Originally implemented in tensorflow 1.14 by OpenAi :- "openai/gpt-2". OpenAi GPT-2 Paper:-"Language Models are Unsupervised Multitask Learners"
Forked from Abhay Kumars implementation: https://github.com/akanyaani/gpt-2-tensorflow2.0
This is OpenAi GPT-2 implementation in Tensorflow 2. It includes the complete processing chain:
- Vocab generation + preprocessing raw text data in any language
- Creating GPT2 models with different parametrization
- Multi GPU training GPT2 model
- Sequence generation with trained model
The reached performance and quality of a trained model with this implementation needs still to be evaluated.
Requirements
- python >= 3.6
- setuptools==41.0.1
- ftfy==5.6
- tqdm==4.32.1
- Click==7.0
- sentencepiece==0.1.83
- tensorflow-gpu==2.1.0
- numpy==1.16.4
Setup
$ git clone https://github.com/kinred/gpt2-tf2
$ cd gpt2-tf2
$ pip install -r requirements.txt
Vocab generation + preprocessing raw text data in any langauge
You can pre-train the model using sample data available in repository or you can download the data using this github repo https://github.com/eukaryote31/openwebtext
$ python pre_process.py --help
Options:
--text-dir TEXT path to raw text files [default: /data/scraped]
--data-dir TEXT directory where training data will be stored
[default: /data]
--vocab-size INTEGER byte pair vocab size [default: 50000]
--max-seq-len INTEGER maximum sequence length [default: 1024]
--help Show this message and exit.
Creating the vocabulary and trainign data with the included example openwebtext data
>> python pre_process.py --text-dir ./data/scrapped --data-dir ./data
Creating GPT2 models with different parametrization
The model creation can be done with following script:
$ python create_model.py --help
Options:
--model-dir TEXT Directory to store created model [default:
./model]
--num-layers INTEGER No. of decoder layers [default: 8]
--embedding-size INTEGER Embedding size [default: 768]
--num-heads INTEGER Number of heads [default: 8]
--max-seq-len INTEGER Seq length [default: 1024]
--dff INTEGER Conv filter size (experimental) [default: 3072]
--vocab-size INTEGER Vocab size [default: 50000]
--optimizer TEXT optimizer type [default: adam]
--help Show this message and exit.
The --max-seq-len and --vocab-size should be set to the same values as used in pre_process.py
To create a model that has comparable setup as the GPT2 117M model use:
>> python create_model.py --model-dir ./model_small --num-heads 12 --num-layers 12 --embedding-size 768
For a model comparable to GPT2 345M model use:
>> python create_model.py --model-dir ./model_medium --num-heads 16 --num-layers 24 --embedding-size 1024
For GPT2 774M:
>> python create_model.py --model-dir ./model_large --num-heads 20 --num-layers 36 --embedding-size 1280
Multi GPU training GPT2 model
The created model can then be trained with the pre processed data and vocabulary:
$ python train_gpt2.py --help
Usage: train_gpt2.py [OPTIONS]
Options:
--model-dir TEXT Directory to load model [default: ./model]
--data-dir TEXT training data directory [default: ./data]
--batch-size INTEGER batch size [default: 16]
--learning-rate FLOAT learning rate [default: 0.001]
--distributed BOOLEAN distributed training [default: False]
--mxp BOOLEAN enable mixed precission training [default: False]
--help Show this message and exit.
To train on a single GPU with mixed precission support:
>> python train_gpt2.py --model-dir ./model_small --batch-size=16 --mxp True
Distributed training on multiple GPUs.
>> python train_gpt2.py --model-dir ./model_small --distributed True
Start TensorBoard through the command line.
$ tensorboard --logdir /log
The optimal training time, learning rate etc. needs to be evaluated....
Sequence generation with trained model
$ python sequence_generator.py --help
Options:
--model-dir TEXT Model Path [default: ./model]
--vocab TEXT Vocab [default: ./data/bpe_model.model]
--seq-len INTEGER seq_len [default: 512]
--temperature FLOAT seq_len [default: 1.0]
--top-k INTEGER seq_len [default: 8]
--top-p FLOAT seq_len [default: 0.9]
--nucleus_sampling BOOLEAN seq_len [default: True]
--context TEXT Context given to model [default: ]
--help Show this message and exit.
To generate some text with the trained model:
python3 sequence_generator.py --model-dir ./model_small --context "Once upon a time there was a"
References:
- "Openai/gpt-2"
- "Huggingface pytorch-transformers"
- "Tensorflow Transformers"
- "The Illustrated GPT-2 "
Contribution
- Your issues and PRs are always welcome.
Author
- Abhay Kumar
- Author Email : [email protected]
- Follow me on Twitter
License
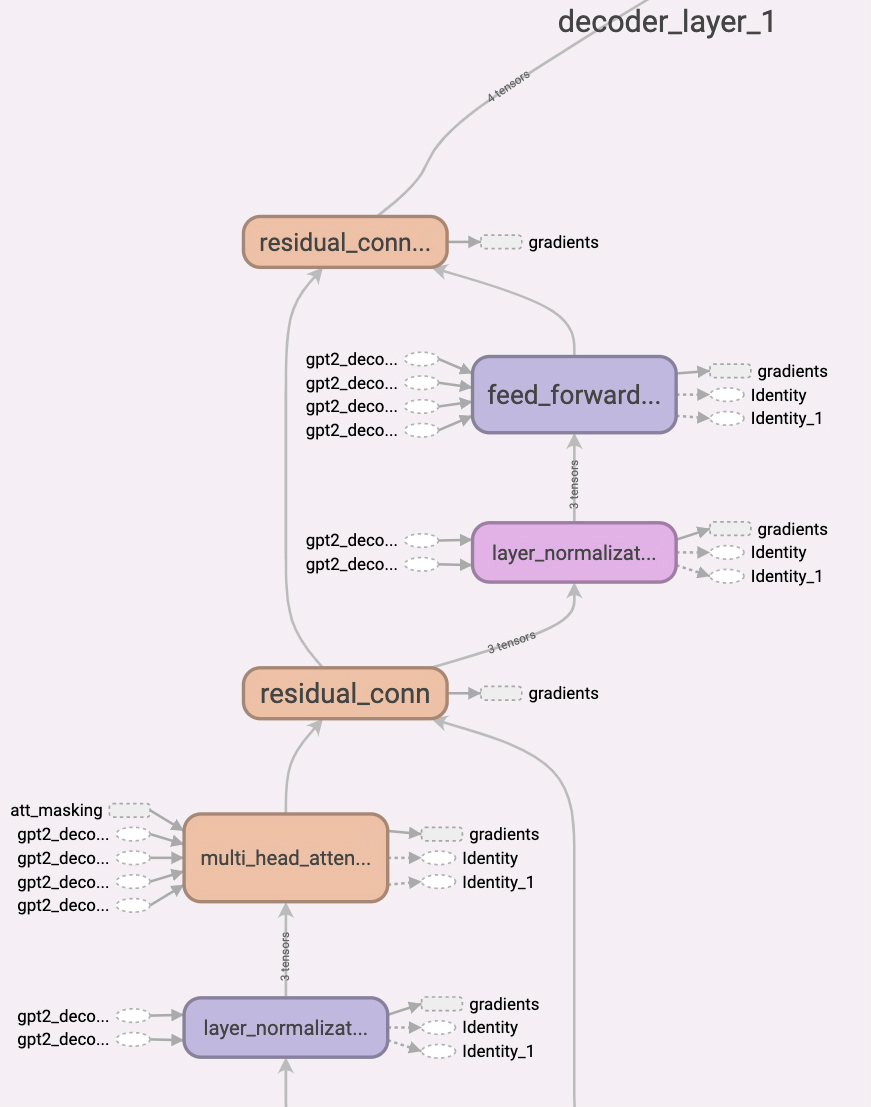
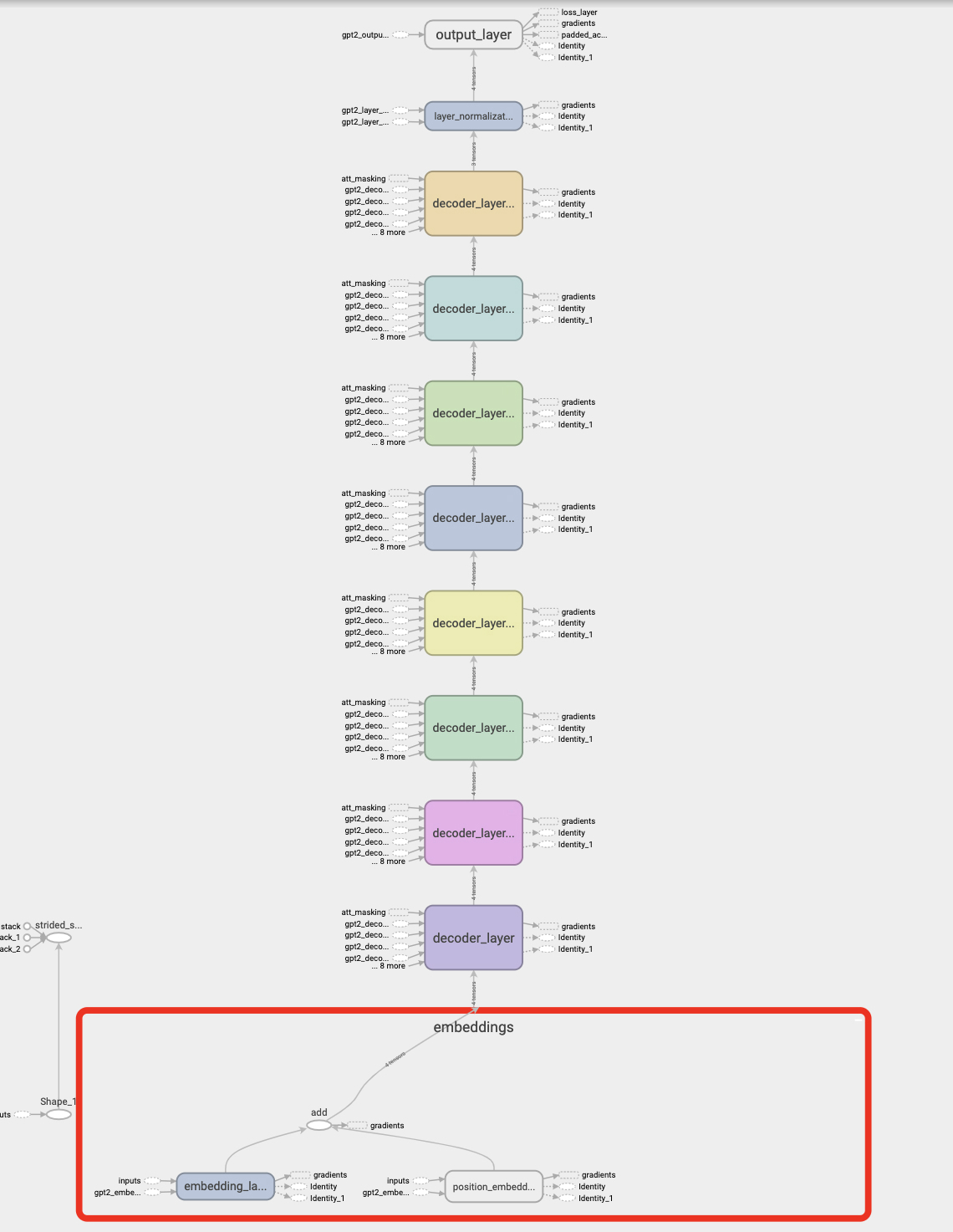
Computation Graph of GPT-2 Model.