Official Repo for the paper: "Interpreting Vision and Language Generative Models with Semantic Visual Priors".
Explain VL generative models using KernelSHAP sentence-based visual explanations, exploiting the model's visual semantic priors.
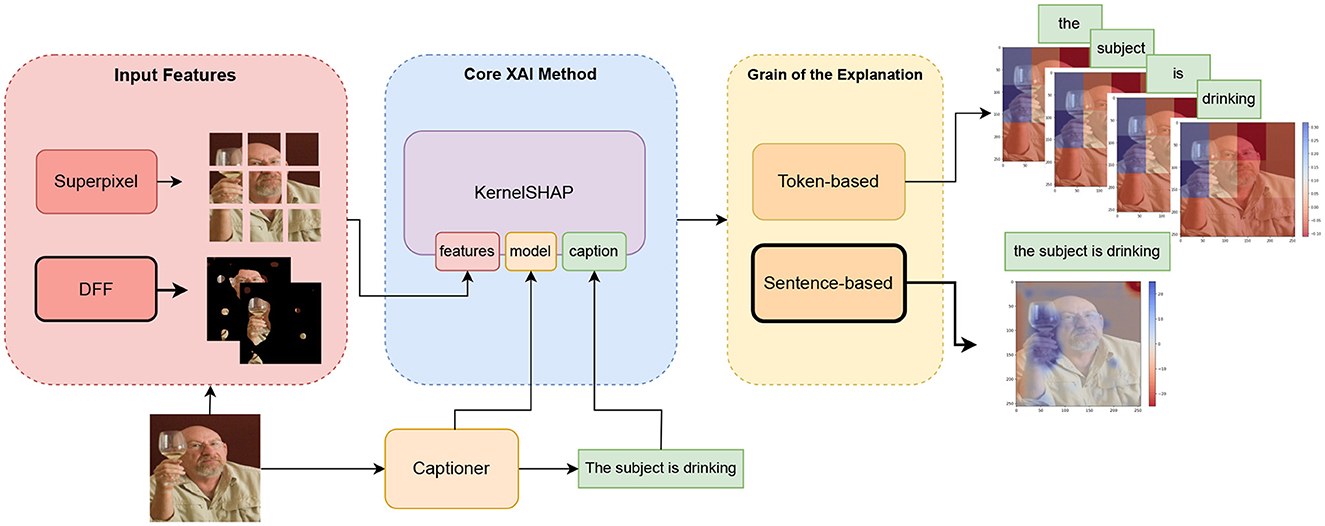
- 🗃️ Repository: github.com/michelecafagna26/vl-shap
- 📜 Paper: Interpreting Vision and Language Generative Models with Semantic Visual Priors
- 🚀 Gradio Demo: michelecafagna26/vl-shap-demo
- 🖊️ Contact: [email protected]
- 25/11/2023 You can try VL-SHAP with the Gradio Demo 🎮 here:michelecafagna26/vl-shap-demo
- 21/11/2023 If you have trouble installing STEGO, you can check out this branch vl-shap/adding_clipseg. Here we replace the STEGO model with Clipseg semantic segmentation model. Clipseg is compatible with the latest python and pytorch library and is easier to install. Moreover, you can control the semantic masks through textual prompts!🚀
3.6.9<= python <= 3.10.12
pytorch <= 1.13
torchvision <=0.14pip install git+https://github.com/lucasb-eyer/pydensecrf.gitpip install git+https://github.com/michelecafagna26/vl-shap.git#egg=semshapInstall OFA from the official repo Then run the following code to extract semantic masks
import requests
from io import BytesIO
from pathlib import Path
from PIL import Image
from transformers import OFATokenizer, OFAModel
from semshap.masking import generate_dff_masks, generate_superpixel_masks
from semshap.plot import heatmap, barh, plot_masks
from semshap.explainers import BaseExplainer
import torch
import torch.nn as nn
from torchvision import transforms
import matplotlib.pyplot as plt
ckpt_dir = "/path/to/the/model/ofa-models/OFA-large" # change this
device = "cuda" if torch.cuda.is_available() else "cpu"
img_url="https://farm4.staticflickr.com/3663/3392599156_e94f7d1098_z.jpg"
# load the model
model = OFAModel.from_pretrained(ckpt_dir, use_cache=False).to(device)
tokenizer = OFATokenizer.from_pretrained(ckpt_dir)
# load the image
response = requests.get(img_url)
img = Image.open(BytesIO(response.content))
# Generate semantic masks
patch_resize_transform = transforms.Compose([
lambda image: image.convert("RGB"),
transforms.Resize(img.size, interpolation=Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
# extract CNN features from the model
with torch.no_grad():
visual_embeds = model.encoder.embed_images(patch_resize_transform(img).unsqueeze(0).to(device))
visual_embeds = visual_embeds.detach().cpu().squeeze(0).permute(1, 2, 0)
# generate DFF semantic masks
out = generate_dff_masks(visual_embeds, k=10, img_size=img.size, mask_th=25, return_heatmaps=True)
# to visualize the masks run
# plot_masks(out['masks'])The explainer expects a model that generates a caption given an image: model(img) --> caption.
Therefore we write a simple wrapper for our model taking care of the preprocessing and the decoding required by the model.
class ModelWrapper(nn.Module):
def __init__(self, model, tokenizer, question, resolution, device="cpu"):
super().__init__()
self.resolution=resolution
self.num_beams = 5
self.no_repeat_ngram_size = 3
self.model = model
self.tokenizer = tokenizer
self.device = device
self.patch_resize_transform = transforms.Compose([
lambda image: image.convert("RGB"),
transforms.Resize(self.resolution, interpolation=Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
self.inputs = tokenizer([question], return_tensors="pt").input_ids.to(self.device)
def forward(self, img):
# put here all to code to generate a caption from an image
patch_img = self.patch_resize_transform(img).unsqueeze(0).to(self.device)
out_ids = model.generate(self.inputs, patch_images=patch_img, num_beams=self.num_beams,
no_repeat_ngram_size=self.no_repeat_ngram_size)
return tokenizer.batch_decode(out_ids, skip_special_tokens=True)[0]Now we can generate a caption in this way
question = "What is the subject doing?"
model_wrapper = ModelWrapper(model, tokenizer, question, resolution=img.size, device=device)
model_wrapper(img)We have everything we need to create and run the KernelSHAP explainer.
explainer = BaseExplainer(model_wrapper, device=device)
shap, base = explainer.explain(img, out['masks'], k=-1)We visualize the Shapley values corresponding to the visual features masks as a barchart, by running
labels = [ f"f_{i}" for i in range(shap.shape[0]) ]
barh(labels, shap)and the visual explanation
heatmap(img, out['heatmaps'], shap, alpha=0.65)In this way you can generate sentence-based visual semantic explanations like these.

For more use cases check the notebooks:
- explain_ofa_dff.ipynb for running the example above, namely a VL model with CNN-based visual-backbone.
- explain_ofa_superpixel.ipynb for comparison with superpixel
- explain_gpt-vit-model_dff.ipynb shows how to explain VL models with ViT visual-backbone.
- explain_ofa_stego.ipynb shows how to explain any model using semantic features extracted from an external segmentation model (STEGO).
In case of problems wiht the pydensecrf module try:
pip install cython
pip install git+https://github.com/lucasb-eyer/pydensecrf.git- The STEGO model has been adapted from the official repo
- The KernelSHAP implementation is based on the official SHAP repo.
@ARTICLE{10.3389/frai.2023.1220476,
AUTHOR={Cafagna, Michele and Rojas-Barahona, Lina M. and van Deemter, Kees and Gatt, Albert},
TITLE={Interpreting vision and language generative models with semantic visual priors},
JOURNAL={Frontiers in Artificial Intelligence},
VOLUME={6},
YEAR={2023},
URL={https://www.frontiersin.org/articles/10.3389/frai.2023.1220476},
DOI={10.3389/frai.2023.1220476},
ISSN={2624-8212},
}