Website fingerprinting is a method of Tor or VPN packet inspection that aims to collect enough features and information from individual sessions that could aid in identifying the activity of anonymized users.
Contributions and bug fixes are welcome.
For this experiment, Tor is required. It can be installed by running the following commands:
# For Debian or Ubuntu
sudo apt install tor lynx
# For Fedora
sudo yum install tor lynx
# For ArchLinux
sudo pacman -S tor torsocks lynxBy installing Tor we also get a program called torsocks; this program will be used to redirect traffic of common programs through the Tor network. For example, it can be run as follows:
# SSH through Tor.
torsocks ssh [email protected]
# CUrl through Tor.
torsocks curl -L http://httpbin.org/ip
# Etc...Firstly, activate a virtual environment:
cd path/to/website-fingerprinting
python -m venv $PWD/venv
source venv/bin/activateAnd then install all the dependencies:
pip install -r requirements.txtFor the data collection process two terminal windows in a side-by-side orientation are required, as this process is fairly manual. Also, it's advised to collect the fingerprints in a VM, in order to avoid caputring any unintended traffic. To listen on traffic there exists a script, namely capture.sh, which should be run in one of the terminals:
./pcaps/capture.sh duckduckgo.comOnce the listener is capturing traffic, on the next terminal run:
torsocks lynx https://duckduckgo.comOnce the website has finished loading, the capture process needs to be killed, along with the browser session (by hitting the q key twice). The process should be repeated several times for each web page so that there is enough data.
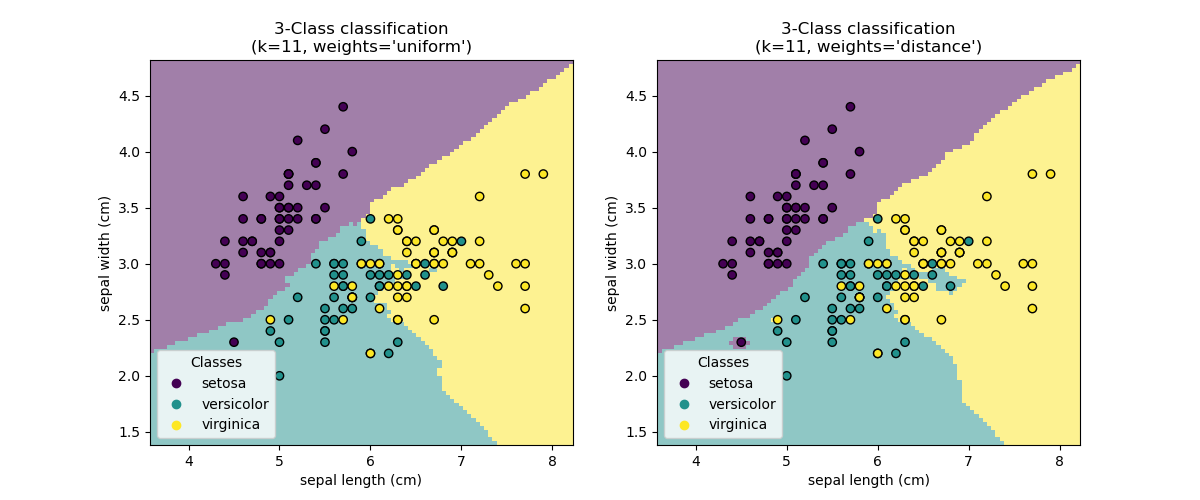
Scikit Learn was used to write a k Nearest Neighbors classifier, that would read the pcap files, as specified in the config.json file. config.json can be changed according to which webpages were targeted for training. The training script is gather_and_train.py.
# python predict.py [packet to classify]
python predict.py xyz.pcapOnce the training is done, and the classifier-nb.dmp is created, the predict.py script can be run with the pcap file as the sole argument. The script will load the classifier and attempt to identify which web page the traffic originated from.
It is worth noting that from each sample only the first 40 packets will be used to train a usable model and to run through the resulting classifier.

As can be seen in the screenshot above, the patterns of the packets of each website can be seen clearly on a 3D scale. The classifier visualizes the data in a similar way and gives us the most accurate result.
An interactive version of this graph can be found in the graphs folder.
This setup was created in order to research the topic of website fingerprinting and how easy it is to attempt to deanonymize users over Tor or VPNs. Traffic was captured and identified in a private setting and for purely academic purposes; the use of this source code is intended for those reasons only.
Traffic is never "clean", as the assumption was - for simplicity - in this research. However, if an entity has enough resources, the desired anonymized traffic can be isolated and fed into this simple classifier. This means that it is entirely possible to use a method like this to compromise anonymized users.
This research was inspired by the following research:
- Wang, T. and Goldberg, I. (2017). Website Fingerprinting. [online] Cse.ust.hk. Available at: http://web.archive.org/web/*/https://www.cse.ust.hk/~taow/wf/*.
- Wang, T. and Goldberg, I. (2013). Improved Website Fingerprinting on Tor. Cheriton School of Computer Science. Available at: http://www.cypherpunks.ca/~iang/pubs/webfingerprint-wpes.pdf
- Wang, T. (2015). Website Fingerprinting: Attacks and Defenses. University of Waterloo. Available at: https://uwspace.uwaterloo.ca/bitstream/handle/10012/10123/Wang_Tao.pdf