

A wrapper layer for stacking layers horizontally.
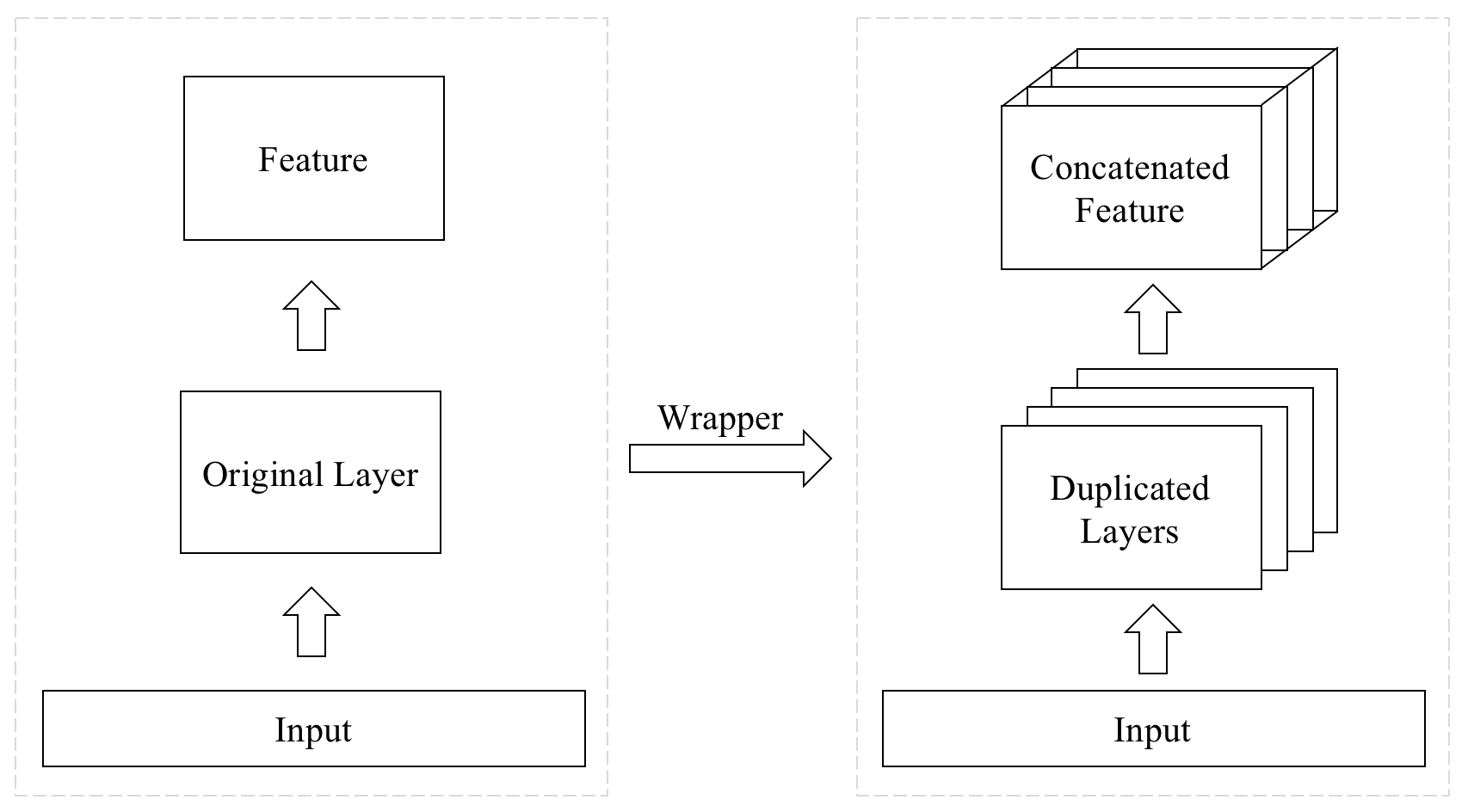
pip install keras-multi-headThe layer will be duplicated if only a single layer is provided. The layer_num argument controls how many layers will be duplicated eventually.
from tensorflow import keras
from keras_multi_head import MultiHead
model = keras.models.Sequential()
model.add(keras.layers.Embedding(input_dim=100, output_dim=20, name='Embedding'))
model.add(MultiHead(keras.layers.LSTM(units=32), layer_num=5, name='Multi-LSTMs'))
model.add(keras.layers.Flatten(name='Flatten'))
model.add(keras.layers.Dense(units=4, activation='softmax', name='Dense'))
model.build()
model.summary()The first argument could also be a list of layers with different configurations, however, they must have the same output shapes.
from tensorflow import keras
from keras_multi_head import MultiHead
model = keras.models.Sequential()
model.add(keras.layers.Embedding(input_dim=100, output_dim=20, name='Embedding'))
model.add(MultiHead([
keras.layers.Conv1D(filters=32, kernel_size=3, padding='same'),
keras.layers.Conv1D(filters=32, kernel_size=5, padding='same'),
keras.layers.Conv1D(filters=32, kernel_size=7, padding='same'),
], name='Multi-CNNs'))
model.build()
model.summary()The input data will be mapped to different values of the same shape for each layer when hidden_dim is given.
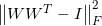
The regularization is used when you expect to extract different features from the parallel layers. You can customize the indices of weights in the layers, the intervals represent the parts of the weights and the factor of the regularization.
For example, the bidirectional LSTM layer has 6 weights by default, and the first 3s belong to the forward layer. The 2nd weight (recurrent kernel) in the forward layer controls the computation of gates for recurrent connections. The kernel for computing cell states lays in units x 2 to units x 3 of the recurrent kernel. We can used the regularization for the kernels:
from tensorflow import keras
from keras_multi_head import MultiHead
model = keras.models.Sequential()
model.add(keras.layers.Embedding(input_dim=5, output_dim=3, name='Embed'))
model.add(MultiHead(
layer=keras.layers.Bidirectional(keras.layers.LSTM(units=16), name='LSTM'),
layer_num=5,
reg_index=[1, 4],
reg_slice=(slice(None, None), slice(32, 48)),
reg_factor=0.1,
name='Multi-Head-Attention',
))
model.add(keras.layers.Flatten(name='Flatten'))
model.add(keras.layers.Dense(units=2, activation='softmax', name='Dense'))
model.build()reg_index: The indices oflayer.get_weights(), a single integer or a list of integers.reg_slice:slices or a tuple ofslices or a list of the previous choices. If multiple indices are provided inreg_indexandreg_sliceis not a list, thenreg_sliceis assumed to be equal for all the indices. The whole array will be used if you leave this argument toNone.reg_factor: The factor of the regularization, a float or a list of floats.
A more specific multi-head layer is provided (since the general one is harder to use). The layer uses scaled dot product attention layers as its sub-layers and only head_num is required:
from tensorflow import keras
from keras_multi_head import MultiHeadAttention
input_layer = keras.layers.Input(
shape=(2, 3),
name='Input',
)
att_layer = MultiHeadAttention(
head_num=3,
name='Multi-Head',
)(input_layer)
model = keras.models.Model(inputs=input_layer, outputs=att_layer)
model.compile(
optimizer='adam',
loss='mse',
metrics={},
)
model.summary()The shapes of input and output tensors would be the same if only one layer is presented as input. The input layers will be considered as query, key and value when a list is given:
from tensorflow import keras
from keras_multi_head import MultiHeadAttention
input_query = keras.layers.Input(
shape=(2, 3),
name='Input-Q',
)
input_key = keras.layers.Input(
shape=(4, 5),
name='Input-K',
)
input_value = keras.layers.Input(
shape=(4, 6),
name='Input-V',
)
att_layer = MultiHeadAttention(
head_num=3,
name='Multi-Head',
)([input_query, input_key, input_value])
model = keras.models.Model(inputs=[input_query, input_key, input_value], outputs=att_layer)
model.compile(
optimizer='adam',
loss='mse',
metrics={},
)
model.summary()