
DataLinguist† is a Clojure wrapper for the Natural Language Processing behemoth, Stanford CoreNLP. The goal of the project is to support an NLP workflow in a data-oriented style, integrating relevant Clojure protocols and libraries.
Most Lisp dialects facilitate interactive development centred around a REPL. Clojure - being both a JVM language and a data-oriented one - is perfectly suited for wrapping Stanford CoreNLP's fairly opaque language processing tools. The dizzying heights of Java class hierarchies are brought down to eye level and repackaged into more accessible functions inside a few Clojure namespaces. At the same time, the API is streamlined with most of the obvious cruft left out.
† The name is a play on "datalingvist" - the Danish word for "computational linguist" - and Clojure's love of all things data. As a sidenote, the Danish translation of "computer scientist" is actually "datalog"!
Major releases are available on Clojars—look there for instructions!
The library can also be included as a deps.edn dependency by referencing a specific commit SHA in this repository:
simongray/datalinguist {:git/url "https://github.com/simongray/datalinguist"
:sha "..."}DataLinguist requires a language model to access the full feature set. Several precompiled models are available through Maven Central††. These models follow the same versioning scheme as CoreNLP itself. See the official CoreNLP documentation for more on language models.
In addition to adding DataLinguist itself as a project dependency, you should therefore also make sure to add any language models you might need:
;; Currently available precompiled language models in deps.edn format
edu.stanford.nlp/stanford-corenlp$models {:mvn/version "4.4.0"}
edu.stanford.nlp/stanford-corenlp$models-arabic {:mvn/version "4.4.0"}
edu.stanford.nlp/stanford-corenlp$models-chinese {:mvn/version "4.4.0"}
edu.stanford.nlp/stanford-corenlp$models-english {:mvn/version "4.4.0"}
edu.stanford.nlp/stanford-corenlp$models-english-kbp {:mvn/version "4.4.0"}
edu.stanford.nlp/stanford-corenlp$models-french {:mvn/version "4.4.0"}
edu.stanford.nlp/stanford-corenlp$models-german {:mvn/version "4.4.0"}
edu.stanford.nlp/stanford-corenlp$models-hungarian {:mvn/version "4.4.0"}
edu.stanford.nlp/stanford-corenlp$models-italian {:mvn/version "4.4.0"}
edu.stanford.nlp/stanford-corenlp$models-spanish {:mvn/version "4.4.0"}Note that several unofficial language models also exist!
You will likely also need to increase the amount of memory allotted to your JVM process, e.g. for Chinese I make sure to add :jvm-opts ["-Xmx4G"] to my deps.edn file.
†† Stanford can sometimes be bit slow when it comes to uploading more recent versions of CoreNLP to Maven Central.
If you just want to get going quick, refer to the deps.edn example project.
DataLinguist has a very simple API for executing various NLP operations. To perform any language processing task you will generally need to 1. build an annotation pipeline, 2. annotate some text, 3. extract some of these annotations for analysis, and (optionally) 4. datafy the annotations for more idiomatic use in Clojure.
Before anything can happen, we need to construct an NLP pipeline. Pipelines are built using plain Clojure data structures which are converted into properties:
(require '[dk.simongray.datalinguist :refer :all])
;; Create a closure around a CoreNLP pipeline.
;; By default, a CoreNLP pipeline will annotate text in the English language.
(def nlp
(->pipeline {:annotators ["depparse" "lemma"]}))This will create a pipeline with all of the annotators required for dependency parsing and lemmatisation.
If the resulting pipeline function is called on a piece of text it will output annotated data.
(def annotated-text
(nlp "This is a piece of text. This is another one."))This data consists of various Java objects and takes the shape of a tree. The data can then be queried using the annotation functions.
In our example we built a pipeline that could do both dependency parsing and lemmatisation, so let's extract a dependency graph of the second sentence:
(->> annotated-text sentences second dependency-graph)
;=>
;#object[edu.stanford.nlp.semgraph.SemanticGraph
; 0x79d17876
; "-> one/CD (root)
; -> This/DT (nsubj)
; -> is/VBZ (cop)
; -> another/DT (det)
; -> ./. (punct)
; "]We can also annotate another piece of text and return the lemmas:
(->> (nlp "She has beaten him before.")
tokens
lemma)
;=> ("she" "have" "beat" "he" "before" ".")While lemmas are technically only attached to tokens in CoreNLP (and dependency graphs to sentences), the DataLinguist functions do allow you to skip ahead in most cases, i.e. we could have written:
(lemma (nlp "She has beaten him before."))
;=> ("she" "have" "beat" "he" "before" ".")NOTE: while this is really convenient behaviour to have in the REPL - particularly if you have not yet memorised the somewhat arbitrary annotation hierarchy used in CoreNLP - it does come with one caveat: the return type can vary unexpectedly!
For example,
(text :plain (nlp "..."))"will return a string, while(text :true-case (nlp "..."))"will return a sequence of strings. The reason for this is simple: text annotations exist at both the document, sentence, and token level, while true-case text annotations only exist at the token level. If you don't want any surprises, make sure to explicitly navigate down the annotation hierarchy usingsentences,tokens, and other relevant functions.
If at any point we grow tired of accessing Java objects using the annotation functions, we can call recur-datafy and get plain Clojure data structures:
(-> annotated-text tokens second recur-datafy)
;=>
;{:token-end 2,
; :original-text "is",
; :index 2,
; :part-of-speech "VBZ",
; :token-begin 1,
; :value "is",
; :sentence-index 0,
; :lemma "be",
; :newline? false,
; :character-offset-begin 5,
; :after " ",
; :character-offset-end 7,
; :before " ",
; :text "is"}These data structures expose the underlying annotation maps of the CoreNLP objects. The keys are based on what set of annotators you have enabled in your pipeline.
NOTE: the regular
datafyfunction can of course be used as well, butrecur-datafywill always datafy the entire tree.
Apart from wrapping the features of Stanford CoreNLP, DataLinguist also integrates with common Clojure libraries and workflows.
The pipeline's annotated output data extends the Datafiable protocol introduced in Clojure 1.10 and can therefore be navigated using the REBL.
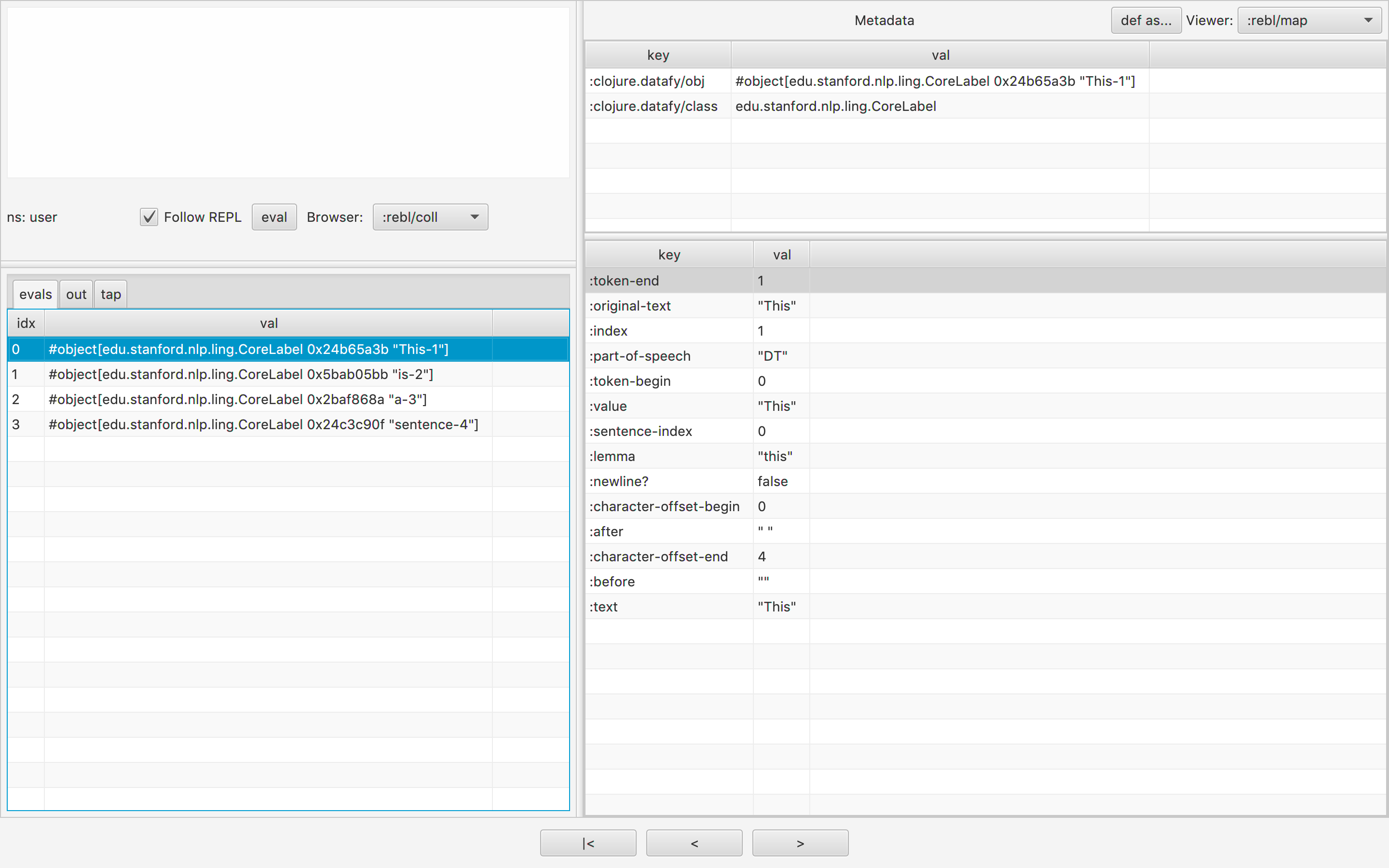
Within the REBL, text annotations can be visualised and analysed interactively.
The dependency graphs support the Graph and DiGraph protocols from Loom and associated algorithms.
Dependency graphs can also be visualised using a modified version of the view function from Loom (requires Graphiz installed).
(require '[dk.simongray.datalinguist.loom.io :refer [view]])
(view (->> (nlp "The dependencies of this sentence have been visualised using Graphviz.")
sentences
dependency-graph
first))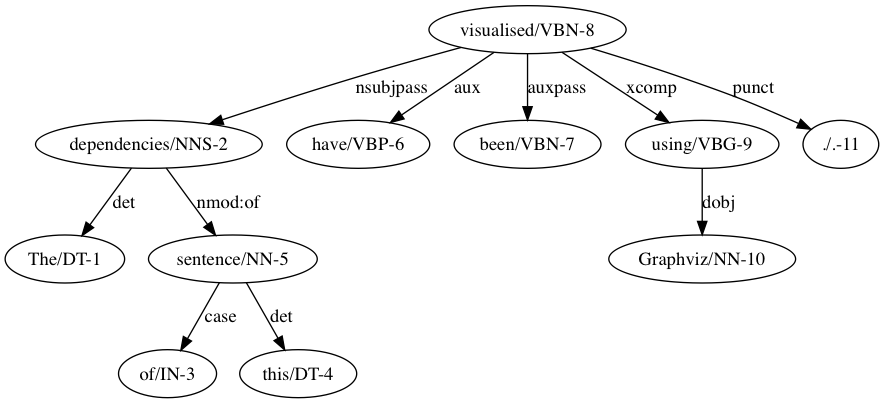
Some CoreNLP annotators allow you to extract triples from text. You can use the dk.simongray.datalinguist.triple/triple->datalog function to convert these triples directly into Datomic-style EaV tuples. In fact, this is the way DataLinguist datafies any CoreNLP triple objects.
Assuming a pipeline containing the openie annotator:
(->> (nlp (str "Donald Trump was elected president in 2016. "
"In 2021, Joe Biden will succeed Donald Trump as president.")
triples
recur-datafy))The above code might then return the following Datalog-like tuples:
[[["Donald Trump" :was-elected-president-in "2016"]
["Donald Trump" :was-elected "president"]]
[["Joe Biden" :will-succeed-donald-trump-as "president"]
["Joe Biden" :will-succeed-donald-trump-in "2021"]
["Joe Biden" :will-succeed "Donald Trump"]]]You can already perform most common NLP tasks by following the 3-part process described above. However, CoreNLP is a huge undertaking that has amassed many NLP tools throughout the years, usually by integrating the products of various Stanford research projects. Some of these tools are well maintained, some not so much. Some play well with the other parts of CoreNLP, some do not. It is the goal of this project to wrap most of them, with a few exceptions:
- Classes and methods that are merely implementation details are not wrapped.
- Mutating code has generally been left out. This is not idiomatic in Clojure.
- Easily replicated convenience methods have been left out. The Clojure standard library is better suited for this.
- Code dealing with training new language models has been left out. For now, DataLinguist is focused on wrapping the language analysis functionality.
Please refer to this overview for more on the CoreNLP package structure and what's been wrapped in DataLinguist.
The class files in Stanford CoreNLP contain the primary documentation for the three supported pattern languages:
- TokensRegex documentation is found in the TokenSequencePattern class.
- Tregex documentation is found in the TregexPattern class.
- Semgrex documentation is found in the SemgrexPattern class.
DataLinguist is licensed under the GPL v3 or later. This copy-left licence is a continuation of Stanford's own licensing terms for CoreNLP:
The full Stanford CoreNLP is licensed under the GNU General Public License v3 or later. More precisely, all the Stanford NLP code is GPL v2+, but CoreNLP uses some Apache-licensed libraries, and so our understanding is that the the composite is correctly licensed as v3+. You can run almost all of CoreNLP under GPL v2; you simply need to omit the time-related libraries, and then you lose the functionality of SUTime. Note that the license is the full GPL, which allows many free uses, but not its use in proprietary software which is distributed to others.
Since CoreNLP is an academic project, you should also cite Stanford when using the software. Additionally, you are encouraged to reference DataLinguist and provide a link to the simongray/DataLinguist Git repository.