Info | Core 0 | Core 1 | Core 2 | Core 3 | Core 4 | Core 5 |
+-------------------+----------+----------+----------+----------+----------+----------+
| RDTSC Runtime [s] | 0.998868 | 0.998894 | 0.998902 | 0.998866 | 0.998937 | 0.998862 |
| call count | 20 | 20 | 20 | 20 | 20 | 20 |
+-------------------+----------+----------+----------+----------+----------+----------+
In LIKWID 3 and 4, the application threads needed to be registered in the MarkerAPI using LIKWID_MARKER_THREADINIT. This is not required anymore because the MarkerAPI is able to determine new threads by itself (Version 5). The call is still present and can be called but commonly has no effect anymore. There is one exception:
If you use a threading enviroment which is not based on Pthreads and the application does not pin the threads itself to hardware threads, you have to call LIKWID_MARKER_THREADINIT by each thread to perform the pinning. The MarkerAPI measures only on selected hardware threads and if your application thread runs on a different one, you get bad results and maybe errors.
With Version 4 and 5 of LIKWID, the user is able to specify multiple event sets and/or performance groups on the command line (or in the approriate environment variable). If you don't use the MarkerAPI, LIKWID switches between the groups every X seconds (selectable with -T Xs) and presents the values in the end. In case of the MarkerAPI, the user has to add LIKWID_MARKER_SWITCH in the desired code location. LIKWID_MARKER_SWITCH has to be called in a serial region and no application thread is allowed to access the hardware counters while LIKWID_MARKER_SWITCH.
Here is an example of a valid use of LIKWID_MARKER_SWITCH:
LIKWID_MARKER_INIT;
#pragma omp parallel
{
LIKWID_MARKER_REGISTER("copy");
}
#pragma omp parallel
{
LIKWID_MARKER_START("copy");
for (k=0; k<NTIMES; k++)
{
// copy
#pragma omp for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
c[j] = a[j];
}
LIKWID_MARKER_STOP("copy");
}
LIKWID_MARKER_SWITCH;
#pragma omp parallel
{
LIKWID_MARKER_START("triad");
for (k=0; k<NTIMES; k++)
{
// triad
#pragma omp for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
a[j] = b[j]+scalar*c[j];
}
LIKWID_MARKER_STOP("triad");
}
LIKWID_MARKER_CLOSE;
The code is similar to the already used examples. The implicit barrier at the end of the parallel region causes that no thread is still in LIKWID_MARKER_STOP("copy"). The code does not make too much sense because we measure the copy kernel only with one group and the triad kernel with another group. If there is only a single event set/performance group available, LIKWID_MARKER_SWITCH does nothing. So both regions would be measured with the same event set.
Let's look a different code:
LIKWID_MARKER_INIT;
#pragma omp parallel
{
LIKWID_MARKER_REGISTER("copy");
#pragma omp barrier
for (k=0; k<NTIMES; k++)
{
LIKWID_MARKER_START("copy");
// copy
#pragma omp for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
c[j] = a[j];
LIKWID_MARKER_STOP("copy");
if (k == NTIMES/2)
{
#pragma omp master // or single
LIKWID_MARKER_SWITCH;
}
}
}
LIKWID_MARKER_CLOSE;
From the first read, this code seems to be fine but it isn't when you think about multiple entities executing the code simultaneously. The master or single keywords just cause that the master or a single thread executes LIKWID_MARKER_SWITCH but there still might be another thread that is still accessing the hardware registers in LIKWID_MARKER_STOP("copy") or might even be already in the next LIKWID_MARKER_START("copy"). So we have to ensure that all threads are waiting before and after the LIKWID_MARKER_SWITCH call:
if (k == NTIMES/2)
{
#pragma omp barrier
#pragma omp master // or single
LIKWID_MARKER_SWITCH;
#pragma omp barrier
}
Now we can guarantee that all threads are are finished with their measurements and that no one starts the measurement while switching the events.
Generally, LIKWID_MARKER_SWITCH has quite a high overhead compared to the other MarkerAPI function. Setting up the hardware registers is commonly done in LIKWID_MARKER_INIT, hence in a part of the application which is commonly not performance critical. LIKWID_MARKER_SWITCH performs three operations in code regions close to performance-critical code: stopping the old event set, setting up the new event set and starting it. The recommendation is to avoid using LIKWID_MARKER_SWITCH and re-run the application once for each group. Please use LIKWID_MARKER_SWITCH only in parts of your application that are not performance critical.
If you want to steer the execution of your application with measurements from the MarkerAPI, you can get a thread's result by calling LIKWID_MARKER_GET(regionTag, nevents, events, time, count). The function arguments are used as input and output, so here is a more detailed description (for C/C++):
LIKWID_MARKER_GET( const char *regionTag, // Region name (just input)
int *nr_events, // Supply the length of the events array (input) and
// contains the amount of filled entries in the events array (output)
double *events, // Array for the event results. Must be already allocated and length
// must be given in nr_events (input/output)
double *time, // Runtime of the region (only output)
int *count) // Call count of the region (only output)
The functionality is quite simple, it checks in the thread's hash table for the region name and results all results.
Example code for the usage:
#define NUM_EVENTS 20
LIKWID_MARKER_INIT;
#pragma omp parallel
{
LIKWID_MARKER_REGISTER("copy");
}
#pragma omp parallel
{
double results[NUM_EVENTS];
int nr_events = NUM_EVENTS;
double time = 0.0;
int count = 0;
int tid = omp_get_thread_num()
LIKWID_MARKER_START("copy");
for (k=0; k<NTIMES; k++)
{
// copy
#pragma omp for
for (j=0; j<STREAM_ARRAY_SIZE; j++)
c[j] = a[j];
}
LIKWID_MARKER_STOP("copy");
// here nr_events = NUM_EVENTS
LIKWID_MARKER_GET("copy", &nr_events, (double*)results, &time, &count);
// here nr_events = events in the event set
printf("Thread %d: called region copy %d times, taking %f seconds\n", tid, count, time);
for (k = 0; k < nr_events; k++)
printf("Thread %d: Event %d: %f\n", tid, k, results[k]);
}
LIKWID_MARKER_CLOSE;
There is not much to think about when using LIKWID_MARKER_GET, just execute it by the thread you want the results from. If you call it in a serial region, you get the values of the master thread only!
In some cases it might be required to reset the results of a region. Examples are changed runtime settings like blocking factors or CPU frequencies based on measurement results (LIKWID_MARKER_GET). For these cases, the MarkerAPI contains the LIKWID_MARKER_RESET macro.
Here is an example code (Function code omitted):
LIKWID_MARKER_INIT;
#pragma omp parallel
{
LIKWID_MARKER_REGISTER("sum");
}
#pragma omp parallel
{
LIKWID_MARKER_START("sum");
for (k=0; k<NTIMES; k++)
{
vector_sum_normal(a, &sum);
}
LIKWID_MARKER_STOP("sum");
}
// Evaluate normal vector sum
if (redo_with_kahan)
{
#pragma omp parallel
{
LIKWID_MARKER_RESET("sum")
LIKWID_MARKER_START("sum");
for (k=0; k<NTIMES; k++)
{
vector_sum_kahan(a, &sum);
}
LIKWID_MARKER_STOP("sum");
}
}
LIKWID_MARKER_CLOSE;
This code does a vector summation (sum += A[i]) in a seperate function and if the evaluation tells to use Kahan summation instead, we reset the measurements and do the Kahan summation again using the same region name. Of course, likwid-perfctr has no clue about LIKWID_MARKER_RESET, so the "final" results printed by likwid-perfctr are those after the last LIKWID_MARKER_RESET.
When you have an application that does not perform any FP operations, like an array copy, but measure FLOPS_DP (and on some systems even FLOPS_SP as there is no differentiation between SP and DP) with the MarkerAPI, the regions will always show some scalar FP operations. This is a result of the MarkerAPI internal calculations. In every LIKWID_MARKER_START, the MarkerAPI calls perfmon_getResult() to get the current value as start value. At LIKWID_MARKER_STOP, the MarkerAPI calls perfmon_getResult() again and add the start/stop difference to the MarkerAPI internal value. As perfmon_getResult() returns the values as double, the MarkerAPI also uses double types internally. These calculations cause scalar double-precision FP operations which can be seen in the region results. With each event/counter in the eventset and the number of region calls, the value increases. The LIKWID library uses double to return also floating-point values like the energy in joules from the Intel/AMD RAPL interface.
This might happen with more recent Intel compilers. With the first OpenMP call, the Intel OpenMP runtime changes some memory allocator. This memory allocator does not like some operations. When calling LIKWID_MARKER_INIT after the first OpenMP call, this allocator causes the application to hang. Move LIKWID_MARKER_INIT in front of that call and it should work.
In case of libraries like the MKL and other, the threading might be hidden in the library. In order to measure functions like this, you have to call LIKWID_MARKER_START and LIKWID_MARKER_STOP yourself in a threaded way:
#pragma omp parallel
{
LIKWID_MARKER_START("parallel_f");
}
some_parallel_f() some_parallel_f()
#pragma omp parallel
{
LIKWID_MARKER_STOP("parallel_f");
}