




🚀Check out the spotlight on Best of Streamlit!🔥 (Computer Vision Section)
- Table of Contents
- Motivation
- Instructions
- Getting Started
- Usage
- Demo
- Technologies Used
- Roadmap
- Contributing
- License
- Contact
- The project was primarily made to tackle a myth - "Deep Learning is only useful for Big Data".
|
|
 View source on GitHub View source on GitHub
|
|
Link: Deploy on colab in 2 mins

| YoloV3 | Retinanet |
|---|---|
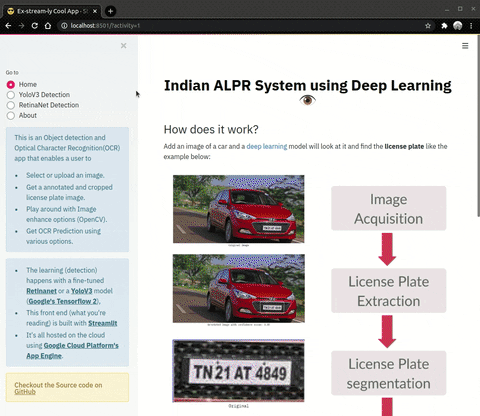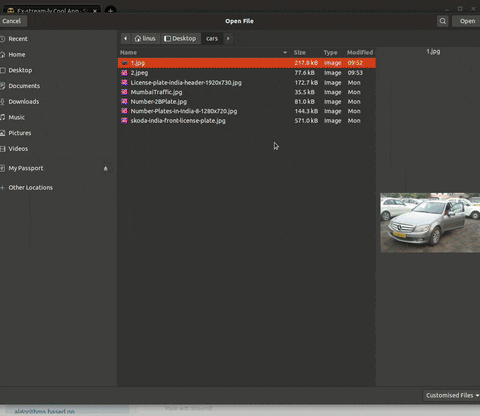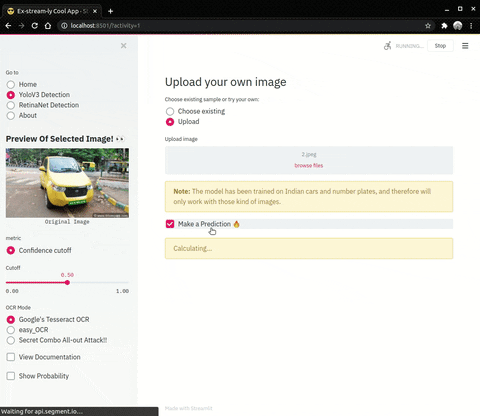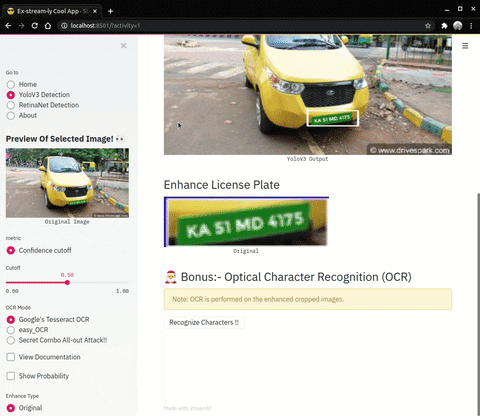 |
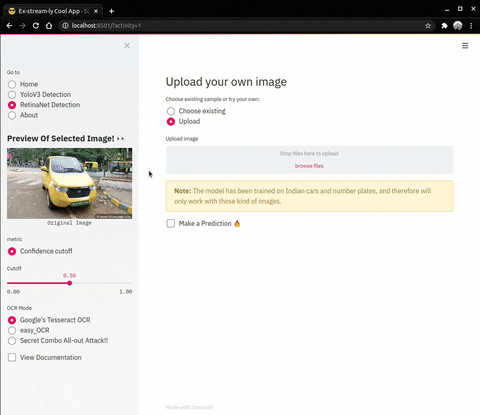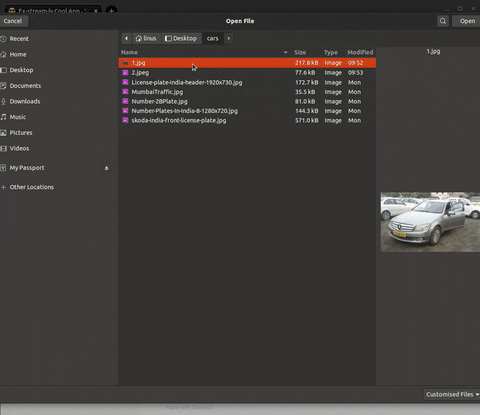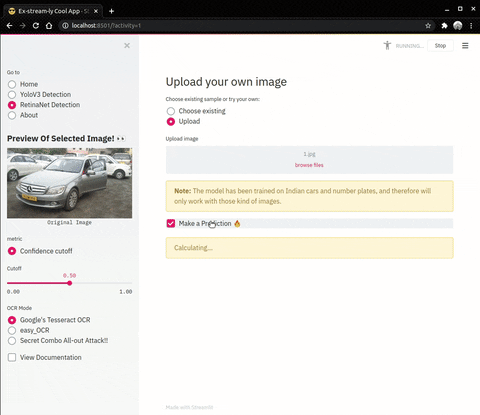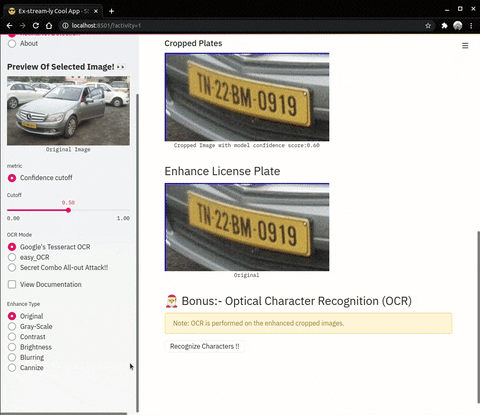 |
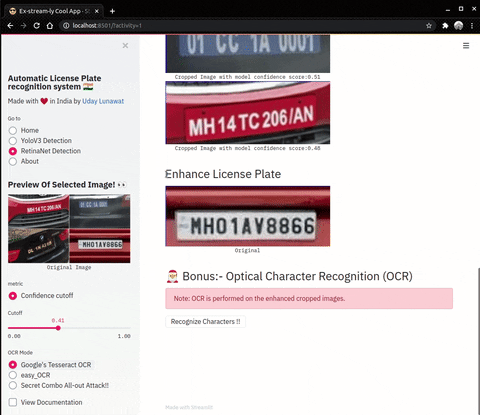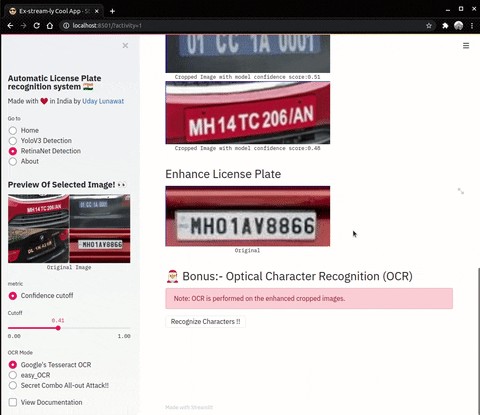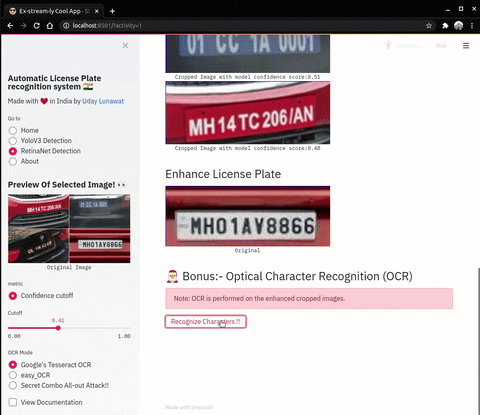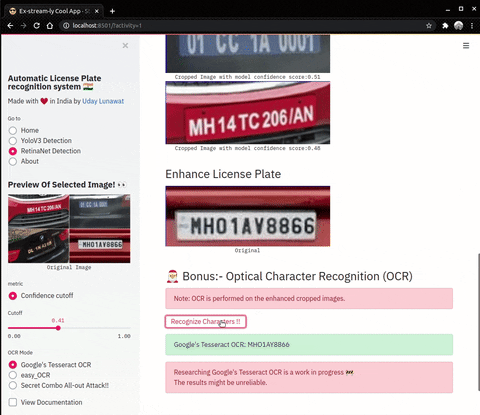
| Enhance Operations on cropped number plates | OCR (Optical Character Recognition) |
|---|---|
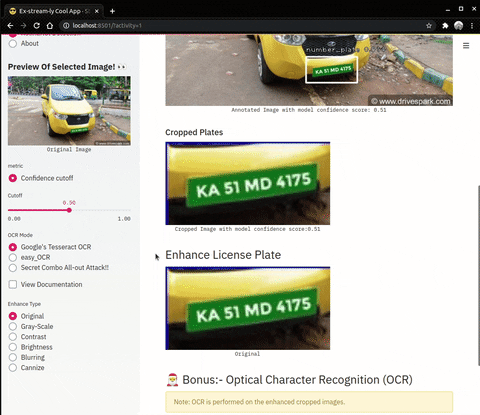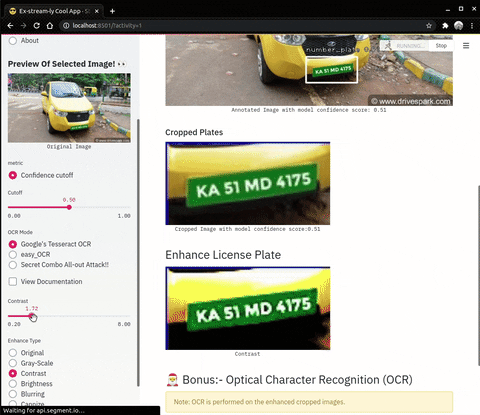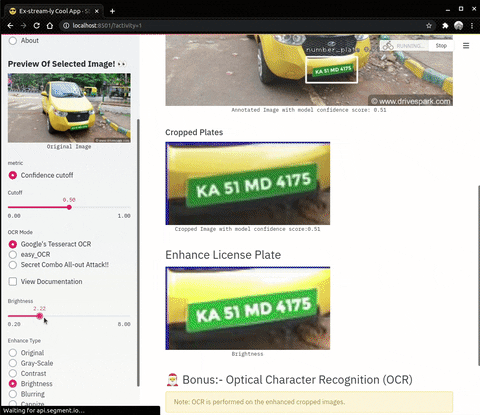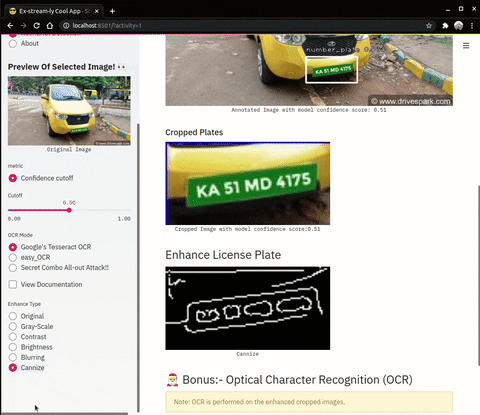 |
 |
├── banners <- Images for skill banner and project banner
│
├── cfg <- Configuration files
│
├── data
│ ├── sample_images <- Sample images for inference
│ ├── 0_raw <- The original, immutable data dump.
│ ├── 1_external <- Data from third party sources.
│ ├── 2_interim <- Intermediate data that has been transformed.
│ └── 3_processed <- The final, canonical data sets for modeling.
│
├── docs <- Streamlit / GitHub pages website
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description, e.g.
│ ` 1.0-jqp-initial-data-exploration`.
│
├── output
│ ├── features <- Fitted and serialized features
│ ├── models <- Trained and serialized models, model predictions, or model summaries
│ │ ├── snapshots <- Saving training snapshots.
│ │ ├── inference <- Converted trained model to an inference model.
│ │ └── TrainingOutput <- Output logs
│ └── reports <- Generated analyses as HTML, PDF, LaTeX, etc.
│ └── figures <- Generated graphics and figures to be used in reporting
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ │
│ ├── data <- Scripts to download or generate data
│ │ ├── make_dataset.py
│ │ ├── generate_pascalvoc.py
│ │ ├── generate_annotations.py
│ │ └── preprocess.py
│ │
│ ├── features <- Scripts to turn raw data into features for modeling
│ │ └── build_features.py
│ │
│ ├── models <- Scripts to train models and then use trained models to make
│ │ │ predictions
│ │ ├── predict_model.py
│ │ └── train_model.py
│ │
│ └── visualization <- Scripts to create exploratory and results oriented visualizations
│ └── visualize.py
├── utils <- Utility scripts for Streamlit, yolo, retinanet etc.
├── serve <- HTTP API for serving predictions using Streamlit
│ ├── Dockerfile <- Dockerfile for HTTP API
│ ├── Pipfile <- The Pipfile for reproducing the serving environment
│ └── app.py <- The entry point of the HTTP API using Streamlit app
│
├── .dockerignore <- Docker ignore
├── .gitignore <- GitHub's excellent Python .gitignore customized for this project
├── app.yaml <- contains configuration that is applied to each container started
│ for that service
├── config.py <- Global configuration variables
├── LICENSE <- Your project's license.
├── Makefile <- Makefile with commands like `make data` or `make train`
├── README.md <- The top-level README for developers using this project.
├── tox.ini <- tox file with settings for running tox; see tox.readthedocs.io
├── requirements.txt <- The requirements file for reproducing the analysis environment, e.g.
│ generated with `pip freeze > requirements.txt`
└── setup.py <- makes project pip installable (pip install -e .) so src can be imported
- Convert the app to run without any internet connection.
- Work with video detection
- Try AWS Textrac OCR, SSD and R-CNN
- Try with larger dataset Google's Open Image Dataset v6
If you find a bug (the website couldn't handle the query and / or gave undesired results), kindly open an issue here by including your search query and the expected result.
If you'd like to request a new function, feel free to do so by opening an issue here. Please include sample queries and their corresponding results.


 |
|---|
| Uday Lunawat |
Contributions are what make the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are greatly appreciated.
- Fork the Project
- Create your Feature Branch (
git checkout -b feature/AmazingFeature) - Commit your Changes (
git commit -m 'Add some AmazingFeature') - Push to the Branch (
git push origin feature/AmazingFeature) - Open a Pull Request
Copyright 2020 Uday Lunawat
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
- README inspired by Rohit Swami!
- Cookie Cutter Data Science
Show some ❤️ by starring some of the repositories!
Made with 💙 for India