`
Markov-Word-Generator is a Python library for generating random, credible, and plausible words based on a list of words. It estimates the probability of the next character in a word based on the frequency of the previous N characters, using Markov chains. This uses Markov chains
pip install markov-word-generatorTo generate random words that sound like real words, this library analyzes character distribution among a corpus in a given language. It creates a mapping table for character combinations and their associated frequency in the corpus. By estimating the probability of a character based on the previous characters, the library generates words that mimic real language patterns.
Here are heatmaps showing the distribution of each character (column) given the previous one (row).
$= End of word^= Start of a word
In English:
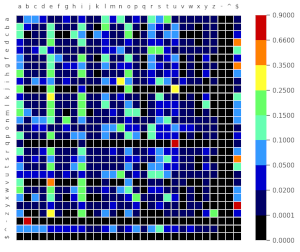
And in French:
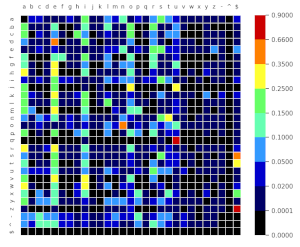
Estimating the probability of a character to appear given the probability of the given previous one works fine but is still hazardous. We can increase the likelihood of the world sounds true by looking at the next N previous characters.
The generator will parse an input text file containing one word per line (dictionary), count each character occurrence based on the occurrence of the N previous ones create a mapping table for each character-combination and its associated frequency in the corpus.
To generate a random word in English by predicting the probability of each new character based on the last 4 characters, you can use the following code:
from markov_word_generator import MarkovWordGenerator, WordType
# Generate a random word in English by predicting the probability of each new character based on its last 4 last characters
generator = MarkovWordGenerator(
markov_length=4,
language='en',
word_type=WordType.WORD,
)
print(generator.generate_word())output:
rebutaneously
-
MarkovWordGenerator():
markov_length: (int): The number of previous characters to consider.language: (str): The language to use for word generation. Must be part of the supported languages.word_type: (str): The type of word to generate. Must be part of the supported word types.dictionary_filename: (str): The corpus to parse for character frequency analysis. Must be used only iflanguageandword_typeare not set.ignore_accents: (bool): If set to True, accents are ignored during parsing. Default to False
-
generate_word()
- seed: (str): Seed to generate a word starting with the given seed. Default to empty
from markov_word_generator import MarkovWordGenerator, WordType, AllowedLanguages
# Generate a random German name by predicting the probability of each new character based on its last 3 last characters
generator = MarkovWordGenerator(
markov_length=3,
language=AllowedLanguages.DE,
word_type=WordType.NAME,
)
print(generator.generate_word())ludgerten
You can access the list of supported languages and word types using the following functions:
import markov_word_generator
# List supported languages
print(markov_word_generator.get_supported_languages())
# ['EN', 'FR', 'DE', 'FI', 'IT', 'PT', 'SE']
# List supported word_type
print(markov_word_generator.get_supported_word_types())
# ['WORD', 'NAME']More languages and word types (plants, movie names, cities...) can be added in the future.
- The higher the number of characters N we take into account, the more credible the word will be. We may end up with already existing words (see Impact of the markov_length parameter below).
- Lowering N will lead to words that sound less real. Some words will also either very short (1-2 chars) or very long (>20chars)
from markov_word_generator import MarkovWordGenerator, WordType, AllowedLanguages
generator = MarkovWordGenerator(
markov_length=N, # N=1,2,3,4 or 5 in following examples
language=AllowedLanguages.EN,
word_type=WordType.WORD
)
for i in range(0, 10):
print(generator.generate_word())output:
eroun
unteticakreatintes
sucle
erarums
eablatirlac
e
ghils
rllig
beseleforuat
de
output:
malle
dallintathilight
boaddly
nobtiousle
ing
alaymplaings
rusle
sprevircirdbages
bant
ritablegruphicalls
output:
blungalinther
super
solder
degreetricked
mittlessly
out
hearf
fracertory
gyny
locious
output:
authering
negligented
manoeistical
bleat
lover
confusions
dest
hand
display
entwinkle
output:
significative
contention
grandmaidens
aidesdecamped
paralleled
contradicate
thereby
numskull
crises
battlegro
Empirically generating 5000 random words for each of the tests and checking the percentage of them which do exist as actual valid words. 10 tests have been running. From N=1 to N=5 in both English and French languages Results are the following
| N\Language | EN | FR* |
|---|---|---|
| 1 | 4.61% | 6.15% |
| 2 | 8.89% | 10.60% |
| 3 | 14.80% | 10.04% |
| 4 | 33.08% | 33.88% |
| 5 | 62.84% | 65.68% |
Empirical measurements of the percentage of output words from the generator that are real words (exists in the dictionary) based on the number of characters N we take into account in the markov_chain over 5000 samples *accents have been ignored in benchmarks in French
From N=5, there are more than 50% of chances to generate an existing word.
| EN | FR | ES | DE | IT | SE |
|---|---|---|---|---|---|
| duplicables | chouchonnées | inflamandando | regenfreunden | scommissari | medmännens |
| feathenism | fumigents | diacontenderá | rechtsbeleuchtes | insortiti | metallösningens |
| convolutionalist | saponisassiez | transnacionarán | unerschieben | immalintenziale | stationskligt |
| jinglehand | pareraient | abundeo | unstimme | pronometro | arbetslöftenas |
| stariness | toniciens | encuestionó | überredete | acconciliani | utredningsviljande |
| trellish | challe | abombearán | zwischere | afferrofilia | tributionsverktygs |
| subsidiariest | potames | banderolasteis | plädiertem | dispiacerete | slappningarnas |
| discourself | rudoyers | construéis | wolken | trisecchererai | tidsnärings |
| melanchorist | reluisionnés | desagüense | kompetentenzeichnen | riappavia | spagatellig |
| cleavagery | sacagneuse | desvergonzaremos | dümmst | sgancializzando | yngstakternas |
| EN | FR | ES | DE | IT | SE |
|---|---|---|---|---|---|
| charlena | arian | sandro | germann | severonica | brittan |
| sorrell | clementin | uliseo | gunde | evarissa | kristin |
| austinee | théophie | teofilomena | werthold | florena | frid |
| hardine | augustine | herina | hannelia | tizia | torstein |
| shantal | jeanninette | amilo | helmar | leonardinanda | gitta |
| kristian | flavier | leandra | tatja | fortunatale | kerstina |
| lessica | isidonie | dolorencio | sieghardt | simondo | sigfrida |
| reana | clothaire | dion | anelia | geltrudenzio | thorsten |
| leanoreen | fabriel | anuncia | trud | battia | gunils |
| roslyn | bastienne | calis | eleonhard | lorentina | jerkel |
Given other types of dictionaries, generator can create random words in some specific topics: Random jobs, random plants, random animals, random cities...