The latest version of this project has used the following common tricks:
- The Actor and Critic share a state encoder layer
- Collect multiple steps (here, 5 steps TD(5)) before using bootstrap
-
Network Architecture
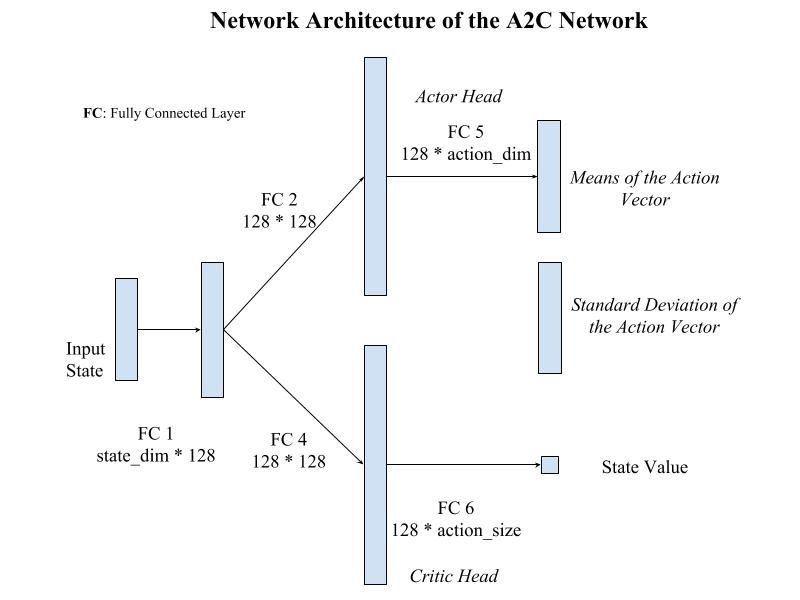
The input state vector is encoded by 1 fully connected layers befere branching into the Actor and the Critic heads, i.e. the actor and the critic share the input encoder.
The Actor head outputs the mean vector for the action vector variable to be sampled, while the Critic head outputs the state value vector. There is also a vector parameter learning the standard deviations for the action vector distribution, the standard deviation and mean vector would be used to parameterize a multi-variable normal distribution which is used to sample actions given the current state.
-
Hyper-parameters
- rollout_length = 5
- learning rate =1e-4
- learning rate decay rate = 0 .95
- gamma = 0.95
- value loss weight = 1.0
- gradient clip threshold = 5
-
Training Strategy
- Adam is used as the optimizer
- An
early-stopscheme is applied to stop training if the 100-episode-average score continues decreasing over10consecutive episodes. - Each time the model gets worse regarding avg scores, the model recovers from the last best model and the learning rate of Adam is decreased:
new learning rate = old learning rate * learning rate decay rate - Gradients are clampped into
(-5, +5)range to prevent exploding
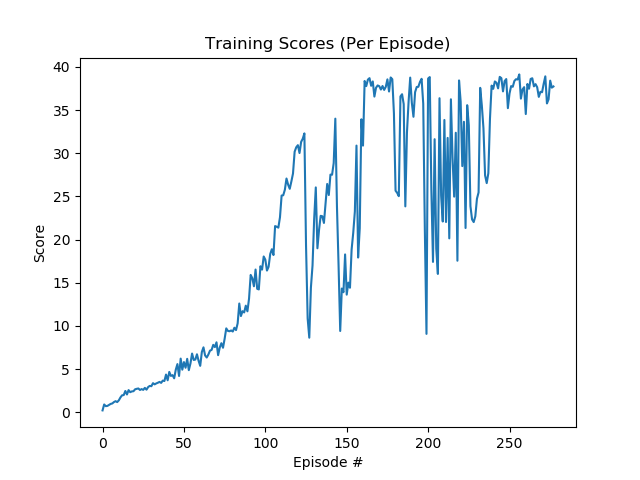
During training, the performance stabilized from around the 240th episode after a series of fluctuation. Before that, the first time the performance surpassed 30 occurred at around episode 120. The episodic and average (over 100 latest episodes) scores are plotted as following:
- Total rewards per-episode during training
- Average total rewards over latest 100 episodes during training
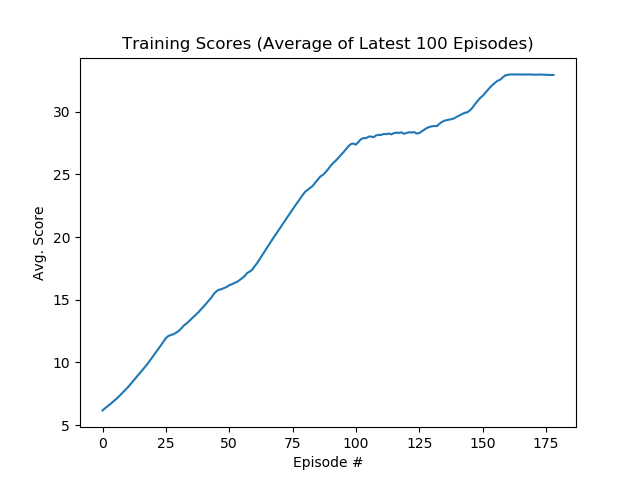
As can be seen from the plot, the average score gradually reached and passed 30 during training, before the early-stopping scheme terminates the training process.
The scores of 100 testing episodes are visualized as follows:
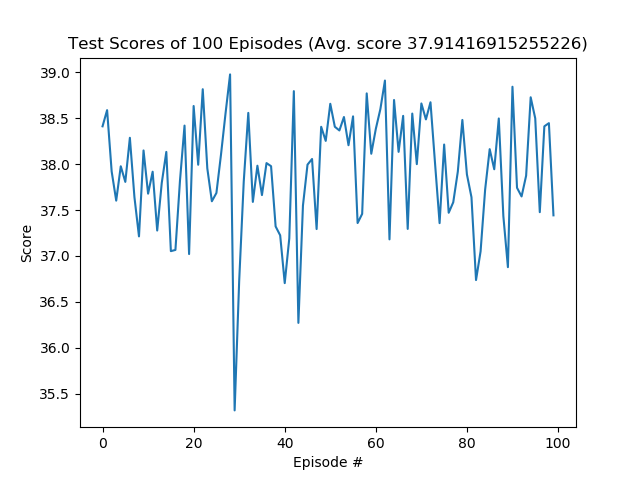
The model obtained an average score of 37.91 during testing, which is over 30.
The trained model has successfully solved the continuous task. The performance:
- an average score of
37.91over100episodes - the best model was trained using around
250episodes
has fulfilled the passing threshold of solving the problem: obtain an average score of higher than 30.00 over 100 consecutive episodes.
- Try using methods like GAE or PPO in the calculation of policy loss, to fasten or stabilize the training process.
- See if separately train the critic network using methods that improve DQ network help with the A2C framework.