The package implements Pruned Cross-Validation technique, which verifies whether all folds are worth calculating. It's components may be used as a standalone methods or as a part of hyperparameter optimization frameworks like Hyperopt or Optuna.
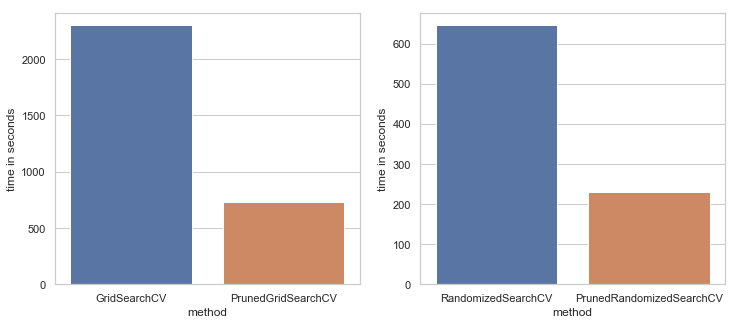
It proved to be more less three times faster than Scikit-Learn GridSearchCV and RandomizedSearchCV yielding the same results (see benchmarks section).
You can find a broader overview of the motivation an methodology under this directory or alternatively on Medium.
The idea was to improve speed of hyperparameter optimization. All the methods which are based on Cross-Validation require big folds number (8 is an absolute minimum) to assure that the surrogate model (whether it's GridSearch, RandomSearch or a Bayesian model) does not overfit to the training set.
On the other hand Optuna proposes a mechanism of pruned learning for Artificial Neural Networks and Gradient Boosting Algorithms. It speeds the search process greatly but one issue with the method is that is prunes the trials based on a single validation sample. With relatively small datasets the model's quality variance may be high and lead to suboptimal hyperparameters choices. In addition it can only help to optimize an estimator and not the whople ML pipeline.
Pruned-cv is a compromise between brut-force methods like GridSearch and more elaborate, but vulnerable ones like Optuna's pruning.
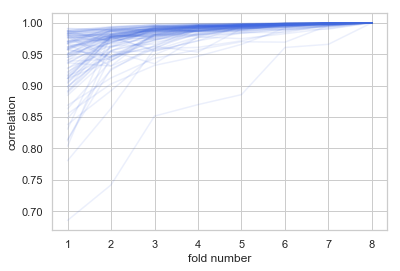
You can see example of correlations between cumulative scores on folds with the final score:
You may find the whole study notebook here.
The package uses the fact that cumulative scores are highly correlated with the final score. In most cases after calculating 2 folds it's possible to predict the final score very accurately. If the partial score is very poor the cross-validation is stopped (pruned) and the final scores value is predicted based on best till now scores. If the partial score fits within some tolerance limit, next folds are evaluated.
The package works with Python 3. To install it clone the repository:
git clone [email protected]:PiotrekGa/pruned-cv.git
and run:
pip install -e pruned-cv
You can find example notebooks in the examples section of the repository.
https://github.com/PiotrekGa/pruned-cv/blob/master/examples/Usage_with_Optuna.ipynb
https://github.com/PiotrekGa/pruned-cv/blob/master/examples/Usage_with_Hyperopt.ipynb
You can find benchmarks in examples section.
https://github.com/PiotrekGa/pruned-cv/blob/master/examples/GridSearchCV_Benchmark.ipynb
https://github.com/PiotrekGa/pruned-cv/blob/master/examples/RandomizedSearchCV_Benchmark.ipynb