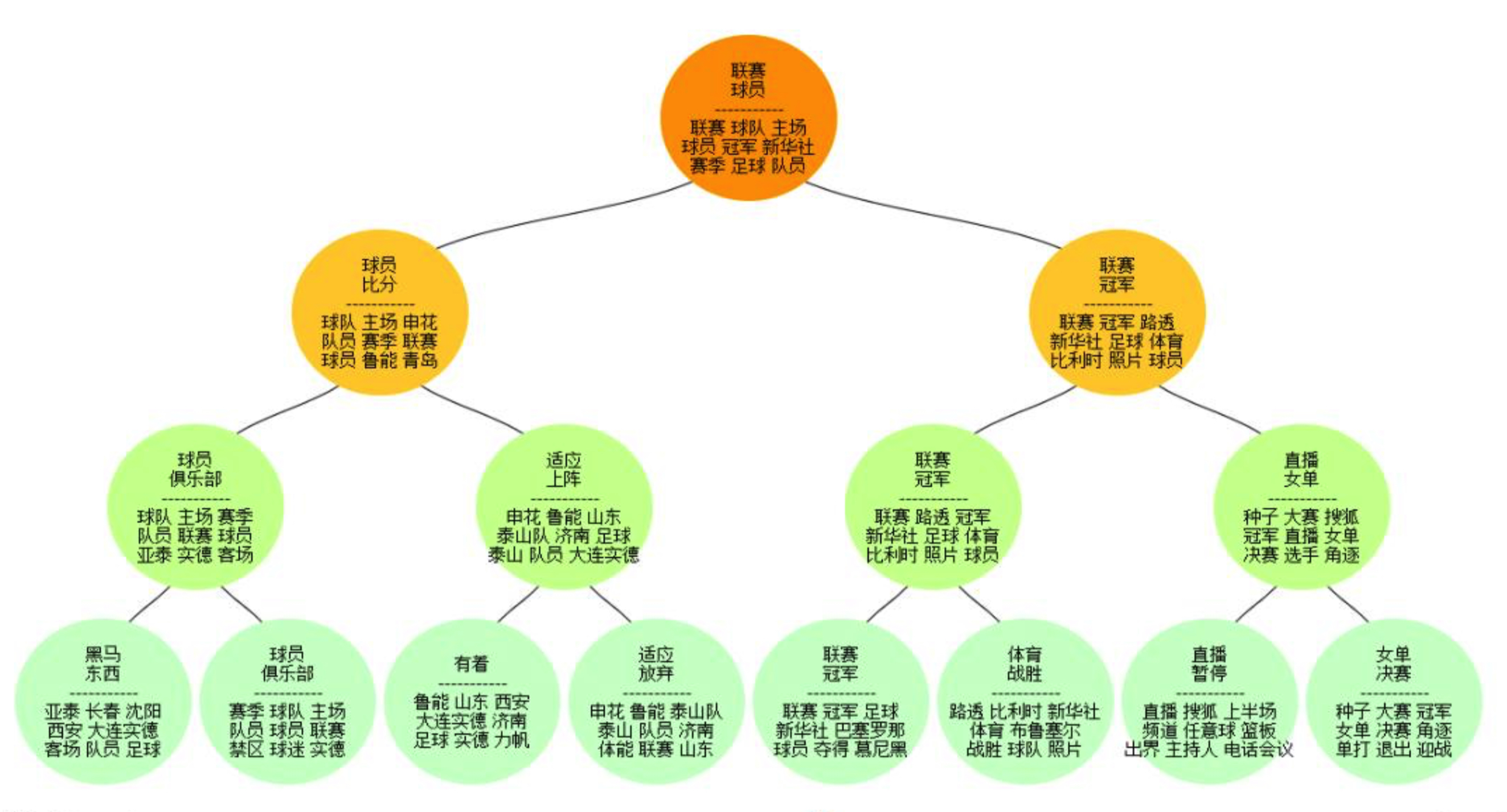
Hierarchical Topic Model Implement by NMF
tensorflow11.0及以上
30W文档 X 10W 词大概消耗 6GB左右内存,理论上1000W万文档*10W的词大概会在200G内存左右
由于TF对稀疏矩阵的乘法有最大非零元素个数的限制,如果运行时出现类似警告,可以修改model.py@D_mul_U 将参数 num_parts 修改为更大的数字,比如从10修改为100
风险说明:修改num_part会使速度变慢一丢丢
基于非负矩阵分解,NMF实现的层次主题模型
公式符号跟原论文可能存在不一致
python main.py \
--data_file=$input_file \
--save_dir=$output_dir \
--num_layers=3 \
--num_split=2 \
--init_k=100 \
--epoch=100 \
--min_hold=5 \
--in_epoch=50 \
--lr=0.001 \
--a=0.9 \
--a0=1. \
--a1=1. \
--b=0.0001> ${OUT_DIR}/log.txt输出文件说明:
docids.txt doc_id,脚本会SHUFFLE数据,文件里记录了原始ID位置
wordmap.txt 词典,词ID即行号,从0开始
python main_rerun.py \
--data_file=$input_file \
--break_point_dir=$break_dir \
--save_dir=$output_dir \
--num_layers=3 \
--start_layer=1 \
--num_split=2 \
--init_k=100 \
--epoch=100 \
--min_hold=10 \
--in_epoch=50 \
--lr=0.002 \
--a=0.9 \
--a0=1. \
--a1=1. > ${OUT_DIR}/log.re.txt相对直接运行多了两个参数,分别是原模型目录--break_point_dir和开始层次--start_layer
当数据量非常大时容易发生梯度爆炸或某层模型不收敛的情况,这时候可以从某个固定的层重跑,可以尝试重跑多次,直到模型收敛
python topic.py --dict_file=wordmap.txt --layer=0 --u_file=U-0.txt > T-0.txt
输入格式与http://jgibblda.sourceforge.net/一致
#docNUM
Word1 Word2 ...