本项目使用PyTorch复现论文:Listen, Attend and Spell, 实现了一个端到端的语音识别, ASR的深度模型.
同时,也提供一个中文普通话的语音识别 ASR 的预训练模型.
- 数据集
- LibriSpeech for English Speech Recognition
- AISHELL-Speech for Chinese Mandarin Speech Recognition
- 用法
- generate vocab file
- 训练
- 验证
- 推理
- Demo
Improving End-to-End Models For Speech Recognition
The LAS architecture consists of 3 components. The listener encoder component, which is similar to a standard AM, takes the a time-frequency representation of the input speech signal, x, and uses a set of neural network layers to map the input to a higher-level feature representation, henc. The output of the encoder is passed to an attender, which uses henc to learn an alignment between input features x and predicted subword units {yn, … y0}, where each subword is typically a grapheme or wordpiece. Finally, the output of the attention module is passed to the speller (i.e., decoder), similar to an LM, that produces a probability distribution over a set of hypothesized words.
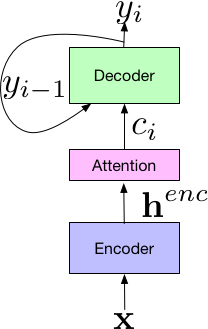
Components of the LAS End-to-End Model.
This repository contains:
- 模型代码复线论文的算法模型.
- 创建 vocab 文件, 使用该方法来生成自己的 vocab 文件 for 数据集.
- 训练代码 来训练模型.
- 验证代码 来验证模型.
pip install -r requirements.txt首先, 基于数据集的 transcripts 文件生成vocab 文件. 请参考 代码 generate_vocab_file.py. 如果你想训练 aishell 数据集, 你可以直接使用我写好的 generate_vocab_file_aishell.py.
python generate_vocab_file_aishell.py --input_file $DATA_DIR/data_aishell/transcript_v0.8.txt --output_file ./aishell_vocab.txt --mode character --vocab_size 5000它将创建好一个 vocab 文件, 在目录下命名为 aishell_vocab.txt.
在训练之前, 需要重写自己的dataset加载器的代码 in package dataset.
如果想使用我写好的aishell dataset 的加载器代码, 需要注意数据集里的 transcripts file 的路径配置,见 data/aishell.py 的第26行:
src_file = "/data/Speech/SLR33/data_aishell/" + "transcript/aishell_transcript_v0.8.txt"当一切都准备好.
就可以开始训练了:
python main.py --config ./config/aishell_asr_example_lstm4atthead1.yaml你可以自定义自己的配置文件, 可以参考 config/aishell_asr_example_lstm4atthead1.yaml
特别注意的变量: corpus's path & vocab_file
python main.py --config ./config/aishell_asr_example_lstm4atthead1.yaml --test在数据集AISHELL-Dataset上训练的一个中文语音识别 ASR 模型的预训练权重文件
download from Google Drive
推理:
python infer.py- Listen, Attend and Spell, W Chan et al.
- Neural Machine Translation of Rare Words with Subword Units, R Sennrich et al.
- Attention-Based Models for Speech Recognition, J Chorowski et al.
- Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks, A Graves et al.
- Joint CTC-Attention based End-to-End Speech Recognition using Multi-task Learning, S Kim et al.
- Advances in Joint CTC-Attention based End-to-End Speech Recognition with a Deep CNN Encoder and RNN-LM, T Hori et al.
If this project help you reduce time to develop, you can give me a cup of coffee :)
AliPay(支付宝)

WechatPay(微信)

MIT © Kun