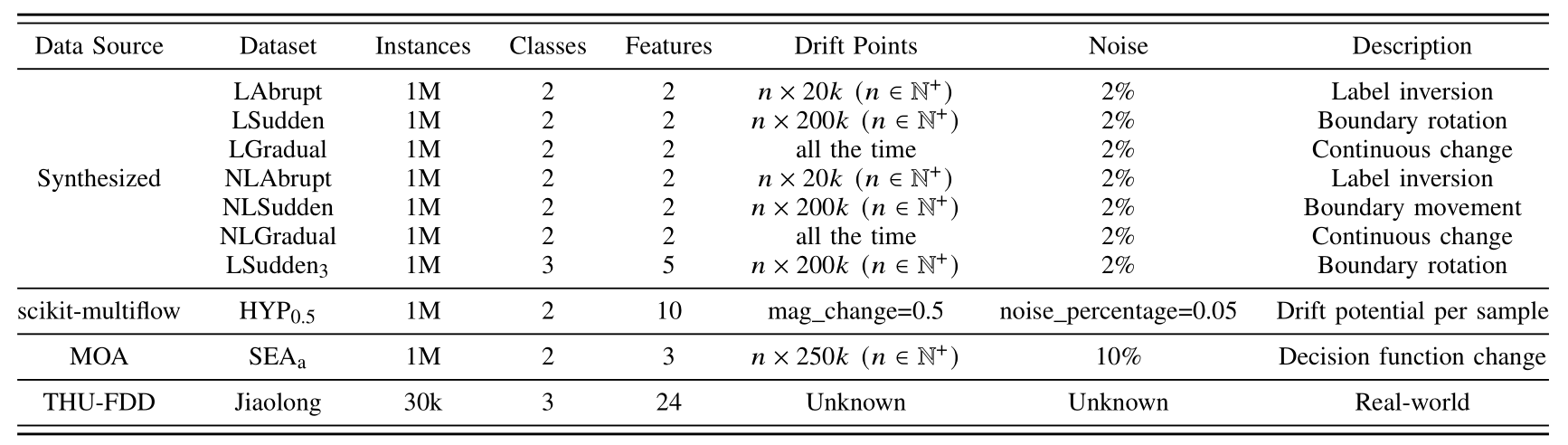
- Data distribution display:
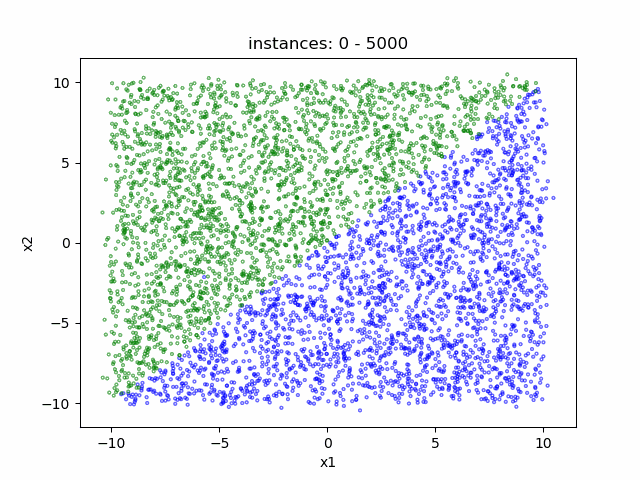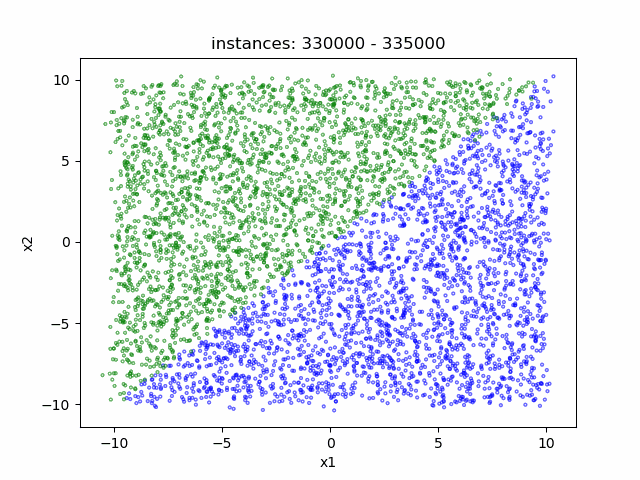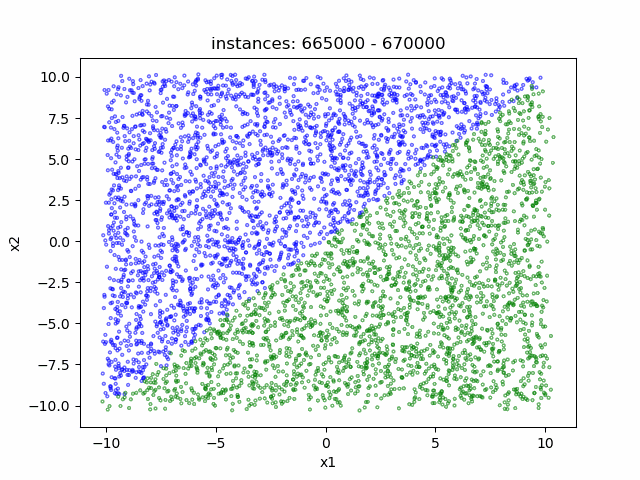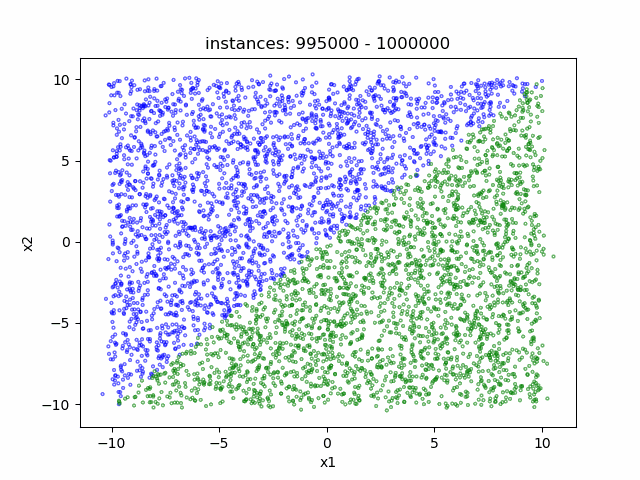


(a) LAbrupt (b) LSudden_3 (c) LGradual



(a) NLAbrupt (b) NLSudden (c) NLGradual
- HYP_05 (from scikit-multiflow):
import csv
from skmultiflow.data import HyperplaneGenerator
import numpy as np
stream = HyperplaneGenerator(mag_change=0.5)
X, y = stream.next_sample(1000000)
with open('HYP_05.csv', 'w', newline='') as fp:
writer = csv.writer(fp)
writer.writerows(np.column_stack((X, y)))
- SEA_a (from MOA):
WriteStreamToARFFFile -s (ConceptDriftStream -s generators.SEAGenerator -d (ConceptDriftStream -s (generators.SEAGenerator -f 2) -d (ConceptDriftStream -s generators.SEAGenerator -d (generators.SEAGenerator -f 4) -p 250000 -w 50) -p 250000 -w 50) -p 250000 -w 50) -f (SEA_a.arff) -m 1000000
Please refer to
https://github.com/THUFDD/JiaolongDSMS_datasets
Concept drift describes unforeseeable changes in the underlying distribution of streaming data over time[1]. Concept drift problem exists in many real-world situations, such as sensor drift and the change of operating mode[2][3]. Detecting concept drift timely and accurately is of great significance for judging system state and providing decision suggestions[4]. In order to better test and evaluate the performance of concept drift detection algorithm, we have made some datasets with known drift types and drift time points, hoping to help the development of concept drift detection.
- If you want to use the datasets in the project, you can download them directly and import them using the pandas library.
- Example:
import pandas as pd
data = pd.read_csv('xxxxxx/nonlinear_gradual_chocolaterotation_noise_and_redunce.csv')
data = data.values
X = data[:, 0 : 5]
Y = data[:, 5]
- Or you can download DatasetsInput.py, and then import the class, as shown in DatasetsInput_main.py.(Recommended)
- Example:
from DatasetsInput import Datasets
Data = Datasets()
X, Y = Data.CNNS_Nonlinear_Gradual_ChocolateRotation()
- If you want to regenerate the dataset and import it directly, you can download DataStreamGenerator.py and put it under the file where your code is located, and then import the class.
- Example:
from DataStreamGenerator import DataStreamGenerator
C = DataStreamGenerator(class_count=2, attribute_count=2, sample_count=100000, noise=True, redunce_variable=True)
X, Y = C.Nonlinear_Sudden_RollingTorus(plot=True, save=True)
- If you want to modify the source code, you can download it and do it in DataStreamGenerator.py.
We have made four categories of datasets, including linear, rotating cake, rotating chocolate and rolling torus. All of them contain four types of drifts: Abrupt, Sudden, Gradual and Recurrent. Users can choose whether to draw distribution of samples in real time, save pictures, and make sample change videos. Users can choose whether to add noise or redundant variables as well. See the picture below for a more detailed introduction. Note that the dataset name in the following figure is also the name of the intra class function.

In the dataset Linear, the decision boundary is a straight line. We simulate the change of the decision boundary through the rotation of the straight line. Users can freely select the rotation axis within the range of [-10, 10]×[-10, 10].
- Data distribution display:
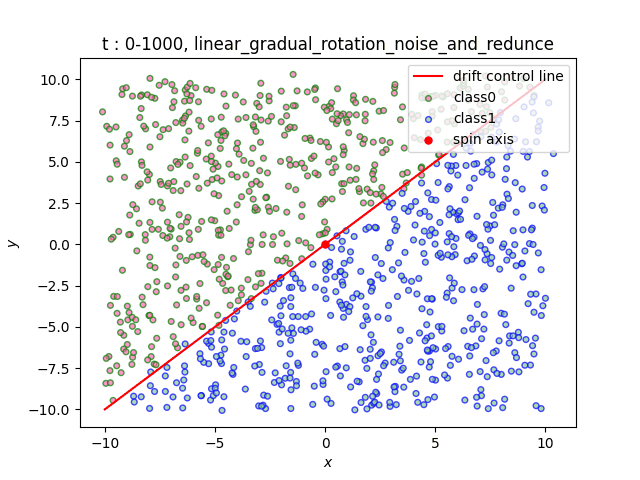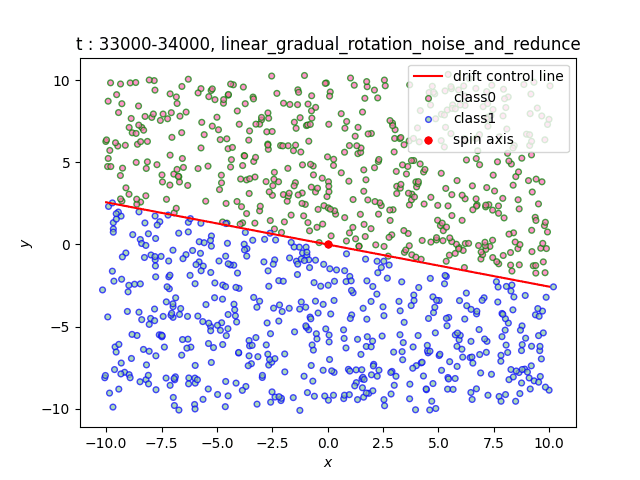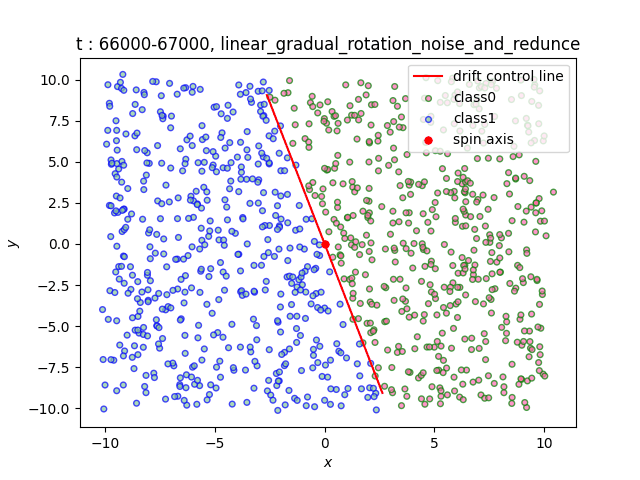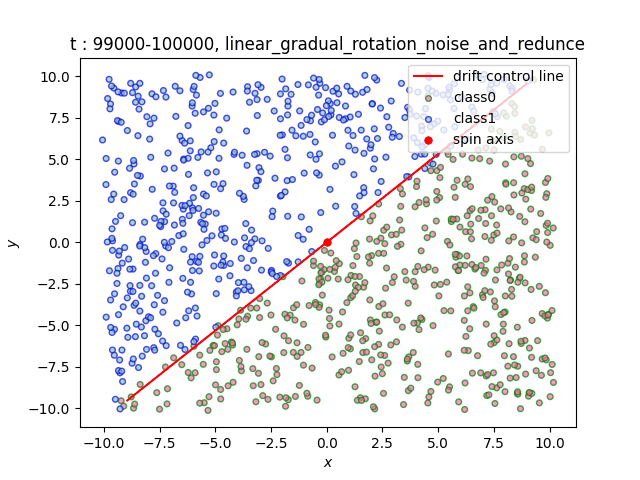

(a)Gradual (b)Sudden


(c)Recurrent (d)Abrupt
In the dataset CakeRotation, samples with odd angle area belong to one class, while samples with even angle area belong to another class. We simulate concept drift by rotating the disk, and the range of the angle area will change during the rotation. If you need data sets of multiple categories, you can achieve it by using modulus instead of odd and even numbers on this basis[5].
- Data distribution display:
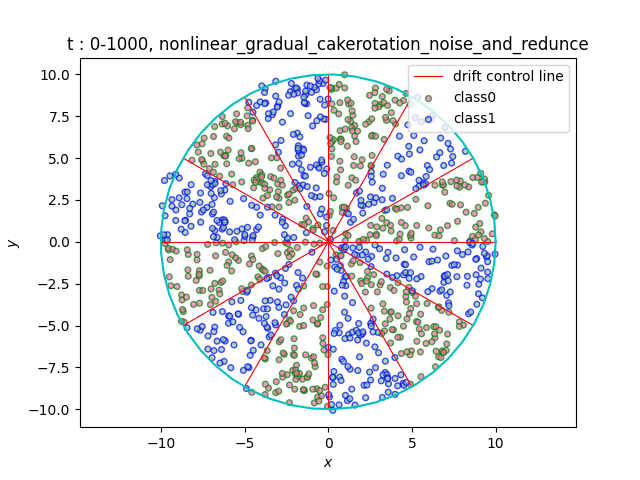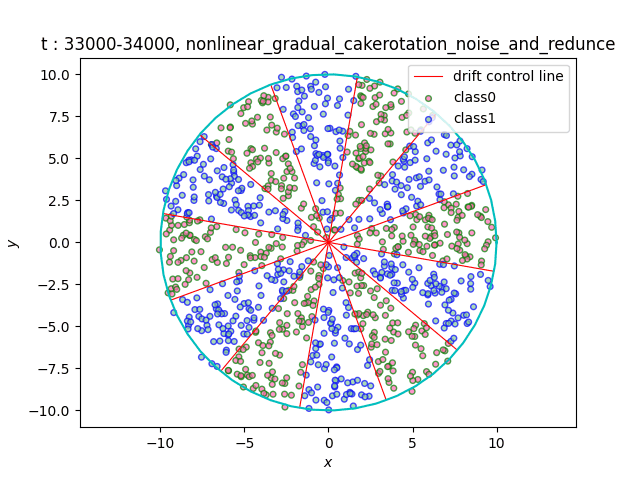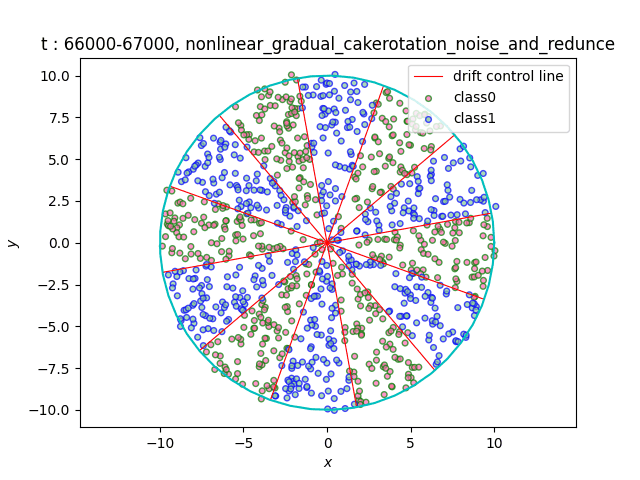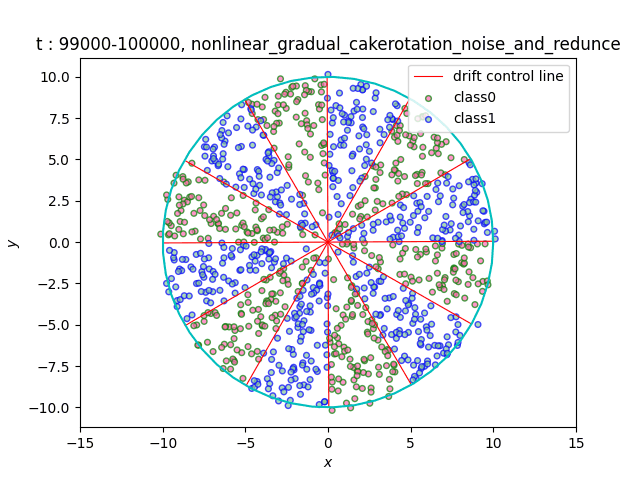
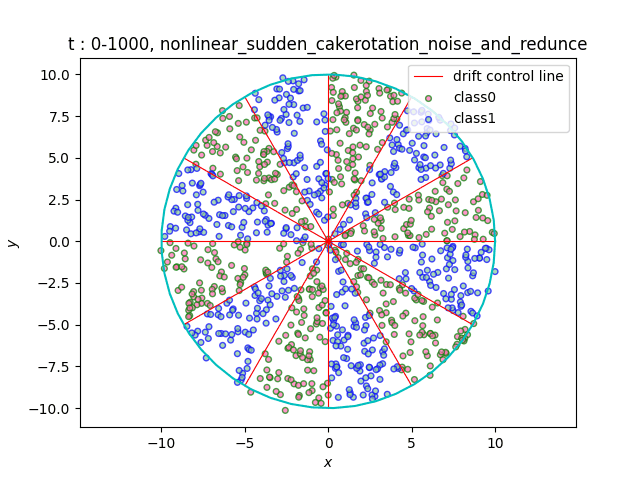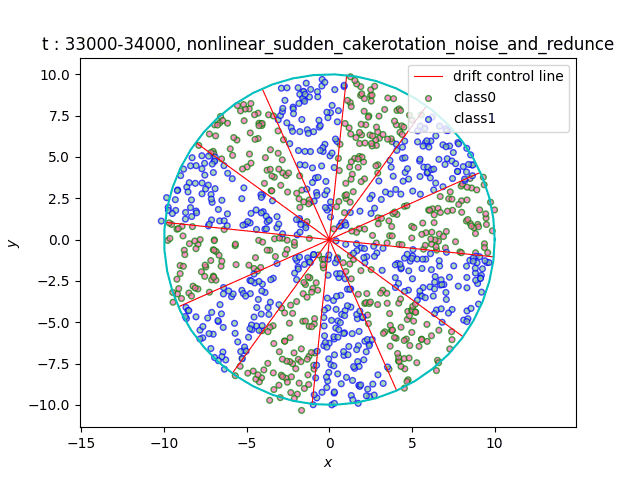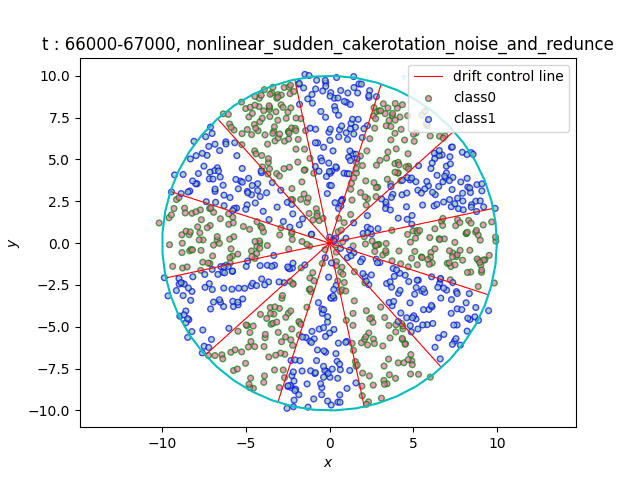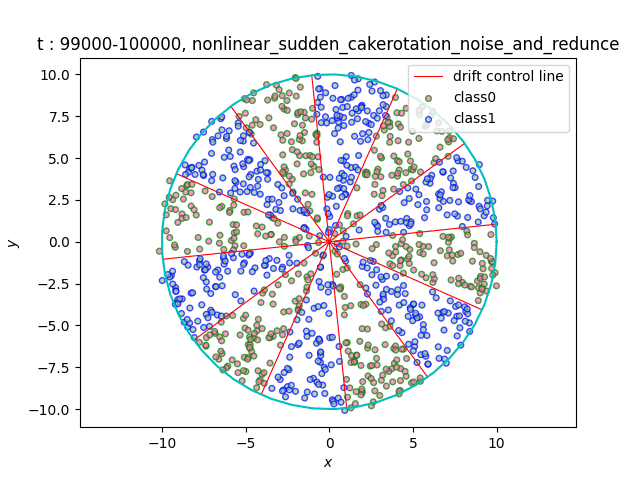
(a)Gradual (b)Sudden


(c)Recurrent (d)Abrupt
In the dataset ChocolateRotation, samples with odd x+y area belong to one class, while samples with even angle area belong to another class. We simulate concept drift by rotating the chocolate plate, and use the rotation matrix to calculate the coordinates of the samples in the new coordinate system and reclassify them. If you need data sets of multiple categories, you can achieve it by using modulus instead of odd and even numbers on this basis.
- Data distribution display:


(a)Gradual (b)Sudden


(c)Recurrent (d)Abrupt
In the dataset RollingTorus, we set two torus of the same size close together, and the samples in different torus belong to different classes. We let the third torus roll over at a constant speed, and the samples overlapping the first two tori will become the opposite category. If you need a dataset with unbalanced number of category samples, you can adjust the initial torus radius to achieve[6].
- Data distribution display:


(a)Gradual (b)Sudden

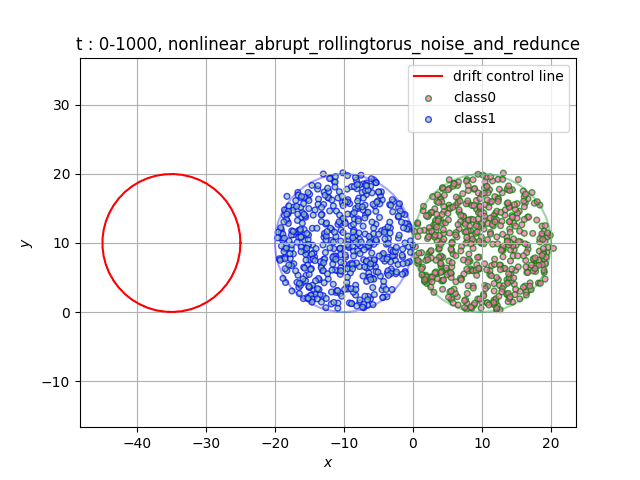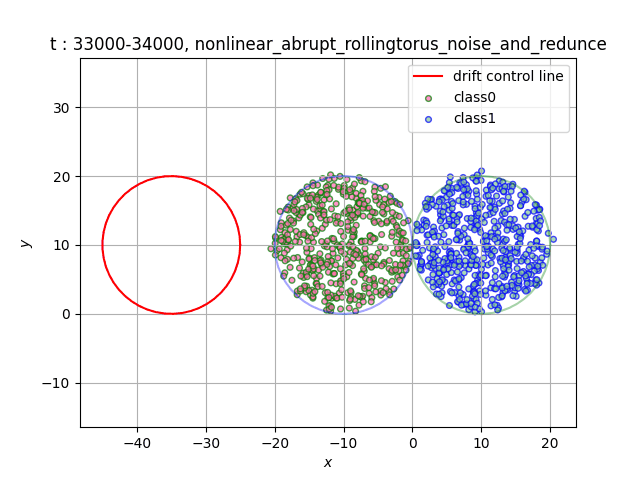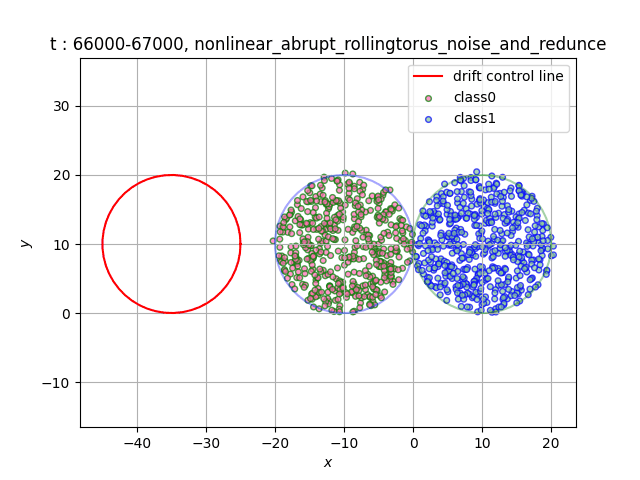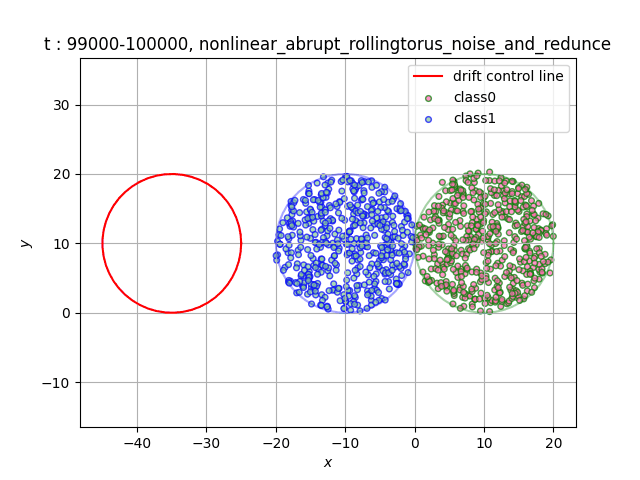
(c)Recurrent (d)Abrupt
Concretely, they have generated 20 diverse synthetic datasets (10 abrupt and 10 gradual) by using several stream generators and functions, and with a different number of features and noise.
They exhibit 4 concepts and 3 drifts at time steps 10000, 20000, and 30000 in the case of abrupt datasets, and at time steps 9500, 20000, and 30500 in the case of gradual ones. In the latter case, the width of the drift is 1000. All of them have 40000 instances in total. Next, the details of the datasets:
– With Sine generator: it is ruled by a sequence of classification functions. Sine A refers to abrupt cases and Sine G to gradual ones. In the case of Sine F1, the order of the functions is SINE1-reversed SINE1-SINE2-reversed SINE2. For Sine F2 the order is reversed SINE2-SINE2-reversed SINE1-SINE1. Therefore, Sine stream generator provides 4 different datasets: Sine A F1, Sine A F2, Sine G F1, and Sine G F2. They consists of 2 numerical features, a balanced binary class, and without noise.
– With Random Tree generator: it is ruled by a sequence of tree random state functions. The parameters max tree depth, min leaf depth, and fraction leaves per level were set to 6, 3, and 0.15 respectively. RT A refers to abrupt cases and RT G to gradual ones. In the case of RT F1, the order of the functions is 8873-9856-7896-2563. For RT F2 the order is reversed 2563-7896-9856-8873. Therefore, Random Tree stream generator provides 4 different datasets: RT A F1, RT A F2, RT G F1, and RT G F2. They consists of 2 numerical features, a balanced binary class, and without noise.
– With Mixed generator: it is ruled by a sequence of classification functions. Mixed A refers to abrupt cases and Mixed G to gradual ones. In the case of Mixed F1, the order of the functions is 0-1-0-1. For Mixed F2 the order is reversed 1-0-1-0. Therefore, Mixed stream generator provides 4 different datasets: Mixed A F1, Mixed A F2, Mixed G F1, and Mixed G F2. They consists of 4 numerical features, a balanced binary class, and without noise.
– With Sea generator: it is ruled by a sequence of classification functions. Sea A refers to abrupt cases and Sea G to gradual ones. In the case of Sea F1, the order of the functions is 0-1-2-3. For Sea F2 the order is reversed 3-2-1-0. Therefore, Sea stream generator provides 4 different datasets: Sea A F1, Sea A F2, Sea G F1, and Sea G F2. They consists of 3 numerical features, a balanced binary class, and with the probability that noise will happen in the generation of 0.2 (probability range between 0 and 1).
– With Stagger generator: it is ruled by a sequence of classification functions. Stagger A refers to abrupt cases and Stagger G to gradual ones. In the case of Stagger F1, the order of the functions is 0-1-2-0. For Stagger F2 the order is reversed 2-1-0-2. Therefore, Stagger stream generator provides 4 different datasets: Stagger A F1, Stagger A F2, Stagger G F1, and Stagger G F2. They consists of 3 numerical features, a balanced binary class, and without noise.
- We are from the research group of Prof. Xiao He, Department of Automation, Tsinghua University.
- Welcome to discuss and put forward valuable suggestions. Email: [email protected], [email protected].
If you find these datasets useful, please cite the original paper:
@article{hu2024cadm,
title={CADM $+ $: Confusion-Based Learning Framework With Drift Detection and Adaptation for Real-Time Safety Assessment},
author={Hu, Songqiao and Liu, Zeyi and Li, Minyue and He, Xiao},
journal={IEEE Transactions on Neural Networks and Learning Systems},
year={2024},
publisher={IEEE}
}
@INPROCEEDINGS{10295743,
author={Liu, Zeyi and Hu, Songqiao and He, Xiao},
booktitle={2023 CAA Symposium on Fault Detection, Supervision and Safety for Technical Processes (SAFEPROCESS)},
title={Real-time Safety Assessment of Dynamic Systems in Non-stationary Environments: A Review of Methods and Techniques},
year={2023},
volume={},
number={},
pages={1-6},
doi={10.1109/SAFEPROCESS58597.2023.10295743}}
[1]Lu J, Liu A, Dong F, et al. Learning under concept drift: A review[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 31(12): 2346-2363.
[2] Liu Z, Zhang Y, Ding Z, et al. “An Online Active Broad Learning Approach for Real-Time Safety Assessment of Dynamic Systems in Nonstationary Environments,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
[3] Hoens T R, Polikar R, Chawla N V. “Learning from streaming data
with concept drift and imbalance: an overview,” Progress in Artificial
Intelligence, 2012, 1(1): 89-101.
[4] Liu A, Song Y, Zhang G, et al. “Regional concept drift detection
and density synchronized drift adaptation,” IJCAI International Joint
Conference on Artificial Intelligence. 2017.
[5] Korycki Ł, Krawczyk B. “Concept drift detection from multi-class
imbalanced data streams,” 2021 IEEE 37th International Conference on
Data Engineering (ICDE). IEEE, 2021: 1068-1079.
[6] Wang S, Minku L L, Yao X. “A systematic study of online class
imbalance learning with concept drift,” IEEE transactions on neural
networks and learning systems, 2018, 29(10): 4802-4821.
[7]López Lobo, Jesús. "Synthetic datasets for concept drift detection purposes." Harv. Dataverse (2020). https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/5OWRGB.