Hadoop MapReduce Tutorial
Hadoop MapReduce is a framework for processing large datasets in parallel using lots of computers running in a cluster, behaving as if they were one big computer.
You can extend the Mapper class with your own instructions for how to handle input. You might think of the map method as a data extractor that pulls and organizes values from the input source.
During the map process, the master computer instructs worker computers to process their local input data. Hadoop performs a shuffle process, where each worker computer passes its results to the appropriate reducer computer. The master computer collects the results from all reducers and compiles the answer to the overall query.
You can extend the Reducer class with your own output instructions. You can think of the reduce method as a "summarizer," gathering the results from the map method and generating useful output.
While it makes sense to think of the map and reduce processes in sequential terms, there might be some overlap at runtime. For example, if all of the output for the same key value is available from the map machines, that data can be distributed to the reduce machines, even if the map phase is not completely finished.
#A Parable Hadoop recently released an eponymous product to market, a roasted groat cereal with treat disguises: purple circles, yellow triangles, orange hexagons, blue squares, green octagons, and red rhombuses.

He wondered what the actual distribution of candy elements was in the real world, as he wanted to ensure that they were getting equal representation in every bowlful. Being inherently lazy, Hadoop called up his cluster of friends and relatives, and asked each of them to count up the candy bits in the box of cereal they had in their own cupboard.

When all of the individuals had sorted and counted (mapped) the contents of their own boxes, they sent the results to Hadoop's closest friends, Reed and Deuce. Reed got the results for the purple circles, yellow triangles, and orange hexagons. Deuce got the results for the blue squares, green octagons, and red rhombuses.

Reed and Deuce summarized (reduced) the results by dividing the sum of each candy element by the number of cereal boxes, computing an average number of each type of candy in a typical box of Hadoops! cereal.
By spreading the workload around and working in parallel, Hadoop and his cluster were able to accomplish this cereal task quickly and accurately.
#An Example
Here's a flowchart for a MapReduce application that tallies the results in the not very popular "America Yodels" television talent contest.
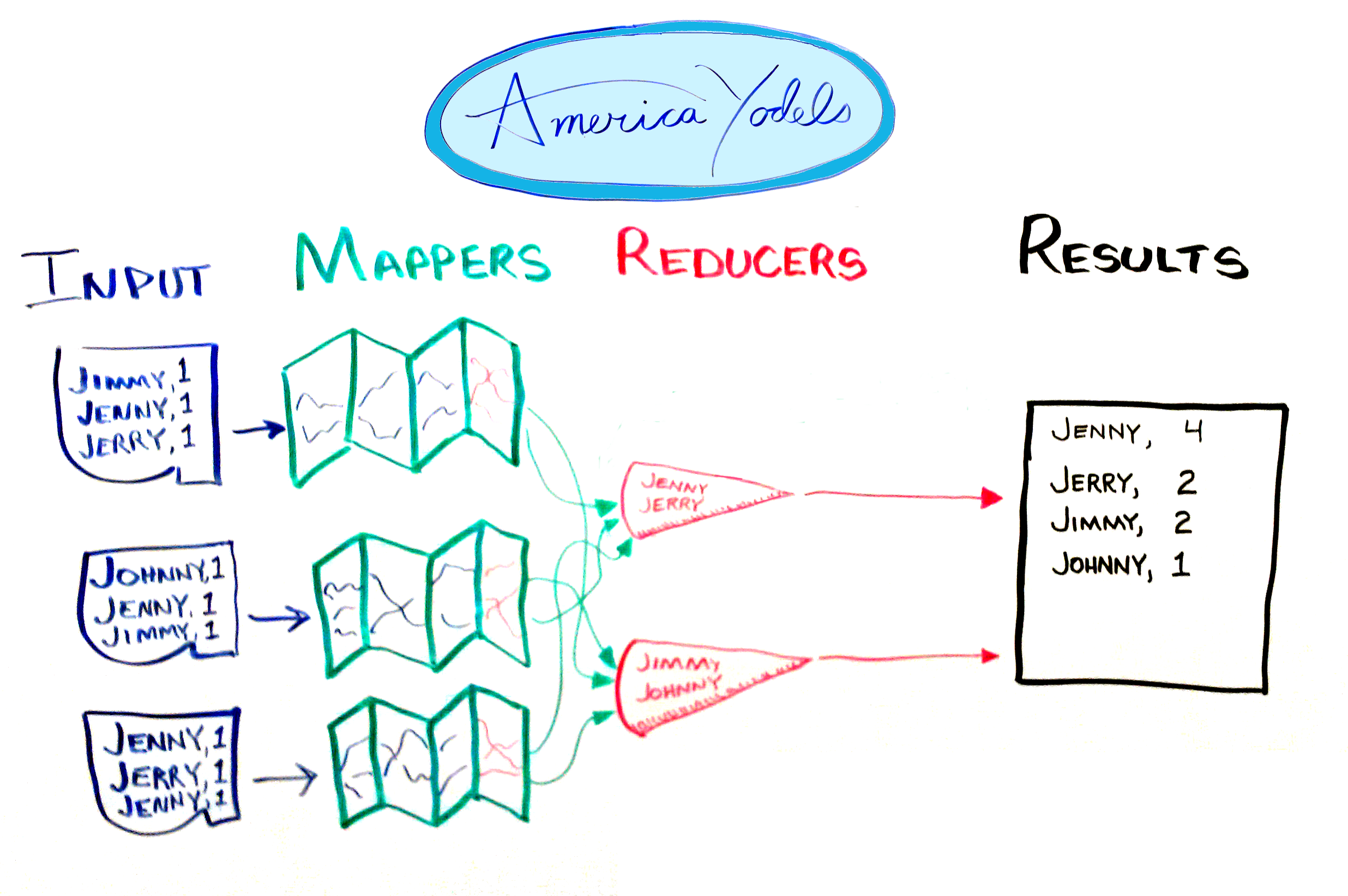
The input data consists of the names of the contestants and one vote apiece.
The mappers scan the input, extract the votes, and group them together.
Hadoop performs the shuffle phase, where the intermediate results are sent directly to the correct reducer for processing. Hadoop does the shuffle for you automagically. In this example, the votes for Jenny and Jerry are sent to one reducer, the votes for Jimmy and Johnny are sent to the second reducer.
The reducers summarize the data and send the results to the master computer, which compiles the information and presents it in its final form.
#A Sample
You can map and reduce data based on a variety of criteria. A common example is the Java WordCount class. As the name suggests, WordCount maps (extracts) the words in your input and reduces (summarizes) the results with a count of the number of instances of each word. The following versions of WordCount have been implemented to take advantage of the features in the MapReduce2 API.
The command line arguments to build and run the application are provided throughout. Many of these commands have been consolidated into a Makefile for your convenience.
###WordCount Version One
WordCount version one is a basic implementation of a MapReduce class. You provide input in the form of one or more text files. The Map class extracts the words from the files, the reducer totals the number of times each word appears in the extracted values and returns the result.
Here is a link to the unsullied source code for WordCount version one that you can copy and run. Let's walk through the code.
Use an appropriate package, or just keep the generic version. The only standard Java classes you need to import are IOException and regex.Pattern, which you'll use to extract words from the input files.
package org.myorg;
import java.io.IOException;
import java.util.regex.Pattern;This application extends the class Configured, and implements the Tool utility class. Essentially, you tell Hadoop what it needs to know to run your program in a configuration object. Then you use ToolRunner to run your MapReduce application.
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;The Logger class is useful to send debugging messages from inside the mapper and reducer classes. When you run the application, one of the standard INFO messages provides an URL you can use to track the job's success. Any messages you pass to the Logger are displayed in the map or reduce logs for the job on your Hadoop server.
import org.apache.log4j.Logger;You need the Job class in order to create, configure, and run an instance of your MapReduce application. You extend the Mapper class with your own Map class and add your own processing instructions. The same is true for the Reducer: you extend it to create and customize your own Reduce class.
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;You use the Path class to access files in HDFS. In your job configuration instructions, you pass required paths using the FileInputFormat and FileOutputFormat classes.
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;Writable objects have convenience methods for writing, reading, and comparing values during map and reduce processing. You might think of the Text class as StringWritable, because it performs essentially the same functions as those for integer (IntWritable) and long integer (LongWritable) objects.
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;WordCount includes main and run methods, and the inner classes Map and Reduce.
public class WordCount extends Configured implements Tool {
private static final Logger LOG = Logger.getLogger(WordCount.class);The main method invokes ToolRunner, which creates and runs a new instance of WordCount, passing the command line arguments. When the application is finished, it returns an integer value for the status, which is passed to the System object upon exit.
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new WordCount(), args);
System.exit(res);
}The run method configures the job (which includes setting paths passed in at the command line), starts the job, waits for the job to complete, then returns a boolean success flag.
public int run(String[] args) throws Exception {Create a new instance of the Job object. This example uses the Configured.getConf() method to get the configuration object for this instance of WordCount, and names the job object wordcount.
Job job = Job.getInstance(getConf(), "wordcount");Set the jar to use, based on the class in use.
job.setJarByClass(this.getClass());Set the input and output paths for your application. You store your input files in HDFS, then pass the input and output paths as command line arguments at runtime.
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));Set the map and reduce class for the job. In this case, use the Map and Reduce inner classes defined in this class.
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);Use a Text object to output the key (in this case, the word being counted) and the value (in this case, the number of times the word appears).
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);Launch the job and wait for it to finish. The method syntax is waitForCompletion(boolean verbose). When true, the method reports its progress as the Map and Reduce classes run. When false, the method reports progress up to, but not including, the Map and Reduce processes.
In Unix, 0 indicates success, while anything other than 0 indicates a failure. So when the job completes successfully, the method returns a 0. When it fails, it returns a 1.
return job.waitForCompletion(true) ? 0 : 1;
}The Map class (an extension of Mapper) transforms key/value input into intermediate key/value pairs to be sent to the Reducer. The class defines several global variables, starting with an IntWritable for the value 1, and a Text object used to store each word as it is parsed from the input string.
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();Create a regular expression pattern you can use to parse each line of input text on word boundaries ("\b"). Word boundaries include spaces, tabs, and punctuation.
private static final Pattern WORD_BOUNDARY = Pattern.compile("\\s*\\b\\s*");Hadoop invokes the map method once for every key/value pair from your input source. This does not necessarily correspond to the intermediate key/value pairs output to the reducer. In this case, the map method receives the offset of the first character in the current line of input as the key, and a Text object representing an entire line of text from the input file as the value. It further parses the words on the line to create the intermediate output.
public void map(LongWritable offset, Text lineText, Context context)
throws IOException, InterruptedException {Convert the Text object to a string. Create the currentWord variable, which you'll use to capture individual words from each input string.
String line = lineText.toString();
Text currentWord = new Text();Use the regular expression pattern to split the line into individual words based on word boundaries. If the word object is empty (for example, consists of white space), go to the next parsed object. Otherwise, write a key/value pair to the context object for the job.
for (String word : WORD_BOUNDARY.split(line)) {
if (word.isEmpty()) {
continue;
}
currentWord = new Text(word);
context.write(currentWord,one);
}
}The mapper creates a key/value pair for each word, comprised of the word and the IntWritable value 1. The reducer processes each pair, adding one to the count for the current word in the key/value pair to the overall count of that word from all mappers. It then writes the result for that word to the reducer context object, and moves on to the next. When all of the intermediate key/value pairs are processed, the map/reduce task is complete. The application saves the results to the output location in HDFS.
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text word, Iterable<IntWritable> counts, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable count : counts) {
sum += count.get();
}
context.write(word, new IntWritable(sum));
}
}
}###Running WordCount Version One You can run the sample in your own Hadoop environment. If you don't have one available, you can download and install the Quickstart virtual machine from the Cloudera website.
Before you run the sample, you need to create input and output locations in HDFS.
To create the input directory /user/cloudera/wordcount/input in HDFS:
$ sudo su hdfs
$ hadoop fs -mkdir /user/cloudera
$ hadoop fs -chown cloudera /user/cloudera
$ exit
$ sudo su cloudera
$ hadoop fs -mkdir /user/cloudera/wordcount /user/cloudera/wordcount/inputCreate sample text files as input and move to the input directory in HDFS. You can use any files you choose, but here's a shell script to create a few of short input files for illustrative purposes. The Hadoop MapReduce Makefile also contains most of the commands that follow, for your convenience.
$ echo "Hadoop is an elephant" > file0
$ echo "Hadoop is as yellow as can be" > file1
$ echo "Oh what a yellow fellow is Hadoop" > file2
$ hadoop fs -put file* /user/cloudera/wordcount/inputCompile the WordCount class.
$ mkdir -p build
$ javac -cp /usr/lib/hadoop/*:/usr/lib/hadoop-mapreduce/* WordCount.java -d build -XlintCreate a Jar file for the WordCount application.
$ jar -cvf wordcount.jar -C build/ .Run the WordCount application from the Jar file, passing the paths to the input and output directories in HDFS.
$ hadoop jar wordcount.jar org.myorg.WordCount /user/cloudera/wordcount/input /user/cloudera/wordcount/outputWhen you look at the output, you'll see that all of the words are listed in UTF-8 alphabetical order (capitalized words first). The number of occurrences from all input files have been reduced to a single sum for each word.
$ hadoop fs -cat /user/cloudera/wordcount/output/*
Hadoop 3
Oh 1
a 1
an 1
as 2
be 1
can 1
elephant 1
fellow 1
is 3
what 1
yellow 2If you want to run the sample again, you first need to remove the output directory.
$ hadoop fs -rm -r /user/cloudera/wordcount/output###A Walkthrough
The main method invokes the ToolRunner to run the job based on the configuration information
The map method processes one line at a time, splitting the line on regular expression word boundaries. It emits key/value pairs in the format <word, 1>.
For File0 the map method emits these key/value pairs:
<Hadoop, 1>
<is, 1>
<an, 1>
<elephant, 1>For File1 the map method emits:
<Hadoop, 1>
<is, 1>
<as, 1>
<yellow, 1>
<as, 1>
<can, 1>
<be, 1>For File2 the map method emits:
<Oh, 1>
<what, 1>
<a, 1>
<yellow, 1>
<fellow, 1>
<is, 1>
<Hadoop, 1>The reduce method adds up the number of instances for each key, then emits them sorted in UTF-8 alphabetical order (all uppercase words, then all lowercase words). Note that the WordCount code specifies key/value pairs. The Mapper and Reducer classes handle the rest of the processing for you.
<Hadoop, 3>
<Oh, 1>
<a, 1>
<an, 1>
<as, 2>
<be, 1>
<can, 1>
<elephant, 1>
<fellow, 1>
<is, 3>
<what, 1>
<yellow, 2>##WordCount Version Two WordCount version one works well enough with files that only contain words. Just for grins, let's remove the current input files and replace them with something slightly more complex.
$ hadoop fs -rm /user/cloudera/wordcount/input/*Here are three poems from the never to be published work "Songs of Hadoop" that you can add to your input directory.
HadoopFile0.txt
Hadoop is the Elephant King!
A yellow and elegant thing.
He never forgets
Useful data, or lets
An extraneous element cling!
HadoopFile1.txt
A wonderful king is Hadoop.
The elephant plays well with Sqoop.
But what helps him to thrive
Are Impala, and Hive,
And HDFS in the group.
HadoopFile2.txt
You can create the files however you like, but these shell commands will do the trick (or you can use the Makefile command "make poetry"). ```Shell $ echo -e "Hadoop is the Elephant King! \\nA yellow and elegant thing.\\nHe never forgets\\nUseful data, or lets\\nAn extraneous element cling! " > HadoopPoem0.txt $ echo -e "A wonderful king is Hadoop.\\nThe elephant plays well with Sqoop.\\nBut what helps him to thrive\\nAre Impala, and Hive,\\nAnd HDFS in the group." > HadoopPoem1.txt $ echo -e "Hadoop is an elegant fellow.\\nAn elephant gentle and mellow.\\nHe never gets mad,\\nOr does anything bad,\\nBecause, at his core, he is yellow." > HadoopPoem2.txt $ hadoop fs -put HadoopP* /user/cloudera/wordcount/input $ rm HadoopPoem* ``` Remove the previous results and the application with the poems as input. ```Shell $ hadoop fs -rm -r -f /user/cloudera/wordcount/output $ hadoop jar word_count.jar org.myorg.WordCount /user/cloudera/wordcount/input /user/cloudera/wordcount/output ``` View the results. ```Shell $ hadoop fs -cat /user/cloudera/wordcount/output/* ``` You'll notice that there are some problems with the output. The WordCount application counts lowercase words separately from words that start with uppercase letters, even though it's plain as day that they are the same word. ```Shell . . . Elephant 1 elephant 2 . . . ``` Hadoop also considers punctuation and small words significant. ```Shell . . . ! 2 , 7 . 7 A 2 An 2 And 1 . . . ``` You can update your sample code to address these problems and return a more accurate count.Hadoop is an elegant fellow.
An elephant gentle and mellow.
He never gets mad,
Or does anything bad,
Because, at his core, he is yellow.
###Hadoop's Sensitive Side
First, you can add a few lines of code to remove case sensitivity, so that both lowercase and capitalized versions of your words are included in a single count. You can get the full source code at WordCount Version Two. Let's look at the changes.
Line 5: Import the Configuration class. You use it to access command line arguments at runtime.
import org.apache.hadoop.conf.Configuration;Line 47: Create a variable for the case sensitivity setting in the Map class.
private boolean caseSensitive = false;Lines 50 - 55: Add a setup method. Hadoop calls this method automatically when you submit a job. This code instantiates a Configuration object, then sets the class caseSensitive variable to the value of the wordcount.case.sensitive system variable, set from the command line. If you don't set a value, the default is false.
protected void setup(Mapper.Context context)
throws IOException,
InterruptedException
{
Configuration config = context.getConfiguration();
this.caseSensitive = config.getBoolean("wordcount.case.sensitive", false);
}Lines 60 - 62: Here's where you turn off case sensitivity. If caseSensitive is false, the entire line converts to lowercase before it is parsed by the StringTokenizer.
if (!caseSensitive) {
line = line.toLowerCase();
}###Running WordCount Version Two
Rebuild the application. You can enter these instructions at the command line, or you can use the Makefile command make jar.
$ rm -rf build word_count.jar
$ mkdir -p build
$ javac -cp /usr/lib/hadoop/*:/usr/lib/hadoop-mapreduce/* WordCount.java -d build -Xlint
$ jar -cvf word_count.jar -C build/ .Remove the previous results.
$ hadoop fs -rm -r -f /user/cloudera/wordcount/outputNow, if you run the application normally, the default behavior is to convert all words to lowercase before counting.
$ hadoop jar word_count.jar org.myorg.WordCount /user/cloudera/wordcount/input /user/cloudera/wordcount/outputWhen you look at the results, you'll see that all words have been converted to lowercase. Now you get three small elephants.
$ hadoop fs -cat /user/cloudera/wordcount/output/*
. . .
elephant 3
. . .To turn case sensitivity on, pass the system variable -Dwordcount.case.sensitive=true on the command line at runtime.
$ hadoop fs -rm -f -r /user/cloudera/wordcount/output
$ hadoop jar word_count.jar org.myorg.WordCount -Dwordcount.case.sensitive=true /user/cloudera/wordcount/input /user/cloudera/wordcount/outputView the results, and you get your big Elephant back, if that's important for your use case.
. . .
$ hadoop fs -cat /user/cloudera/wordcount/output/*
Elephant 1
elephant 2
. . .##WordCount Version Three You can further improve the quality of your results by filtering out information that is unnecessary or corrupts your desired output. You can create a list of stop words and punctuation, then have the application skip past them at runtime.
While it is not a perfect use case, this example demonstrates how to create a distributed cache file to make information available to all machines in a cluster. In practice, you would more likely just create a String[] variable in your Java class to store your stop words and punctuation and be done with it.
###Stop Making ¢'s Create a list of words and punctuation you want to omit from the output and save it in a text file. (If you're very serious about the problem of words and how to stop them, you can visit a site such as Google's stop-words page.)
Here are some suggested terms and punctuation for this example. Note that the punctuation marks must be preceded by an escape character. Create your list and save it in a file named stop_words.text.
a
an
and
but
is
or
the
to
.
,
!Put stop_words.txt into the Hadoop file system.
$ hadoop fs -put stop_words.txt /user/cloudera/wordcount/Now, you can update the code to use that list of stop-words to filter your input. You can see the complete source code at WordCount Version Three.
Let's look at the changes to the code.
Lines 3-9: Import classes for handling file I/O and set support.
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashSet;
import java.util.Set;Line 20: Import FileSplit, which is used to process a portion of an input file rather than the entire file at once.
import org.apache.hadoop.mapreduce.lib.input.FileSplit;Line 25: Import StringUtils, which, not surprisingly, has a shed load of utilities for working with strings in Hadoop. See the StringUtils Javadoc to see all of the handy methods this class provides. This example uses the stringifyException() method to convert any IOExceptions to a string before passing it to the System.error.println() method.
import org.apache.hadoop.util.StringUtils;Lines 40-48
for (int i = 0; i < args.length; i += 1) {
if ("-skip".equals(args[i])) {
job.getConfiguration().setBoolean("wordcount.skip.patterns", true);
i += 1;
job.addCacheFile(new Path(args[i]).toUri());
// this demonstrates logging
LOG.info("Added file to the distributed cache: " + args[i]);
}
}Line 54: This time, you can add the optional combiner class to your job configuration. The combiner is run on each of the mapper machines in the cluster to process information locally before sending it to the reducer machine. The combiner can do anything you want in order to prepare the intermediate values prior to sending them to the reducer.
In this case, setting the Reduce class as the combiner counts up the keys locally. For example, of sending <elephant, 1> <elephant, 1> to the reducer, the mapper machine combines them together as <elephant, 2> before forwarding the results to the reducer. Combining values before transmission can save a great deal of bandwidth and transfer time in most cases.
job.setCombinerClass(Reduce.class);Line 66: Add a variable to store an input chunk from a split file.
private String input;Line 67: Create a Set of strings called patternsToSkip. This is the list of punctuation and superfluous words to be removed from the final results.
private Set<String> patternsToSkip = new HashSet<String>();Lines 73-77: Convert information from split sources to a string for processing.
if (context.getInputSplit() instanceof FileSplit) {
this.input = ((FileSplit) context.getInputSplit()).getPath().toString();
} else {
this.input = context.getInputSplit().toString();
}Lines 80-83: If the system variable wordcount.skip.patterns is true, get the list of patterns to skip from a distributed cache file and forward the URI of the file to the parseSkipFile method.
if (config.getBoolean("wordcount.skip.patterns", false)) {
URI[] localPaths = context.getCacheFiles();
parseSkipFile(localPaths[0]);
}Lines 86-98: Get the distributed cache file from HDFS at the local URI. Read a line at a time until you run out of lines. Add each line to the set of strings to skip.
private void parseSkipFile(URI patternsURI) {
LOG.info("Added file to the distributed cache: " + patternsURI);
try {
BufferedReader fis = new BufferedReader(new FileReader(new File(patternsURI.getPath()).getName()));
String pattern;
while ((pattern = fis.readLine()) != null) {
patternsToSkip.add(pattern);
}
} catch (IOException ioe) {
System.err.println("Caught exception while parsing the cached file '"
+ patternsURI + "' : " + StringUtils.stringifyException(ioe));
}
}Lines 108-110: Modify the if statement so that if the word variable is empty or it contains one of the defined patterns to skip, the for loop continues without writing a value to the context.
if (word.isEmpty() || patternsToSkip.contains(word)) {
continue;
}###Running WordCount Version 3
Rebuild the application. You can enter these instructions at the command line, or you can use the Makefile command make jar.
$ rm -rf build word_count.jar
$ mkdir -p build
$ javac -cp /usr/lib/hadoop/*:/usr/lib/hadoop-mapreduce/* WordCount.java -d build -Xlint
$ jar -cvf word_count.jar -C build/ .Remove the previous results.
$ hadoop fs -rm -r -f /user/cloudera/wordcount/outputCreate a list of stop words. Put each stop word on a new line. Store them in a file named stop_words.text.
$ echo -e "a\\n\\nan\\nand\\nbut\\nis\\nor\\nthe\\nto\\n.\\n,\\n!" > stop_words.textRun the application with the -skip switch and the name of the stop_words.text file.
hadoop jar word_count.jar org.myorg.WordCount /user/cloudera/wordcount/input /user/cloudera/wordcount/output -skip stop_words.textNow the results provide the most useful output so far, converting all words to lowercase, omitting the punctuation and less significant words. You can continue to tweak the code to meet your particular business needs.
hadoop fs -cat /user/cloudera/wordcount/output/*
anything 1
are 1
at 1
bad 1
because 1
cling 1
core 1
data 1
does 1
elegant 2
element 1
elephant 3
extraneous 1
fellow 1
forgets 1
gentle 1
gets 1
group 1
hadoop 3
hdfs 1
he 3
helps 1
him 1
his 1
hive 1
impala 1
in 1
king 2
lets 1
mad 1
mellow 1
never 2
plays 1
sqoop 1
thing 1
thrive 1
useful 1
well 1
what 1
with 1
wonderful 1
yellow 2