{kind=link}
This work is an addition to the paper "Link predictability classes in complex networks" by Stavinova et al.
In this paper, we study how the observed quality of a link prediction model applied to a part of a node-attributed network can be further used for the analysis of the other part of the network.
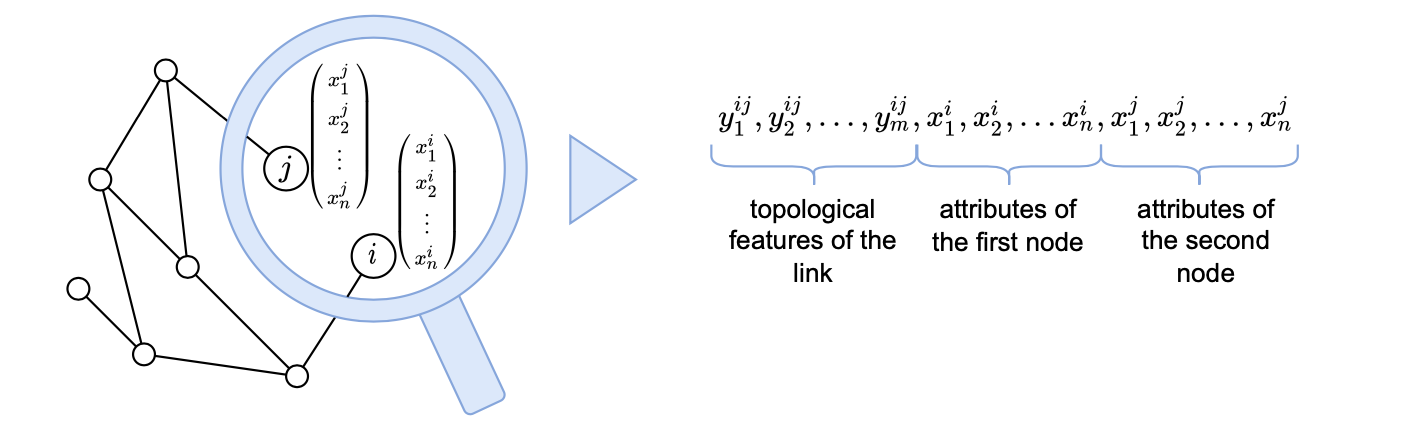
Namely, we first show that it can be determined for a part of the network the usage of which features (topological and attributive) of node pairs lead to a certain level of link prediction quality.
Based on it, we construct a link predictability (prediction quality) classifier for the network node pairs. This is further used in the other part of the network for controlling the link prediction quality typical for the model and the network, in fact, without performing the actual link prediction.
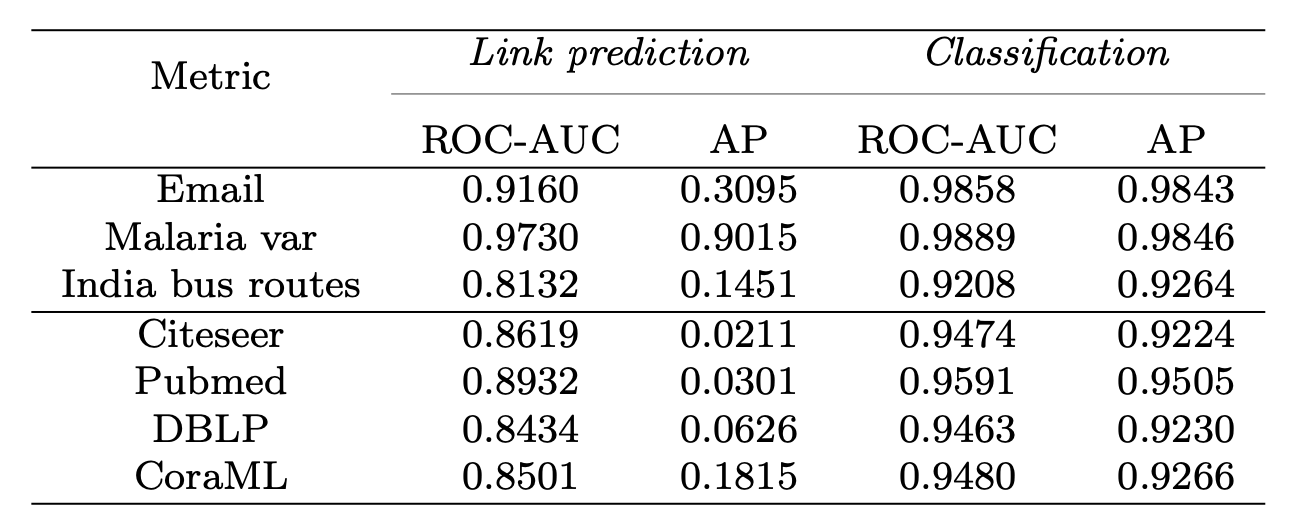
Experiments with synthetic and real-world networks show a good performance of the proposed pipeline: the mean ROC-AUC value is 0.9566, and the mean AP value is 0.9454 for the link predictability classes identification model (among all tested real networks).
Furthermore, the pipeline allows for finding a reasonable trade-off between the time consumption and quality levels related to link prediction for large node-attributed networks.
We use four types of datasets in the study:
- Real-world non attributed networks (Email network, India bus routes ...)
- Synthetic non-attributed (generated with LFR)
- Real-world attributed networks (Citeseer, Pubmed ...)
- Synthetic attributed networks (generated with acMark )
All of the synthetic data can be generated in our code using the specified .py scripts. Example for LFR generation:
python lib/data/synthetic/LFR/generation.py
Datasets also require re-formatting and topological feature calculation. We call this process 'pre-processing'. When running experiments preprocessing happens automatically, but if you want to cache the results for multiple runs you can run pre-processing manually.
In order to choose the datasets you want to pre-process, you need to edit the script as specified: add a tuple with info
about the dataset (formatter class, 'use attributes' flag, data path and name) to the list of datasets data.
There are three types of data formatters:
- RealWorldAttrFormatter
- RealWorldNonAttrFormatter
- SyntheticFormatter
data.append(
(RealWorldAttrFormatter, True, {'path': DATA_PATH + 'real_world_data/', 'dataset_name': f'citeseer.npz'})
)Then run the script:
python lib/pre_compute_datasets.py
To run the experiments you need to do the similar operation: add tuple witch describes
the experiment into list of datasets data: (formatter class, experiment class, model, 'use attributes' flag,
data path and name).
Depending on types of graphs you want to get you can use different types of experiments:
- Experiment
- FeatureSelectionExperiment
- VaryingFeatureSelection
data.append(
(RealWorldAttrFormatter, FeatureSelectionExperiment, NNModel,
True, {'path': DATA_PATH + 'real_world_data/', 'dataset_name': f'citeseer.npz'})
)Then run the script:
python lib/main.py
Python 3.9 + all of the required packages. Also, Graphviz is required to plot Keras models.
pip install requirements.txt
@incollection{Stavinova2022,
doi = {10.1007/978-3-030-93409-5_32},
url = {https://doi.org/10.1007/978-3-030-93409-5_32},
year = {2022},
publisher = {Springer International Publishing},
pages = {376--387},
author = {Elizaveta Stavinova and Elizaveta Evmenova and Andrey Antonov and Petr Chunaev},
title = {Link Predictability Classes in~Complex Networks},
booktitle = {Complex Networks {\&} Their Applications X}
}