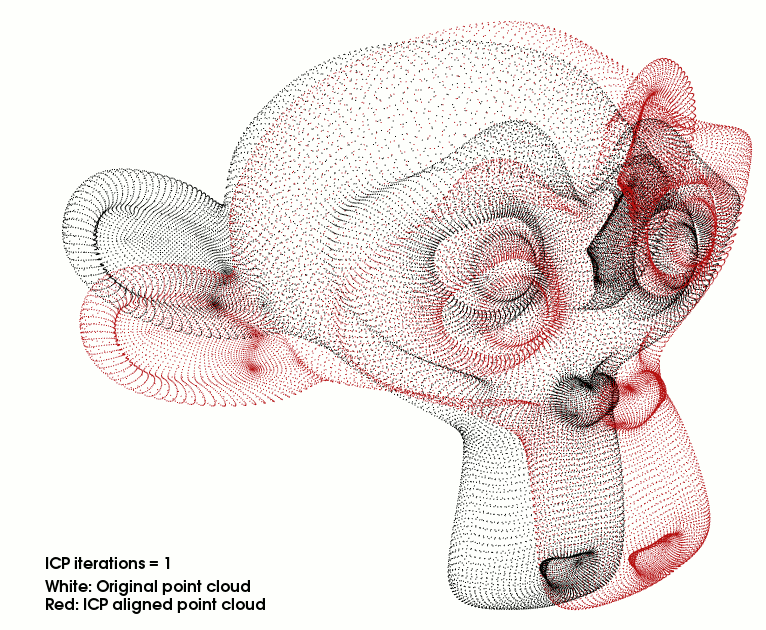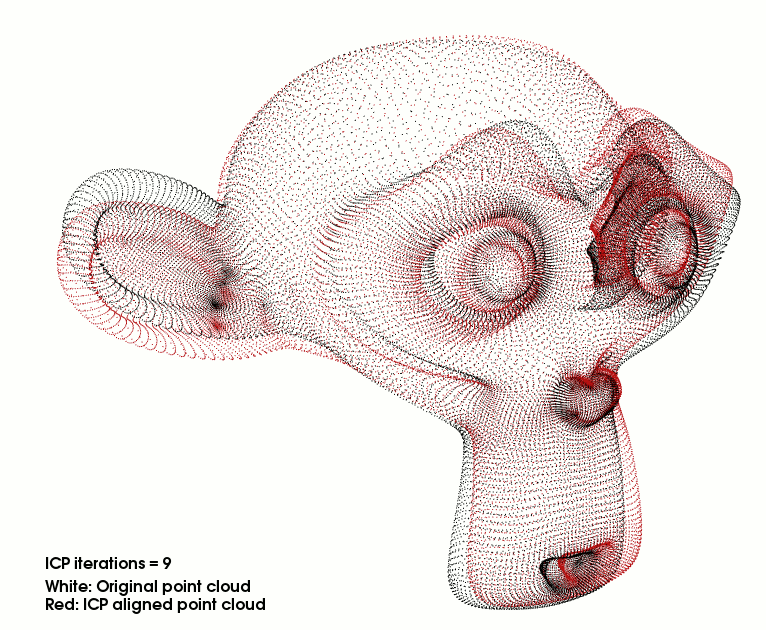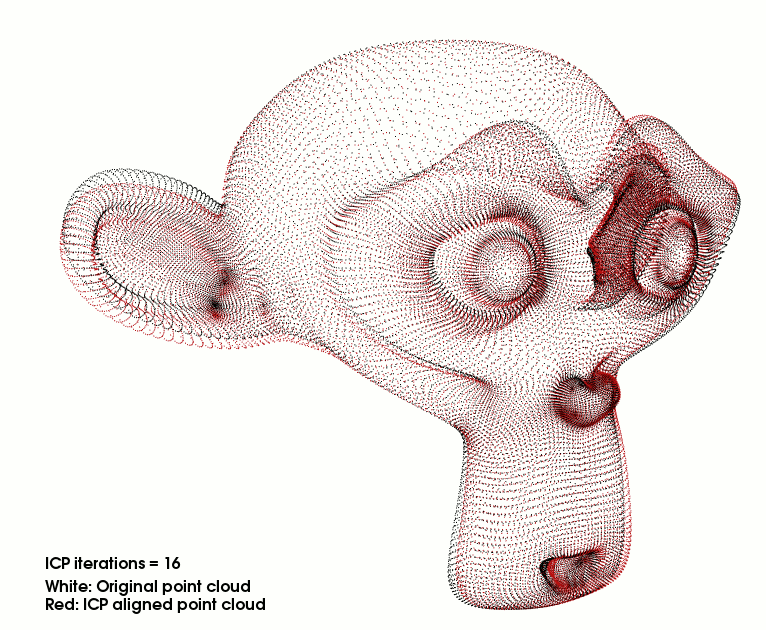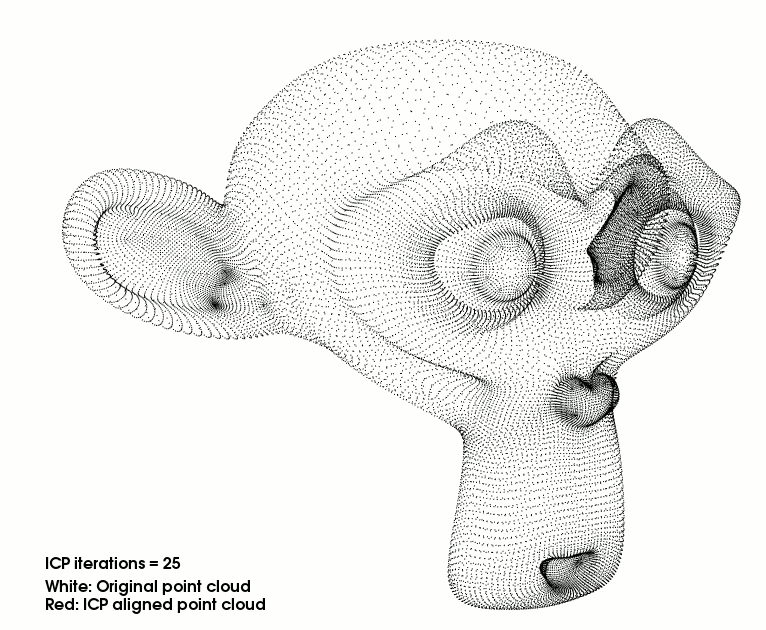
Iterative closest point GPU (CUDA) and CPU implementations with benchmarks.
Given two sets of points, a model and a scene, in each iteration the ICP algorithm tries to minimize the difference between the two of them so that the scene matches the model. Indeed, the model stays fixed while the algorithm transforms the scene using scaling, rotation and translation operations. It is particularly useful for aligning point clouds of different views of an object.
Make sure to have:
CMake(installation guide)
- Create a
builddirectory and move into it
sh$ mkdir build
sh$ cd build- Generate the Makefile with
CMake
sh$ cmake ..- Generate the 3 binaries
icp,icp-gpu,benchmarkin the root directory and go back to it
sh$ make
sh$ cd ..The commands above can be called by running the install.sh script:
./install.sh./icp [path_to_ref_cloud] [path_to_transform_cloud] [nb_max_iter]path_to_ref_cloudis the path to the model cloud.path_to_transform_cloudis the path to the scene cloud.nb_max_iteris the maximum number of iterations.
./icp [path_to_ref_cloud] [path_to_transform_cloud] [nb_max_iter]path_to_ref_cloudis the path to the model cloud.path_to_transform_cloudis the path to the scene cloud.nb_max_iteris the maximum number of iterations.
./bench 2> /dev/nullThis executable will launch benchmarks of cpu, gpu_naive and gpu_opti versions using the cow_ref and cow_tr1 files as input.
Here is an example of the output:
---------------------------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
---------------------------------------------------------------------------------------------------------------------------
BM_CPU_closest_matrix/cpu_closest_matrix/real_time 8726 ms 8725 ms 1 frame_rate=0.114602/s
BM_GPU_closest_matrix_naive/naive_gpu_closest_matrix/real_time 2935 ms 2839 ms 1 frame_rate=0.34067/s
BM_GPU_closest_matrix_opti/opti_gpu_closest_matrix/real_time 7.46 ms 7.46 ms 94 frame_rate=134.061/s
BM_CPU_find_alignment/cpu_find_alignment/real_time 14.9 ms 14.9 ms 47 frame_rate=67.1795/s
BM_GPU_find_alignment/gpu_find_alignment/real_time 5.52 ms 5.52 ms 127 frame_rate=181.182/s
BM_CPU_Compute_centroid/cpu_compute_centroid/real_time 1.33 ms 1.33 ms 530 frame_rate=754.372/s
BM_GPU_Compute_centroid/gpu_compute_centroid/real_time 2.38 ms 2.38 ms 294 frame_rate=420.297/s
BM_CPU_Err_compute/cpu_err_compute/real_time 8.44 ms 8.44 ms 83 frame_rate=118.474/s
BM_GPU_Err_compute/gpu_err_compute/real_time 1.16 ms 1.16 ms 604 frame_rate=862.65/s
BM_CPU_Err_compute_alignment/cpu_err_compute_alignment/real_time 8.54 ms 8.54 ms 82 frame_rate=117.059/s
BM_GPU_Err_compute/gpu_err_compute_alignment/real_time 1.75 ms 1.75 ms 400 frame_rate=571.742/s
BM_CPU_Find_corresponding/cpu_loop/real_time 61276 ms 61269 ms 1 frame_rate=0.0163197/s
BM_GPU_Find_corresponding_naive/naive_gpu_loop/real_time 18240 ms 18224 ms 1 frame_rate=0.0548258/s
BM_GPU_Find_corresponding_opti/opti_gpu_loop/real_time 107 ms 106 ms 7 frame_rate=9.36368/sTimeis the wall time. It measures how much time has passed (as if you were looking at the clock on your wall)CPUtime is how many seconds the CPU was busy.
You can change the input files of the benchmark by changing the Macros defined in src/bench.cc
#define REF_PATH "data_students/cow_ref.txt"
#define SCENE_PATH "data_students/cow_tr1.txt"The test above was run on a machine with the following specs:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 455.23.04 Driver Version: 455.23.04 CUDA Version: 11.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce GTX 1050 Off | 00000000:01:00.0 Off | N/A |
| 45% 31C P0 N/A / 75W | 0MiB / 1997MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 60
Model name: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
Stepping: 3
CPU MHz: 2738.692
CPU max MHz: 4000.0000
CPU min MHz: 800.0000
BogoMIPS: 7183.66
Virtualization: VT-x
L1d cache: 128 KiB
L1i cache: 128 KiB
L2 cache: 1 MiB
L3 cache: 8 MiB
NUMA node0 CPU(s): 0-7
You can improve the performances even more on another GPU device by changing the values of blocks' dimension and batches' size in src/GPU/compute.cu
#define MAX_THREADS_PER_BLOCK 256 // when using a 1D grid
#define SHARED_THREADS_PER_BLOCK 32 // when using a 2D grid
#define BATCH_SIZE 1280 // the batch size for operations requiering more space than what can the device offer1- S. Elhabian, Amal Farag, Aly Farag, “A Tutorial on Rigid Registration:Iterative Closest Point (ICP),” Louisville, KY: University of Louisville,March 2009 Link
- Yassir Ramdani: [email protected]
- Amine Heffar: [email protected]
- Mamoune El Habbari: [email protected]
- Rayane Amrouche: [email protected]
MIT License
Copyright (c) 2020 yassir RAMDANI
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.