
scraper-fourone-jobs 是解析某求職網站徵才頁中的應徵資料的反爬蟲程式,該程式僅為學習研究使用,並專注在解析反爬蟲的部分,請勿使用程式在商業用途。
會有該專案的原因是因在 Python Taiwan 看見有人詢問如何抓取並突破反爬蟲,在回答對方的過程中,認為還是要自己寫一次才能找出所有原因,畢竟反爬蟲的方式有許多種,每一種也有變形,所以才會動手開發與解析該網站的反爬蟲。
另外因該專案是在 2019.06.28 撰寫開發並完成,因此未來可能因該「求職網」改變反爬蟲的方法而導致此程式失效。
「求職網」欲爬取的資料與 HTML 源碼
- 開發環境:
vscode - 語言版本:
Python 3.7 - 安裝套件:
pipenv,fonttools,lxml,requests
歡迎你來到此專案,如果你喜歡該專案也願意的話,希望能給我一個 Star,此外若你有興趣的話,目前英文的翻譯正在進行中,非常歡迎 Fork 這個小專案並且 Send PR 協助翻譯哦!
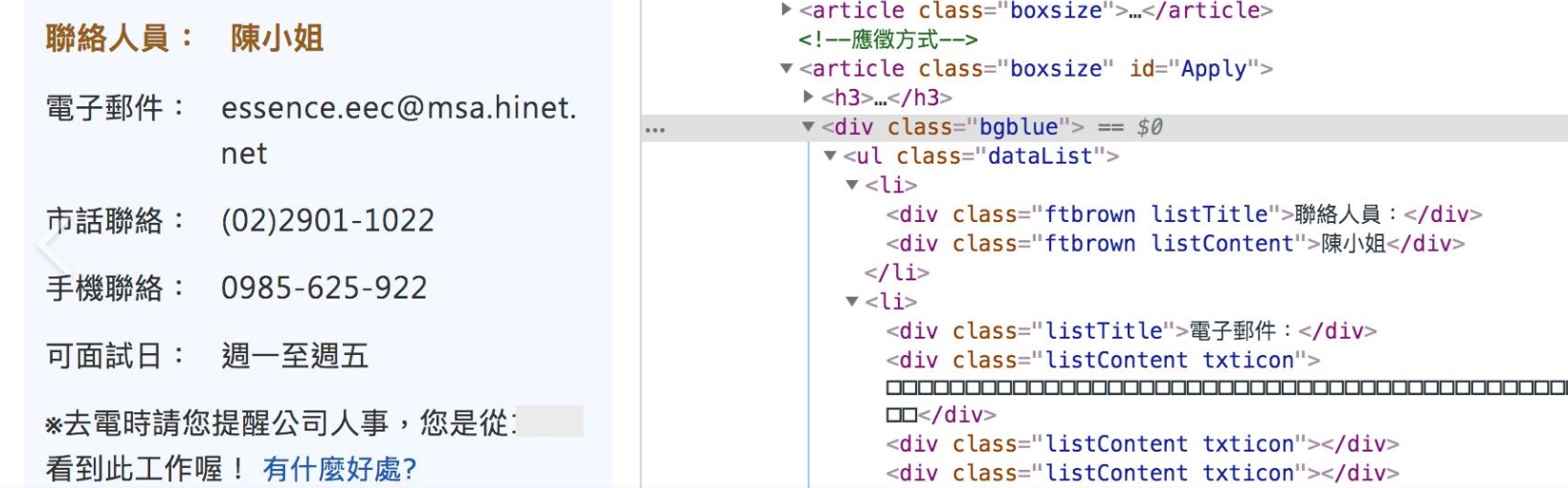
在該程式中的所要擷取的資料來源是徵才頁面中的應徵資料,而在該應徵資料中的「信箱」、「市話」與 「手機」,若透過正常的爬蟲解析方式如 XPath 是無法抓取下來,而會出現意義不明的編碼,透過 HTML 源碼查看確實如此,如下圖:
HTML 源碼文字

在反爬蟲中,對於顯示資料正常,但 HTML 源碼為亂碼的狀態,通常不外乎屬於可以較晚加載處理,影響 HTML 源碼內容與顯示的 JavaScript 或是 CSS 的樣式字型編碼的類型。像是 JavaScript 可以在觸發某個行為或是透過計時改變 HTML 的顯示或內容;而 CSS 會透過樣式來改變原本 HTML 的外觀,所以不外乎會是這兩個選擇之一優先考慮。
接著溝通時間分析與過濾發現了 CSS 樣式 Class txticon 是可能的原因,並且循著來源發現了一個自定義 font-family 數值 'runes':
txticon 的 CSS 定義

通常看到自定義的 font-family 後,那麼機會十之八九就會是 CSS 字型編碼造成的反爬蟲技巧。
因為 font-family提供的字型來源是自定義的,那麼一定需要夾帶著該檔案才能正常顯示文字。因此接著繼續尋找,便會發現一個路徑為 webService/NET40/Runes/fonts/Books的目錄,並且底下有兩個檔案,皆是看似亂碼的名稱與兩個不同的副檔名 .css 與 .woff?v0001。
首先打開副檔名為 .css 檔案,就會直接看到定義 runes 字型的 font-face 屬性,這是在 CSS3 提供的新屬性,用來協助開發端可以提供字型給用戶呈現,而這個 font-face 也常常被拿來作為 CSS 字型編碼反爬蟲的方式。
自定義的 font-family 字型字體 runes 所在位置
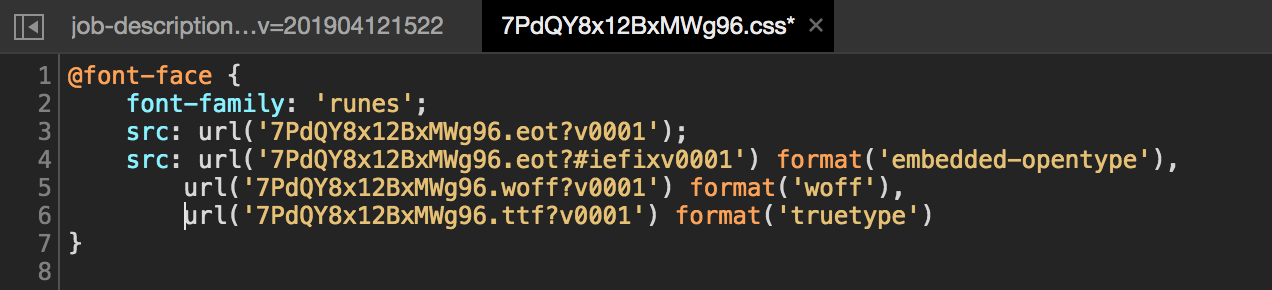
從其中的 url 也可以看到該網站使用的字型格式種類,不過目前僅有「網路開放字型格式」(Web Open Font Format)存在,對照 webService/NET40/Runes/fonts/Books 就是副檔名為 .woff?v0001 的字型檔。
不過通常這類命名像是亂碼的字型非常有可能是每次請求自動產生,也很有可能每次字型檔的編碼內容都不同,所以需要多次下載檔案,並且跟 HTML 來源的編碼再三確認,是否每次都不同。
接著複製該字型檔案的所在 URL 路徑並下載下來,嘗試解析該字型檔的內容,讓爬蟲程式可以透過下載的字型檔案,把抓取下來的在 HTML 上顯示的亂碼文字可以正常顯示。
下載了字型檔案後,要開始解析字型的格式,因為這些字型都都會紀錄了不同的文字,以及這些文字要顯示的編碼。
所以前面從 HTML 抓取的文字雖然是亂碼,但是這些亂碼的編碼丟到字型檔案中時,亂碼的編碼可以對應到字型文字的編碼,就像查表翻譯一樣轉成可以正常顯示的文字。
這也是為何需要下載字型並先解析內容,透過程式來協助翻譯成正確的內容,因為爬蟲程式不是瀏覽器,所以要自己來做。
接著聊到解析了, 這邊推薦如果是 Windows 系統,可以去安裝 FontCreator 這套軟體,並且透過這套軟體以視覺化的形式查看裡面的字型,與每個字型會有對應的 16 進制 Unicode 編碼,例如下圖:
FontCreator 字型檢視範例

在上圖的範例並非該「求職網」,而是其他反爬蟲文章解說的例子截圖,會看到字型 左 對應到 Unicode 的 uniED8C ,而這個 Unicode 就是需要編碼。另外 Unicode 的前綴字 uni 可以省略他主要是前面的即可。
不過在 MacOSX 上並不能使用 FontCreator 這套軟體,此時可以建議使用 FontDrop!,這個字型檢視服務有著完整的檢視功能,只需要把字型檔匯入即可,如下圖,上傳剛剛從「數字求職網」下載的字型檔:
FontDrop! 檢視字型

在上圖中會看到不同的字型,且每個字型皆有會顯示該 Unicode 編碼。接著點進去字型後便會看見更多內容:
FontDrop! 檢視字型細節

首先是 Unicode 的編碼變多了,為什麼? 其實每個字型並非只有一個代表的 Unicode 對應碼,可以很多不同的編碼皆適用,只是都會有一個代表碼,而代表碼會是顯示第一個,例如這邊的例子 ( 會是 E19B。
另外兩個比較重要的訊息分別是 Index 與 Contours data:
- Index : 表示的是這個字型在字型表中的順序。
- Contours data : 表示的是該字型的輪廓,會由不同座標來描繪
因為上述兩個參數,會隨著 CSS 反爬蟲的難度,而有不同的因素關鍵,幫助判別,後面的例子會提到,因此先記住便可。
上述分析後大致上知道原因,接著就用透過程式處理。安裝 Python 的 fonttools 套件,該套件可以讀取字型檔案的內容,安裝完後可以透過 TTFont 直接載入檔案路徑,或是二進制內容,並且先透過 saveXML 方法存成 XML 格式:
import io
import requests
from fontTools.ttLib import TTFont
...
url = "Font 所在 URL 位置路徑"
resp = requests.get(url)
# 如果直接讀取檔案 => TTFont("Font字型檔案位置")
font = TTFont(io.BytesIO(resp.content))
font.saveXML("保存的路徑")保存 XML 格式檔案的原因,是因為 TTFont 會根據字型字體的規範來解析與讀取,並且不同的字體會有不同的規範格式,例如 WOFF - Web Open Font Format 、 TTF - TrueType 與 EOT - Embedded OpenType 內部定義資料的屬性與標籤皆會不同。
因此雖然在前半段透過了 FontCreator 或 FontDrop! 讀取字型檔案並看見可視化的內容,但仍然需要了解字體內部的規範與定義,在使用 fonttools 提供的方法時,才能知道要呼叫的方法會對應什麼標籤、什麼資料值。所以當存成 XML 後便可以直接閱讀。
那麼接著來打開保存的 XML 格式字型檔來認識認識。
GlyphOrder 與 GlyphID 標籤:會有序的紀錄該字型檔的所有字型。每個 GlyphID 標籤藉由 索引 (Index) 以及各自代表的 Unicode 編碼來代表字型。這也可以對照到前面的 FontDrop! 中的 Index 資訊,因此便可以透過該 Index 得知彼此在 FontDrop! 上所呈現的字型是什麼文字。
例如下圖中看一下索引為 4 的 Unicode 編碼為 uniE19B,而對照一開始的 FontDrop! 會是 ( 。
字型 XML 格式 - GlyphOrder 與 GlyphID 標籤

而在 Python 的 fonttools 中,可以透過呼叫 getGlyphOrder 方法來取得 GlyphOrder 標籤:
# getGlyphOrder 會回傳陣列,該陣列會以 GlyphOrder 中的 GlyphID 索引為依序排列
orders: List[str] = font.getGlyphOrder()getGlyphOrder 方法顯示

TTGlyph 與 contour 標籤: TTGlyph 會紀錄 GlyphID 文字代表的 Unicode 編碼在字型檔中的「輪廓資訊」,包含該字型的最小最大 X, Y 寬高,以及由標籤 contour 所組成的「輪廓描繪座標」。
因為字型檔中的字型是透過輪廓描述並識別的,因此不會有任何標籤告知該字型是什麼「字」,而是只會紀錄該字的「輪廓」,只是透過軟體看得出是什麼文字而已。另外這些輪廓做標可以在 FontDrop! 中也能找到一樣的資訊。
例如上述的索引 GlyphID 標籤索引為 4,該 Unicode 為 uniE19B,透過 Unicode 為 uniE19B 找到的輪廓數值與 FontDrop! 中的 ( 會是一模一樣的輪廓座標。
字型 XML 格式 - TTGlyph 與 contour 標籤

在 fonttools 中,可以透過 get 方法帶入 glyf 標籤值直接取出所有的 TTGlyph 標籤並尋找要的輪廓值,如下:
字型 XML 格式 - TTGlyph 與 contour 標籤

cmap 與 map 標籤:這兩個標籤紀錄了字型中每個字的其他 Unicode 編碼,例如這邊的 uniE0AF, 首先 code 屬性會看到同樣是同樣數值的 0xe0af (其中的 0x 可以忽略),而這個 code 屬性表示了其他可以匹配的 Unicode 編碼。
字型 XML 格式 - cmaps 與 cmap 標籤

再來尋找原先想要的例子 uniE19B,可以接著看到該字型 ( 其他的 Unicode 編碼,如下圖中除了自己本身的 code 為 0xe19b 外,其他對應到 uniE19B 編碼的 code 包含了 0xe20b 與 0xe248,把這兩個 Unicode 編碼 E20B 與 E248 對照一下 FontDrop! 中便可以找到有一模一樣的數值。
字型 XML 格式 - 其他的 Unicode 編碼

在 fonttools 中,可以透過呼叫 getBestCamp 方法來取得最佳的 cmap 標籤與資訊,因為字型檔案中有對應不同 platform 的版本 - cmap_format_4 與 cmap_format_6。
# 回傳的會是字典格式
orders: Dict[str, str] = font.getBestCamp()getBestCamp 方法取得最佳的 cmap 資訊

如上圖在 fonttools 中會把 code 轉換成 10 進制的資料,因此原本的 uniE19B 的 code 為 0xe19b 便會轉換成 57755,所以在使用時,要近得處理進制轉換,看是要以十進制比對,還是把 57755 轉換成 0xe19b 比對。
到此這些就是在實作解析字型檔時,可以協助判斷的「標籤」與「屬性」,雖然也可以透過一些軟體,如 FontCreator 或 FontDrop! 以視覺化的方式快速分析字型檔,但是仍建議儲存成 XML 檔案來分析細節。
接下來就來回到一開始爬取下來的亂碼資料,透過先前所介紹的方式來解析與翻譯吧!
雖然在 HTML 源碼看到的亂碼,但那其實代表的只是因為該「編碼」魔有對應的文字而已,所以當抓下來貼到 Python 上時會看到該 Unicode 的編碼,如下圖:
Python 3 顯示該 HTML 源碼字串編碼

不過因為 Python 3 的字串是 Unicode 格式,所以在 Python 中 print 顯示時會被自動轉換,也就看不到原來的編碼樣子。當然在做字串中的字元比對翻譯時也會照成影響,所們可以透過 encode 指定 unicode-escape 跳脫字元協助並轉換回 UTF8 編碼,這樣再對 \\u 做字串切割並依序匹配即可。
藉由 unicode-escape 協助字元比對

知道了如何分析與查看 HTML 亂碼後,再來就要驗證一開始的在2.尋找 CSS 編碼反爬蟲的字型檔中提到的是否每次請求的 HTML 亂碼編碼與字型檔皆不同,並且非常可惜的是沒有錯...每次都會改變編碼:
再次請求後的 HTML 編碼
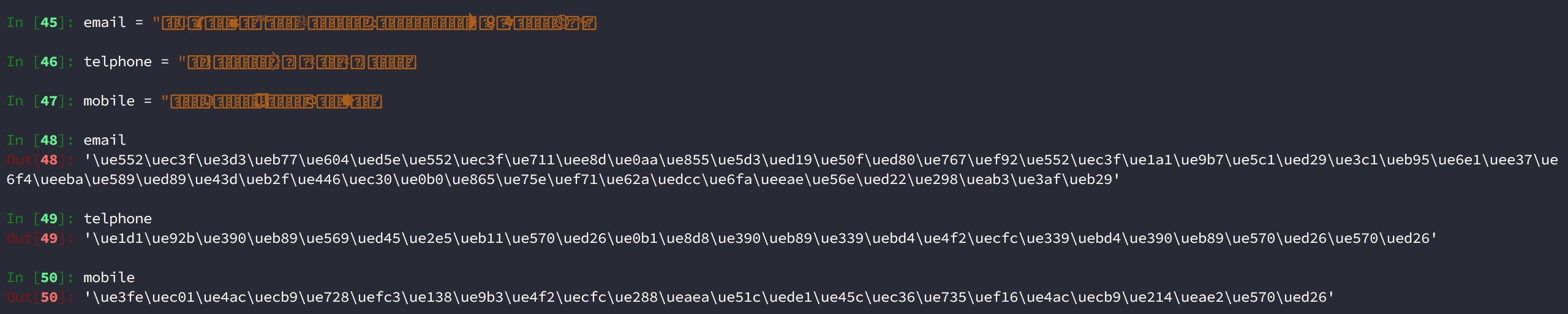
再次請求後的字型檔

這也使翻爬蟲的麻煩度多了一些,但是好在不同的字型檔的索引順序與字型的輪廓ㄧ致,所以只要透過以下五個步驟便可以解決。
- 每次 Request 請求時,同時取得字型檔案下載。
- 爬取 HTML 內容比透過
unicode-escape編碼處理,與字串切割取得每個編碼。 - 把編碼轉換成 10 進制,透過
fonttools字型套件的cmaps找出代表的編碼,比對原先切割好的 HTML 編碼做 10 進制轉換int("轉換的字串", 16)。 - 在透過代表的編碼找出
GlyphOrder的索引 - 建立一個索引與字型文字的字典匹配並轉換
當然這還算是容易的,如果每次請求下來的字型檔案內部的索引文字順序皆不同,那麼就要透過 TTFGlyph 的 contour 比對字型輪廓座標。
更複雜的,若是連每一次的輪廓座標也不同,那麼步驟五的建立索引與文字字典,就不能使用了,要改成 OCR 做辨認了..。
該專案採用 GNU General Public License v2.0。