-- For a dataset similar to MNIST trained using MNIST
- Work by Lin, Tzu-Heng, Dept. of Electronic Engineering, Tsinghua University
- 电子工程系 无42 林子恒 2014011054
- Email: [email protected] / [email protected]
- My Linkedin Page: 林子恆 Lin, Tzu-Heng
- My Java, Python Work for Pattern Recognition Course
- -- Make a DBN to classify a set of test data similar to MNIST dataset but with 32x32 pixels
- Using the framework of DeepLeanring4j and theano
- 目录 Content
- 写在前面 Overall
- 前言 About
- 关于网络上的教程 About the Tutorials Online
- 关于本篇报告 About this Report
- 浅显易懂的解释 Introduction of RBM、DBN、Pretrain、Finetuning
- 受限波尔兹曼机 RBM
- 深度置信网 DBN
- 预训练-调整 Pretrain - Finetuning
- 库的介绍与选择 Choice of Tools
- Website of Resources I have used
- Comments
- 我的工作 Configure a DBN
- 前期准备: 编程环境、安装库 Prequisites
- 一些代码的解释 Some Explanation
- 如何构造一个DBN、DBN的参数含义
- 读入老师提供的手写集数据
- 训练效果 Results
- 结论 Conclusions
- 写在后面 —— 关于我, 关于模式识别课程 About me, About Pattern Recognition
- 附录 Log
-
前言 About
- 本篇报告使用了DeepLearning4j(以下简称DL4J), 以及theano的库训练了一个DBN来分类老师所给的32x32手写数据。
- DL4J在IntelliJ IDEA CE的IDE上进行编程, theano是直接用sublime3写, 用命令行运行。
- 其实从第八周后我就开始写这个大作业了, 首先遇到的问题就是要选哪一个库, 那个时候Python和Java都不太熟练, 只会用Matlab。后来, 因为一些别的作业以及在做一些大数据方面的研究, Python以及Java运用得比较熟练了, 所以后来就使用了theano与DL4J; (同时,也切身感受到了Matlab的鸡肋,效率实在是太低了。)
-
关于网络上的教程 About the Tutorials Online
- 再后来看了很多很多RBM相关的教程, 网络上的教程真心都非常非常文言文, 而Hinton的那篇论文如果直接那来看的话其实一般人看不太懂(比如我)...所以我的撞墙期非常非常久, 直到考完试我才比较能够理解RBM、DBN的概念。
-
关于本篇报告 About this Report
-
所以接下来我会...
- 先介绍一下Hinton在他的那篇Reducing the Dimensionality of Data with Neural Network论文(以下简称"文章")里面所说的一些内容, 用正常人都能看懂的话...希望之后的同学可以不要被网上良莠不齐的教程迷惑...
- 再接下来, 我会给出网上一些库, 包括Matlab、Python、Java的RBM、DBN教程链接, 给出一些个人的比较浅显的理解。
- 最后给出我使用DL4J以及theano来分类老师给的32x32图片的具体过程。
- 我还是使用了MNIST dataset数据集来训练, 最后把测试集的图片剪切掉外面的两筐成28x28的来分类。
-
-
由于本人的水平有限, 还望老师、各位同好指出我这篇报告里的不当之处, 谢谢!
-
Introduction of RBM、DBN、Pretrain、Finetuning, etc
-
网络上有很多很多RBM、DBN的解释, 但都讲得非常非常不清楚, 导致我卡了很久很久..., 我在这里给出一个一般人也能理解的解释...希望以后的人可以少走弯路。
-
受限波尔兹曼机 RBM (Restricted Boltmann Machine) :
-
深度置信网 DBN (Deep Believe Network) :
- 所谓的DBN就是将几层RBM网络堆叠(Stack)起来(如下图), 下层的hiddenLayer等于上层的visibleLayer, 这样就可以形成一个多层神经网络(Neural Network), 训练方法其实就是从低到高一层一层的来训练RBM。
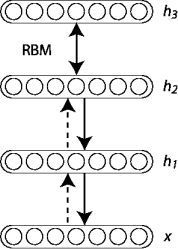
- (图片来自theano)
-
预训练-调整 Pretrain (Initialize a good initial weight) - Finetuning(Backpropagation):
- Hinton在文章中提到, 多层神经网络有一个很本质的问题就在于使用如后向传播算法(backpropagation)来迭代网络时很依赖于初始值的选择, 非常容易就掉入到局部极小值的点。
- 其实整篇文章的重点就在于:
- 先pretrain: 将一个DBN pretrain出来一个很好的初始值供第二步使用, 避免掉入局部极小;
- 再在第一步初始值的基础上, 进行Finetuning, 即后向传播算法。
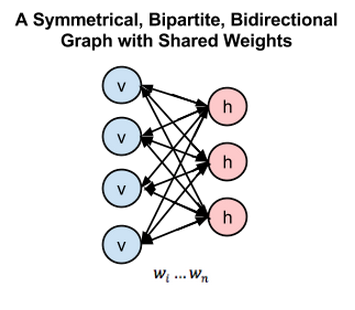
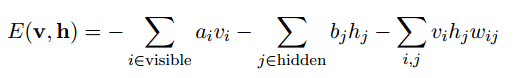
-
我尝试使用了所有可能的工具, 包括Python的theano, SciPy+Opencv的组合, 以及DL4J, 上述的这些库可以说是各有利弊, 我最终选择了使用theano以及DL4J都做了一些测试, 因为相比较于SciPy它们在DBN这块更专精。
-
下面是一些我参考过的库以及教程的链接, 我接下来对他们做一些我自己的比较粗浅的理解, 如有不妥之处, 还望大家指正。
-
Website of Resources I have used:
- Hinton: Hinton's official Matlab Code for DBN + MNIST (Matlab)
- DeepLeanring4j (DL4J) (Java)
- DL4J: A really brief intoduction about how to use DBN on a MNIST (Java)
- DL4J: Brief instructions about how to use DBN on Iris DB (Java)
- Theano (Python)
- Theano: Guide for RBM (Python)
- Theano: Guide for DBN (Python)
- SciPy: Official Tutorial for RBM + Mnist (Python)
- SciPy + Opencv: Tutorial MNIST by pyimagesearch.com (Python)
-
Comments:
- 第1个库就是鼎鼎大名的深度学习鼻祖Hinton的Matlab库
- 上面第3个DL4J的DBN用在MNIST上的教程将MNIST先二值化{0,1}, 然后用RBM进行pretrain、backprop, 我尝试了之后发现效果非常非常差劲; 虽然他在里面也有说, 里面可能要调一些参数,但是我调了非常非常久还是没什么效果。当然, 也很可能是我的能力问题...
- 第4个DL4J构建DBN用在Iris上的教程,与第3个不同,使用的是连续数值的RBM,训练的样本比较小,但构建网络的过程还是非常有参考价值的。
- 第7个Python的theano库, 里面的RBM构建起来稍微比较复杂一些, 但代码的质量还挺不错, 所以我最后主要是用它来处理。具体就是在Pretrain完之后使用Logistic Regression来进行回归、分类。
- 第8、第9个使用了SciPy里的RBM; 也是在Pretrain完之后使用Logistic Regression来进行回归、分类。SciPy里目前好像还不支持连续值的RBM, 只有离散值的BernouliRBM这个二值的可以用。
-
Databases:
-
由于我主要使用的是DL4J以及theano, 其他的一些库的具体操作就不在这里写出来了, 在我提供的上述网址里都可以找到还不错的教程!
-
前期准备: 编译环境、安装库 Prequisites
-
一些代码的解释 Some Explanation
-
如何构造一个DBN、DBN的参数含义
- DL4J
-
使用DL4J来构造一个DBN非常非常简单
-
比如如下给出的代码, 是二值DBN所使用的构造, 该DBN的结构为:784-500-500-2000-10
-
具体参数的解释参见DL4J的网站教程, JAVADOC, JAVADOC for ND4J
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(seed) .gradientNormalization(GradientNormalization.ClipElementWiseAbsoluteValue) .gradientNormalizationThreshold(1.0) .iterations(iterations) .momentum(0.5) .momentumAfter(Collections.singletonMap(3, 0.9)) .optimizationAlgo(OptimizationAlgorithm.CONJUGATE_GRADIENT) .list(4) .layer(0, new RBM.Builder().nIn(numRows*numColumns).nOut(500) .weightInit(WeightInit.XAVIER).lossFunction(LossFunction.RMSE_XENT) .visibleUnit(RBM.VisibleUnit.BINARY) .hiddenUnit(RBM.HiddenUnit.BINARY) .build()) .layer(1, new RBM.Builder().nIn(500).nOut(500) .weightInit(WeightInit.XAVIER).lossFunction(LossFunction.RMSE_XENT) .visibleUnit(RBM.VisibleUnit.BINARY) .hiddenUnit(RBM.HiddenUnit.BINARY) .build()) .layer(2, new RBM.Builder().nIn(500).nOut(2000) .weightInit(WeightInit.XAVIER).lossFunction(LossFunction.RMSE_XENT) .visibleUnit(RBM.VisibleUnit.BINARY) .hiddenUnit(RBM.HiddenUnit.BINARY) .build()) .layer(3, new OutputLayer.Builder(LossFunction.NEGATIVELOGLIKELIHOOD).activation("softmax") .nIn(2000).nOut(outputNum).build()) .pretrain(true).backprop(false) .build();
-
- DL4J
- theano
-
使用theano来构造一个DBN也非常简单,因为库函数都已经写好了只需调用函数并写上参数即可, 如下的代码便可生成一个784-1000-1000-1000-10的DBN
-
具体的参数设置解释参见Official Tutorial, theano DOC
dbn = DBN(numpy_rng=numpy_rng, n_ins=28 * 28, hidden_layers_sizes=[1000, 1000, 1000], n_outs=10)
-
-
读入老师提供的手写集数据 ( importpic.py )
- 这里给出如何利用Python读入老师所给数据的方法
- 读入数据后还要把它剪成28x28的大小, 同时也要转换成灰度值, 并且转换成theano可读的文件类型
- 这个文档是我测试用的.py, 具体的实现已经内嵌到DBN.py里了
- 处理图片使用的库是Opencv以及NumPy
-
首先先对文件重新命名
# 重命名 for item in os.listdir(dire): os.chdir(dire) os.rename(item, item[4:7]+'.png') -
将图片截取成28x28的大小, 我这里最后把它存进了 ./modified_testdataset
# 截取图片成28x28 for item in os.listdir(dire): if item.endswith('.png'): # Read in the files img = cv2.imread(dire+item) print str(img) img2 = img[2:30,2:30] cv2.imwrite(item[0:3]+'.png',img2) -
将所有图片数据存入一个矩阵, 标签数据存入一个数组
label = [] # 标签数组 flag = 0 # target 存测试集矩阵 for item in os.listdir(dire): # 如果是文件且后缀名是.png if item.endswith('.png'): # Read in the files img = cv2.imread(dire+item) img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为grayscle img = img.reshape(1,784) # 变成1x784的矩阵 if flag == 0: target = 255 - img flag = 1 else: target = numpy.row_stack((target, 255 - img)) label.append(int(item[0])) -
theano要求dataset必须要share过...具体share是什么参见Elementwise, Tensortype
# share, readable by theano test_X_matrix = numpy.asarray(target,dtype = float) test_set_x = theano.shared(test_X_matrix) # test_Y_vector = numpy.asarray(label) shared_var_Y = theano.shared(test_Y_vector) test_set_y = T.cast(shared_var_Y, 'int32') # -
最后读入的数据类型:
<TensorType(float64, matrix)> Elemwise{Cast{int32}}.0 -
然后就可以愉快的用theano测试老师给的数据啦啦!
-
-
训练结果 Results
-
DL4J : 这里并没有用老师的数据进行测试, 因为构造出来的DBN, 使用MNIST本身进行测试就仅能有非常非常非常糟糕的结果。
-
二值RBM - DBN ( DL4J/BinaryDBN.java )
-
我先尝试使用了binary即二值的DBN网络;
-
如下, 第三个参数设为true即表示将Mnist的图片进行二值化, 灰度值大于35的即表示成1, 小于35的表示成0:
DataSetIterator iter = new MnistDataSetIterator(batchSize,numSamples,true); -
但是训练出来的结果非常非常差劲, 在pretrain的过程中, 甚至误差越训练越大, 具体的原因我找了非常非常久, 调试了各种各样的参数, 但还是找不出来我的代码里到底哪里有问题。
-
最后的分类结果如下, 我甚至怀疑是DL4J本身的库里的RBM函数出了问题, 因为使用别种layer来训练, 同样的训练、测试集、迭代次数,都能有还不错的结果。
-
-
FeedForward Layer - Direct backpropagation ( DL4J/FFbackprop.java )
-
直接利用FeedForward Layer来进行backpropagation, 层数的设置为:
784-1000-10 -
每个训练迭代集个数为128(batchSize: 128), 从MNIST数据集中随机取出10000个元素, 一共对全部的元素训练15次(15 Epochs)
-
结果非常好, 最后的结果可以达到:
-
-
-
theano : 这里使用了老师的数据集来进行测试
-
DBN ( theano/DBN.py )
-
构造的DBN结构为:784-500-500-2000-10,
-
使用的预处理数据集大小为每次迭代10个元素, 迭代完MNIST的50000个元素。
-
使用的backprop训练集大小为每次迭代10个元素, 迭代完MNIST全部的50000个元素。
-
一共对全部的元素训练10次(10 Epochs)。
-
最后结果如下:
obtained at iteration 50000, with test performance 70.000000 %
-
测试结果不太好...我推测是因为老师给的测试集字体有粗有细,跟MNIST差的有点多, 所以效果非常差劲...
-
-
-
结论 Conclusions
-
做完上述的东西后, 我在网上查阅了一些别人对RBM、DBN、Pretrain等的评价
过时了,没用了,看最近的会议就知道了,今年nips一篇都没有了!
没用了。怕监督信号弥散掉的话,在中间的某几层再加个就好了。如果还觉得不靠谱,可以加入Batch Normalization,用这个可以彻底解决梯度弥散问题,多少层都行。
很久以前有过用非监督方式预训练CNN的工作,后来没人用了,普遍反映没什么用。现在用大量监督数据直接训CNN就行。DBN之流,在理论上还有人在做,但是从效果看好像用处不大。
当然也有人指出:
有用, 实际应用的问题哪裡会所有资料全都有标籤? 深度学习论文常用的资料集, 都有人好心事先土法炼钢标好标籤, 导致后进作论文跟算法的人貌似都没有在人工上标籤,才会误为预训练没用。有预训练才能利用大量没有标籤的资料集作半监督学习, 防止只有少数标籤的资料集过拟合或拟合不足
-
发现其实现在很多人对于Pretrain这件事情并没有这么看好了, 因为其实用大量监督数据直接做训练, 完全可以弥补; 我做的东西也是, 其实Pretrain相较于直接进行backpropagation并没有这么好, 而且如果使用相同的迭代次数, 效率相较于后者并不高, 因为pretrain阶段其实也是非常消耗时间的。
-
当然上上条后者指出的实际问题没有标签也是一个大问题, 毕竟还没有这方面的经验, 我也不好对此作出评价。
-
-
About me, About Pattern Recognition
-
关于我:
-
这学期之前的大学生活都一直忙碌于各种各样的社工、比赛, 没有把一点心思放在学习上, 直到这个学期才后知后觉其实在大学里面学习知识才是最根本最宝贵的东西, 特别是如我在电子工程系, 或者贵系。
-
之前就一直对深度学习、人工智能这一块非常非常感兴趣, 却一直没有一个很好的渠道来入门; 我本身非常非常喜欢EECS里偏软的这一块, 所以一直想转系转来贵系, (也因为电子系学的一些课程实在是太硬了, 硬到我开始怀疑人生了...)...但后来因为觉得成本还是太高就作罢了, 而且毕竟在我们系也有做这个方向的研究, 或者研究生阶段在转其实也不迟!
-
上学期在选课的时候就有特别留意计算机系的课程, 抢到了一门并行计算基础、还有就是这门模式识别, 前者后来被我中期退课退掉了,因为学的东西还是比较艰深苦涩、作业也有些无从下手; 后者, 也就是模式识别, 我非常非常喜欢, 这门课也是上大学以来第一门我自己想选的任选课。
-
-
关于模式识别课程:
-
虽然还只是大二、还没修概率论, 后来的一些课程在课堂上时有一些跟不上, 但我在课后自己读Duda的Pattern Classification还算能读懂。不得不提, 有几次的Matlab作业花了我非常非常多的时间...
-
总之, 虽然花了挺多的时间, 但在模式识别的这门课上我学到了非常非常多有用的东西、学习方法; 人工智能是21世纪的一个前沿课题, 现在好多好多的各种应用都在与人工智能扯上关系, 而模式识别, 可以说是作为人工智能的一个最基础的学科了。
-
这个学期我也参加了一个SRT项目, 关于大数据的电商分析。前阵子与一名我们系的博士生以及本科生co-author了一篇paper, 现在正在投稿到Ubicomp, 不知道能否被接受;但不得不说的是, 我在分析数据时使用的一些方法就是在课程当中学到的内容, 学以致用的感觉让我非常满足。
- 与老师相处的这一个学期非常愉快也非常充实, 希望以后还有机会可以上老师的课 !
- 最后, 谢谢老师、助教这一学期来的帮助与指导 !
-
2016.5.1 - 2016.6.20 Testing tools & Reading papers, codes, etc
2016.5.1 Tring Matlab Deepleanring Toolbox
2016.5.15 Tring Theano
2016.6.1 Tring DL4J
2016.6.15 Tring SciPy + Opencv
2016.6.22 17:24 Finally understood the structure. Built a structure of DBN.
2016.6.23 12:52 Sucking binary RBM layers by DL4J.
2016.6.23 17:17 Writing the reports
2016.6.23 22:49 Abandon DL4J, Switching to theano, python
2016.6.24 01:50 Started Python Debugging
2016.6.24 03:13 I'm going to go to sleep first.
2016.6.24 10:10 Wake up, continue coding.
2016.6.24 13:29 All Done. Finished!
- 林子恒 2016.6.24 13:29 于紫荆公寓 1#
- Lin, Tzu-Heng
- 2016.6.24 13:29 at dorm
Copyright 2016 Lin, Tzu-Heng