{kind=link}
Nota: Fork del proyecto kiwenlau/hadoop-cluster-docker adaptado para usar la imagen de base recomendada por la documentación de Hadoop: sequenceiq/hadoop-docker (soporta diferentes versiones)
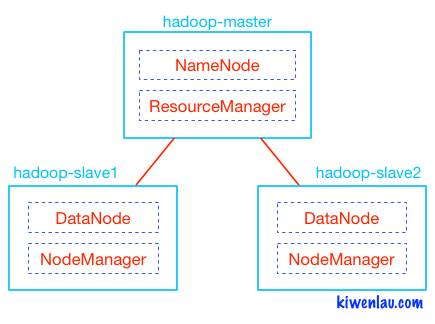
Modo: Master/slave (no es autodiscovery) Reference: http://www.michael-noll.com/tutorials/running-hadoop-on-ubuntu-linux-multi-node-cluster/#confslaves-master-only
$ docker network create --driver=bridge hadoop
$ ./build-image.sh
Parte de la imagen base mencionada y configura ssh, los nodos esclavos, la configuración general, etc.
$ ./start-container.sh
Crea el container master y los slaves con configuraciones diferentes, usando la misma red. Cuando inicia el master, bindea el puerto 50070 y el 8088 con el host.
Abre un bash en el master.
TIP: agregar --rm para que los containers sean temporarios.
En caso de agregar más nodos, actualizar el archivo config/slaves
(desde el bash del master)
$ ./start-hadoop.sh
Para monitorear, con el browser conectarse a: http://localhost:50070
Paper original sobre Map Reduce (Google) Simplified Data Processing on Large Clusters
Dado un input, cuenta el número de ocurrencias para cada palabra.
$ VERSION=2.7.0
$ cd /usr/local/hadoop-$VERSION
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-$VERSION.jar grep input output 'dfs[a-z.]+'
(o correr ~/run-wordcount.sh)
$ bin/hdfs dfs -get output output
$ cat output/*
$ bin/hdfs dfs -cat output/*
$ ./run-wordcount.sh
output
input file1.txt:
Hello Hadoop
input file2.txt:
Hello Docker
wordcount output:
Docker 1
Hadoop 1
Hello 2

NOTA: Testeado con Hadoop versión 2.7.0. En caso de que la imagen docker cambie de versión, será necesario actualizar varios scritps. Buscar donde con 'fgrep 2.7.0 -R .'