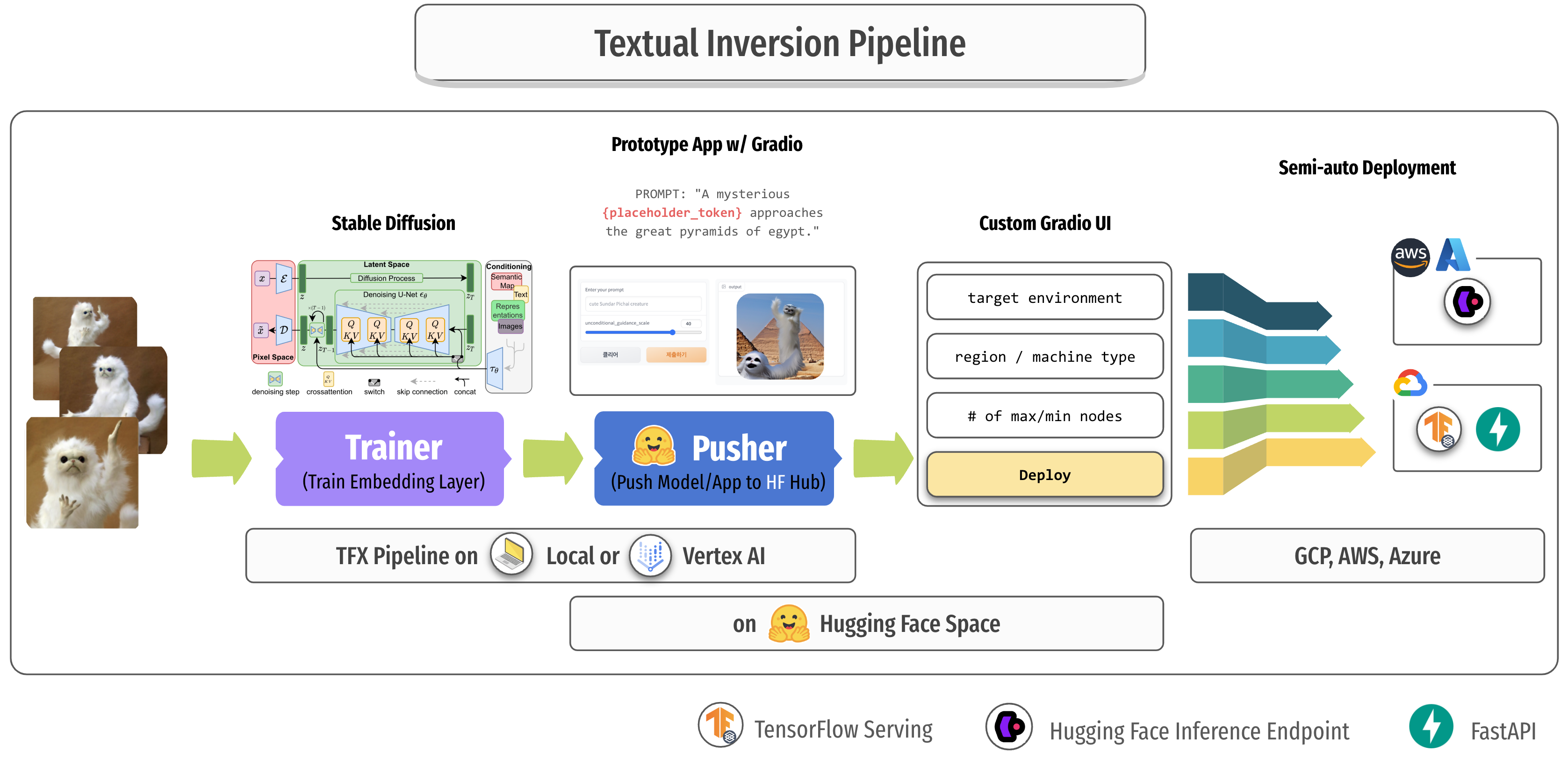
This repository demonstrates how to manage multiple models and their prototype applications of fine-tuned Stable Diffusion on new concepts by Textual Inversion.

In this section, I am going to explain the whole workflow and how to use it. There are some parts that need to be done manually, and there are some parts that are done automatically, so I will indicate each cases with the letter [M] and [A].
- [M] create a new branch and checkout
- the branch name is going to be the name of the pipeline, Hugging Face Model repository, and Hugging Face Space repository for easier tracking.
- [M] upload your own images in the
training_pipeline/datadirectory - [M] serialize the images with
TFRecordformat by running the following command, then the generatedTFRecordfile will be placed intraining_pipeline/tfrecords.$ python data/create_tfrecords.py
- [M] customize the values of the following variables in
training_pipeline/pipeline/configs.py.- (optional)
TRAINING_EPOCH: how many epochs to train PLACEHOLDER_TOKEN: a unique token for your own conceptINITIALIZED_TARGET_TOKEN: an existing token. the weights of the corresponding token is going to be used as the initial weights of your own token(PLACEHOLDER_TOKEN)
- (optional)
- [M] (optional) customize title and emoji of the Hugging Face Space application in
training_pipeline/huggingface/apps/gradio/textual_inversion/README.md. - [M] commit and push the changes
- [M] run the
Trigger Training PipelineGitHub Action workflow. Make sure you set the correct branch to run it on.- GitHub Action looks up two GitHub Secrets to fill some info in the
configs.pyYOUR_GCP_PROJECT_ID: the key of this Secret should exactly match your GCP Project ID except that dashes are replaced with underscores. The value of the Secret should be the GCP credentials in JSON format.HF_ACCESS_TOKEN: the value of this Secret should be the Hugging Face Access token.
- GitHub Action looks up two GitHub Secrets to fill some info in the

- [A]
Trigger Training PipelineGitHub Action workflow is triggered, and it does the following jobs.- retreive branch name and replace
$PIPELINE_NAMEwith it. - install python packages via
training_pipeline/requirements.txt. - authenticate Google Cloud with
google-github-actions/authGitHub Action, theYOUR_GCP_PROJECT_IDGitHub Action Secret is going to be used here. - replace
$HF_ACCESS_TOKENinsideconfigs.pywith theHF_ACCESS_TOKENGitHub Action Secret. - create TFX pipeline and build a new Docker image with the current code base.
- run TFX pipeline on Vertex AI platform in GCP.
- retreive branch name and replace

- [A] TFX pipeline on Vertex AI handles the following jobs in a row.
ImportExampleGencomponent takes input(training)TFRecorddata stored undertraining_pipeline/tfrecordsdirectory.Transformcomponent transform the TFRecord data fromImportExampleGeninto appropriate shapes with the help ofImportSchemaGen.ImportSchemaGensimply loads up schema information defined in Protocol Buffer Text format undertraining_pipeline/pipeline/schema.pbtxt.Trainercomponent trains the embedding layers insidetext_encoderof Stable Diffusion with the training data fromTransformcomponent. It trains in Vertex AI Training, and the worker spec is defined inconfigs.py(default to use a single A100 instance), and thetext_encoderwith the trained additional embedding layers is saved asSavedModelformat.HFPushercomponent pushestext_encoderto a repository of Hugging Face Models. If there is no repository named as the pipeline name under your account, one will be created. Whenever a model is pushed to the same repository, the model will be pushed to the new branch namev.... It additionally pushes the files undertraining_pipeline/huggingface/models/custom_handler.HFPusheralso pushes the source codes undertraining_pipeline/hugging_face/apps/gradio/textual_inversionto a repository of Hugging Face Spaces. If there is no repository named as the pipeline name under your account, one will be created. Space application codes will always be replaced in themainbranch in every pushes.- some special strings inside files in
training_pipeline/huggingface/models/custom_handlerandtraining_pipeline/hugging_face/apps/gradio/textual_inversionwill be replaced at runtime such as the model repository name, model version(branch name), commit SHA, and unique placeholder token.

- [M] Change the Hardware spec of the Hugging Face Space to
T4 smallsince Stable Diffusion can not be run on CPU instance.

- [M] Play with the app under
Playgroundtab.

- [M] Deploy the Stable Diffusion with the current version of
text_encoderon Hugging Face Inference Endpoint underDeploy on 🤗 Endpointtab.- Your account name, Hugging Face access token, and the Endpoint name should be filled.
- After clicking
Submitbutton, check out the Endpoint creation progress viahttps://ui.endpoints.huggingface.co/endpoints.

- Stable Diffusion (KerasCV official) -
keras_cv==0.4.0 - Machine Learning Pipeline (TensorFlow Extended) -
tfx==1.12.0 - Cloud ML Pipeline (Vertex AI Pipeline)
- Cloud ML Training (Vertex AI Training)
- Automated Pipeline Triggering (GitHub Action)
- Model Registry (Hugging Face Models)
- Hosting Prototype Application (Hugging Face Spaces)
- Stable Diffusion Deployment (Hugging Face Inference Endpoint)
I refered to the example of Textual Inversion from the Keras official tutorial.