


DeepEval is a simple-to-use, open-source LLM evaluation framework for LLM applications. It is similar to Pytest but specialized for unit testing LLM applications. DeepEval incorporates the latest research to evaluate LLM outputs based on metrics such as hallucination, answer relevancy, RAGAS, etc., which uses LLMs and various other NLP models that runs locally on your machine for evaluation.
Whether your application is implemented via RAG or fine-tuning, LangChain or LlamaIndex, DeepEval has you covered. With it, you can easily determine the optimal hyperparameters to improve your RAG pipeline, prevent prompt drifting, or even transition from OpenAI to hosting your own Llama2 with confidence.
Want to talk LLM evaluation? Come join our discord.
- Large variety of ready-to-use LLM evaluation metrics powered by LLMs (all with explanations), statistical methods, or NLP models that runs locally on your machine:
- G-Eval
- Summarization
- Answer Relevancy
- Faithfulness
- Contextual Recall
- Contextual Precision
- RAGAS
- Toxicity
- Hallucination
- Toxicity
- Bias
- etc.
- Evaluate your entire dataset in bulk in under 20 lines of Python code in parallel. Do this via the CLI in a Pytest-like manner, or through our
evaluate()function. - Easily create your own custom metrics that are automatically integrated with DeepEval's ecosystem by inheriting DeepEval's base metric class.
- Automatically integrated with Confident AI for continous evaluation throughout the lifetime of your LLM (app):
- log evaluation results and analyze metrics pass / fails
- compare and pick the optimal hyperparameters (eg. prompt templates, chunk size, models used, etc.) based on evaluation results
- debug evaluation results via LLM traces
- manage evaluation test cases / datasets in one place
- track events to identify live LLM responses in production
- real-time evaluation in production
- add production events to existing evaluation datasets to strength evals over time
(Note that while some metrics are for RAG, others are better for a fine-tuning use case. Make sure to consult our docs to pick the right metric.)
Let's pretend your LLM application is a RAG based customer support chatbot; here's how DeepEval can help test what you've built.
pip install -U deepeval
Although optional, creating an account on our platform will allow you to log test results, enabling easy tracking of changes and performances over iterations. This step is optional, and you can run test cases even without logging in, but we highly recommend giving it a try.
To login, run:
deepeval login
Follow the instructions in the CLI to create an account, copy your API key, and paste it into the CLI. All test cases will automatically be logged (find more information on data privacy here).
Create a test file:
touch test_chatbot.pyOpen test_chatbot.py and write your first test case using DeepEval:
import pytest
from deepeval import assert_test
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
def test_case():
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
assert_test(test_case, [answer_relevancy_metric])Set your OPENAI_API_KEY as an enviornemnt variable (you can also evaluate using your own custom model, for more details visit this part of our docs):
export OPENAI_API_KEY="..."
And finally, run test_chatbot.py in the CLI:
deepeval test run test_chatbot.py
Your test should have passed ✅ Let's breakdown what happened.
- The variable
inputmimics user input, andactual_outputis a placeholder for your chatbot's intended output based on this query. - The variable
retrieval_contextcontains the relevant information from your knowledge base, andAnswerRelevancyMetric(threshold=0.5)is an out-of-the-box metric provided by DeepEval. It helps evaluate the relevancy of your LLM output based on the provided context. - The metric score ranges from 0 - 1. The
threshold=0.5threshold ultimately determines whether your test has passed or not.
Read our documentation for more information on how to use additional metrics, create your own custom metrics, and tutorials on how to integrate with other tools like LangChain and LlamaIndex.
Alternatively, you can evaluate without Pytest, which is more suited for a notebook environment.
from deepeval import evaluate
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
evaluate([test_case], [answer_relevancy_metric])DeepEval is extremely modular which makes it extremely easy for anyone to use any of our metrics. Continuing with the previous example:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
answer_relevancy_metric.measure(test_case)
print(answer_relevancy_metric.score)
# Most metrics also offer an explanation
print(answer_relevancy_metric.reason)Note that some metrics are for RAG pipelines, while others are for fine-tuning. Make sure to use our docs to pick the right one for your use case.
In DeepEval, a dataset is simply a collection of test cases. Here is how you can evaluate things in bulk:
import pytest
from deepeval import assert_test
from deepeval.metrics import HallucinationMetric, AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
from deepeval.dataset import EvaluationDataset
first_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
second_test_case = LLMTestCase(input="...", actual_output="...", context=["..."])
dataset = EvaluationDataset(test_cases=[first_test_case, second_test_case])
@pytest.mark.parametrize(
"test_case",
dataset,
)
def test_customer_chatbot(test_case: LLMTestCase):
hallucination_metric = HallucinationMetric(threshold=0.3)
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.5)
assert_test(test_case, [hallucination_metric, answer_relevancy_metric])# Run this in the CLI, you can also add an optional -n flag to run tests in parallel
deepeval test run test_<filename>.py -n 4Alternatively, although we recommend using deepeval test run, you can evaluate a dataset/test cases without using our Pytest integration:
from deepeval import evaluate
...
evaluate(dataset, [answer_relevancy_metric])
# or
dataset.evaluate([answer_relevancy_metric])We offer a free web platform for you to:
- Log and view all test results / metrics data from DeepEval's test runs.
- Debug evaluation results via LLM traces
- Compare and pick the optimal hyperparameteres (prompt templates, models, chunk size, etc.).
- Create, manage, and centralize your evaluation datasets.
- Track events in production and augment your evaluation dataset for continous evaluation in production.
- Track events in production and view live evaluation results over time.
Everything on Confident AI, including how to use Confident is available here.
To begin, login from the CLI:
deepeval loginFollow the instructions to log in, create your account, and paste your API key into the CLI.
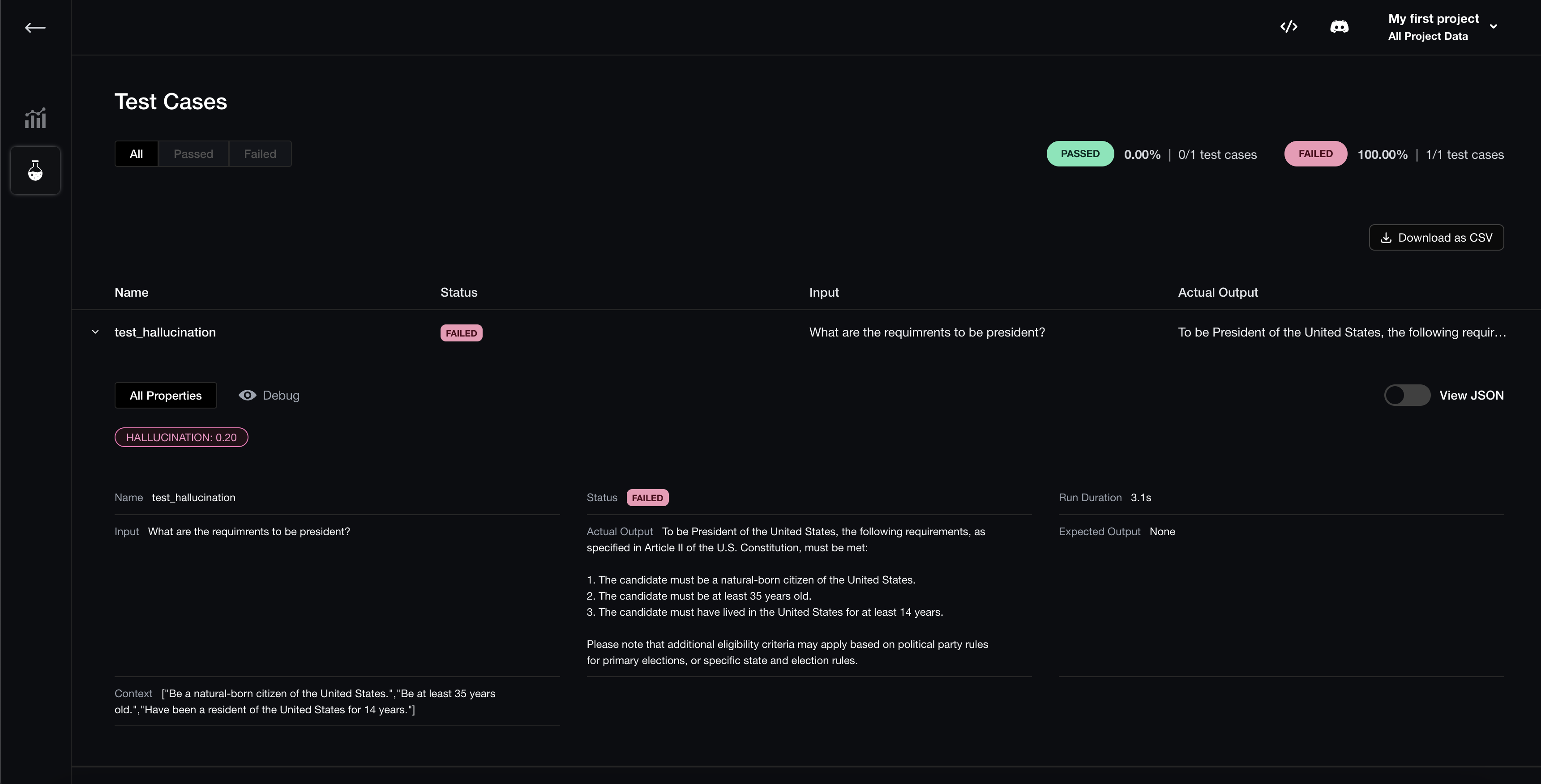
Now, run your test file again:
deepeval test run test_chatbot.pyYou should see a link displayed in the CLI once the test has finished running. Paste it into your browser to view the results!
Please read CONTRIBUTING.md for details on our code of conduct, and the process for submitting pull requests to us.
Features:
- Implement G-Eval
- Referenceless Evaluation
- Production Evaluation & Logging
- Evaluation Dataset Creation
Integrations:
- lLamaIndex
- langChain
- Guidance
- Guardrails
- EmbedChain
Built by the founders of Confident AI. Contact [email protected] for all enquiries.
DeepEval is licensed under Apache 2.0 - see the LICENSE.md file for details.