Natural language processing may involve language detection, parsing, part-of-speech tagging and other activities. We'll look at just a few of those and focus on using pre-trained models. Groovy code examples can be found in the src/main/groovy directory and make use of the Apache OpenNLP and other libraries.
You have several options for running the programs (see more details from the main README):
-
If you have opened the repo in IntelliJ (or your favourite IDE) you should be able to execute the examples directly in the IDE.
-
You can run the main examples online using a Jupyter/Beakerx notebook:
-
From the command line, invoke a script with gradlew using the appropriate run<ScriptName> task.
(Hint:gradlew :LanguageProcessing:tasks --group="Application"will show you available task names.) -
If the example has @Grab statements commented out at the top, you can cut and paste the examples into the groovyConsole and uncomment the grab statements. Make sure to cut and paste any helper classes too if appropriate.
- Examples with the suffix "_JDK11" should work on JDK11 and above (tested with JDK11 and JDK17).
- Apache OpenNLP examples use 1.9.4 on JDK8 and 2.0.0 on JDK11+. Where newer code is used for 2.0.0 both "_JDK8only" and "_JDK11" variants are provided.
- Other examples should run on JDK8 and above (tested with JDK8, JDK11 and JDK17).
This example makes use of a pre-trained language model to detect the language used for a fragment of text. It uses the Apache OpenNLP library.
import opennlp.tools.langdetect.*
def base = 'http://apache.forsale.plus/opennlp/models'
def url = "$base/langdetect/1.8.3/langdetect-183.bin"
def model = new LanguageDetectorModel(new URL(url))
def detector = new LanguageDetectorME(model)
def languages = [
'spa': 'Bienvenido a Madrid',
'fra': 'Bienvenue à Paris',
'dan': 'Velkommen til København',
'bul': 'Добре дошли в София'
]
languages.each { k, v ->
assert detector.predictLanguage(v).lang == k
}OpenNLP also supports sentence detection. We load the trained sentence detection model for English and use that to process some text. Even though the text has 28 full stops, only 4 of them are associated with the end of a sentence.
import opennlp.tools.sentdetect.*
def text = '''
The most referenced scientific paper of all time is "Protein measurement with the
Folin phenol reagent" by Lowry, O. H., Rosebrough, N. J., Farr, A. L. & Randall,
R. J. and was published in the J. BioChem. in 1951. It describes a method for
measuring the amount of protein (even as small as 0.2 γ, were γ is the specific
weight) in solutions and has been cited over 300,000 times and can be found here:
https://www.jbc.org/content/193/1/265.full.pdf. Dr. Lowry completed
two doctoral degrees under an M.D.-Ph.D. program from the University of Chicago
before moving to Harvard under A. Baird Hastings. He was also the H.O.D of
Pharmacology at Washington University in St. Louis for 29 years.
'''
def url = 'http://opennlp.sourceforge.net/models-1.5/en-sent.bin'
def model = new SentenceModel(new URL(url))
def detector = new SentenceDetectorME(model)
def sentences = detector.sentDetect(text)
assert text.count('.') == 28
assert sentences.size() == 4
println sentences.join('\n\n')Running the script yields the following output:
The most referenced scientific paper of all time is "Protein measurement with the
Folin phenol reagent" by Lowry, O. H., Rosebrough, N. J., Farr, A. L. & Randall,
R. J. and was published in the J. BioChem. in 1951.
It describes a method for
measuring the amount of protein (even as small as 0.2 γ, were γ is the specific
weight) in solutions and has been cited over 300,000 times and can be found here:
https://www.jbc.org/content/193/1/265.full.pdf.
Dr. Lowry completed
two doctoral degrees under an M.D.-Ph.D. program from the University of Chicago
before moving to Harvard under A. Baird Hastings.
He was also the H.O.D of
Pharmacology at Washington University in St. Louis for 29 years.Sometimes when analysing text we want to search for meaningful entities
such as the dates, locations, names of people, etc.
The following example uses OpenNLP. It has numerous named entity models
which select such aspects individually. We'll use 5 English-language models:
person, money, date, time, and location,
but there are other models and models for some other languages.
import opennlp.tools.namefind.*
import opennlp.tools.tokenize.SimpleTokenizer
import opennlp.tools.util.Span
String[] sentences = [
"A commit by Daniel Sun on December 6, 2020 improved Groovy 4's language integrated query.",
"A commit by Daniel on Sun., December 6, 2020 improved Groovy 4's language integrated query.",
'The Groovy in Action book by Dierk Koenig et. al. is a bargain at $50, or indeed any price.',
'The conference wrapped up yesterday at 5:30 p.m. in Copenhagen, Denmark.',
'I saw Ms. May Smith waving to June Jones.',
'The parcel was passed from May to June.'
]
// use a helper to cache models
def helper = new ResourceHelper('http://opennlp.sourceforge.net/models-1.5')
def modelNames = ['person', 'money', 'date', 'time', 'location']
def finders = modelNames.collect{ new NameFinderME(new TokenNameFinderModel(helper.load("en-ner-$it"))) }
def tokenizer = SimpleTokenizer.INSTANCE
sentences.each { sentence ->
String[] tokens = tokenizer.tokenize(sentence)
Span[] tokenSpans = tokenizer.tokenizePos(sentence)
def entityText = [:]
def entityPos = [:]
finders.indices.each {fi ->
// could be made smarter by looking at probabilities and overlapping spans
Span[] spans = finders[fi].find(tokens)
spans.each{span ->
def se = span.start..<span.end
def pos = (tokenSpans[se.from].start)..<(tokenSpans[se.to].end)
entityPos[span.start] = pos
entityText[span.start] = "$span.type(${sentence[pos]})"
}
}
entityPos.keySet().toList().reverseEach {
def pos = entityPos[it]
def (from, to) = [pos.from, pos.to + 1]
sentence = sentence[0..<from] + entityText[it] + sentence[to..-1]
}
println sentence
}Gives the following result:
A commit by person(Daniel Sun) on date(December 6, 2020) improved Groovy 4's language integrated query.
A commit by person(Daniel) on Sun., date(December 6, 2020) improved Groovy 4's language integrated query.
The Groovy in Action book by person(Dierk Koenig) et. al. is a bargain at money($50), or indeed any price.
The conference wrapped up date(yesterday) at time(5:30 p.m.) in location(Copenhagen), location(Denmark).
I saw Ms. person(May Smith) waving to person(June Jones).
The parcel was passed from date(May to June).The result isn't perfect.
Arguably "Sun." should be detected as part of the subsequent date entity in the second sentence,
and "Ms." as part of the person entity in the 5th sentence.
Also, the location entities in sentence 4 could potentially be merged.
We can either do fancier programming or train better models to help for such cases.
Parts of speech (POS) detection tags words as nouns, verbs and other parts-of-speed. Some of the common tags are:
| Tag | Meaning |
|---|---|
| CC | coordinating conjunction |
| CD | cardinal number |
| DT | determiner |
| IN | preposition or subordinating conjunction |
| JJ | adjective |
| JJR | adjective, comparative |
| NN | noun, singular or mass |
| NNS | noun, plural |
| NNP | proper noun, singular |
| POS | possessive ending |
| PRP | personal pronoun |
| PRP$ | possessive pronoun |
| RB | adverb |
| TO | the word "to" |
| VB | verb, base form |
| VBD | verb, past tense |
| VBZ | verb, third person singular present |
Here, we use OpenNLP's POS detection capabilities to detect the parts of speech for a number of sentences.
def helper = new ResourceHelper('http://opennlp.sourceforge.net/models-1.5')
def sentences = [
'Paul has two sisters, Maree and Christine.',
'His bark was much worse than his bite',
'Turn on the lights to the main bedroom',
"Light 'em all up",
'Make it dark downstairs'
]
def tokenizer = SimpleTokenizer.INSTANCE
sentences.each {
String[] tokens = tokenizer.tokenize(it)
def model = new POSModel(helper.load('en-pos-maxent'))
def posTagger = new POSTaggerME(model)
String[] tags = posTagger.tag(tokens)
println tokens.indices.collect{tags[it] == tokens[it] ? tags[it] : "${tags[it]}(${tokens[it]})" }.join(' ')
}When run, the output will be:
NNP(Paul) VBZ(has) CD(two) NNS(sisters) , NNP(Maree) CC(and) NNP(Christine) .
PRP$(His) NN(bark) VBD(was) RB(much) JJR(worse) IN(than) PRP$(his) NN(bite)
VB(Turn) IN(on) DT(the) NNS(lights) TO(to) DT(the) NN(main) NN(bedroom)
NN(Light) POS(') NN(em) DT(all) IN(up)
VB(Make) PRP(it) JJ(dark) NN(downstairs)
Information extraction systems aim to extract arbitrary relations and their arguments from unstructured text without supervision. Given a sentence, they extract information in the form of a triple, consisting of a subject, relation and object.
Here, we use MinIE's information extraction capabilities to extract information triples.
def sentence = 'The conference wrapped up yesterday at 5:30 p.m. in Copenhagen, Denmark.'
def parser = CoreNLPUtils.StanfordDepNNParser()
def minie = new MinIE(sentence, parser, MinIE.Mode.SAFE)
println "\nInput sentence: $sentence"
println '============================='
println 'Extractions:'
for (ap in minie.propositions) {
println "\tTriple: $ap.tripleAsString"
def attr = ap.attribution.attributionPhrase ? ap.attribution.toStringCompact() : 'NONE'
println "\tFactuality: $ap.factualityAsString\tAttribution: $attr"
println '\t----------'
}When run, the output will be:
Input sentence: The conference wrapped up yesterday at 5:30 p.m. in Copenhagen, Denmark.
=============================
Extractions:
Triple: "conference" "wrapped up yesterday at" "5:30 p.m."
Factuality: (+,CT) Attribution: NONE
----------
Triple: "conference" "wrapped up yesterday in" "Copenhagen"
Factuality: (+,CT) Attribution: NONE
----------
Triple: "conference" "wrapped up" "yesterday"
Factuality: (+,CT) Attribution: NONE
----------
Sentiment analysis attempts to categorize samples according to some categories of interest, e.g. is a movie review (or a tweet, or some other social media comment) predominantly positive or negative.
We can train up our model as follows:
def trainingParams = new TrainingParameters()
def trainingStream = new CollectionObjectStream(trainingCollection)
def sampleStream = new DocumentSampleStream(trainingStream)
def factory = new DoccatFactory()
def model = DocumentCategorizerME.train('en', sampleStream, trainingParams, factory)We can use our model as follows:
def sentences = ['OpenNLP is fantastic!',
'Groovy is great fun!',
'Math can be hard!']
def w = sentences*.size().max()
def categorizer = new DocumentCategorizerME(model)
sentences.each {
def result = categorizer.categorize(it.split('[ !]'))
def category = categorizer.getBestCategory(result)
def prob = result[categorizer.getIndex(category)]
println "${it.padRight(w)} $category (${ sprintf '%4.2f', prob})}"
}Running this example for two variants gives:
Analyzing using Maxent
OpenNLP is fantastic! positive (0.64)}
Groovy is great fun! positive (0.74)}
Math can be hard! negative (0.61)}
Analyzing using NaiveBayes
OpenNLP is fantastic! positive (0.72)}
Groovy is great fun! positive (0.81)}
Math can be hard! negative (0.72)}
We have all seen recent advancements in systems like Apple's Siri, Google Assistant and Amazon Alexa. This is part of a bigger push towards Natural Language Interface (NLI) interaction with computers. Such systems can be quite complex, yet the expectation is that folks using simple devices will be able to access them. The ability to deliver such services depends on smart scaling approaches.
The Apache NLPCraft (incubating) project provides a scalable architecture for the supporting natural language interface approach with language models as code, flexible components and good third party integration.
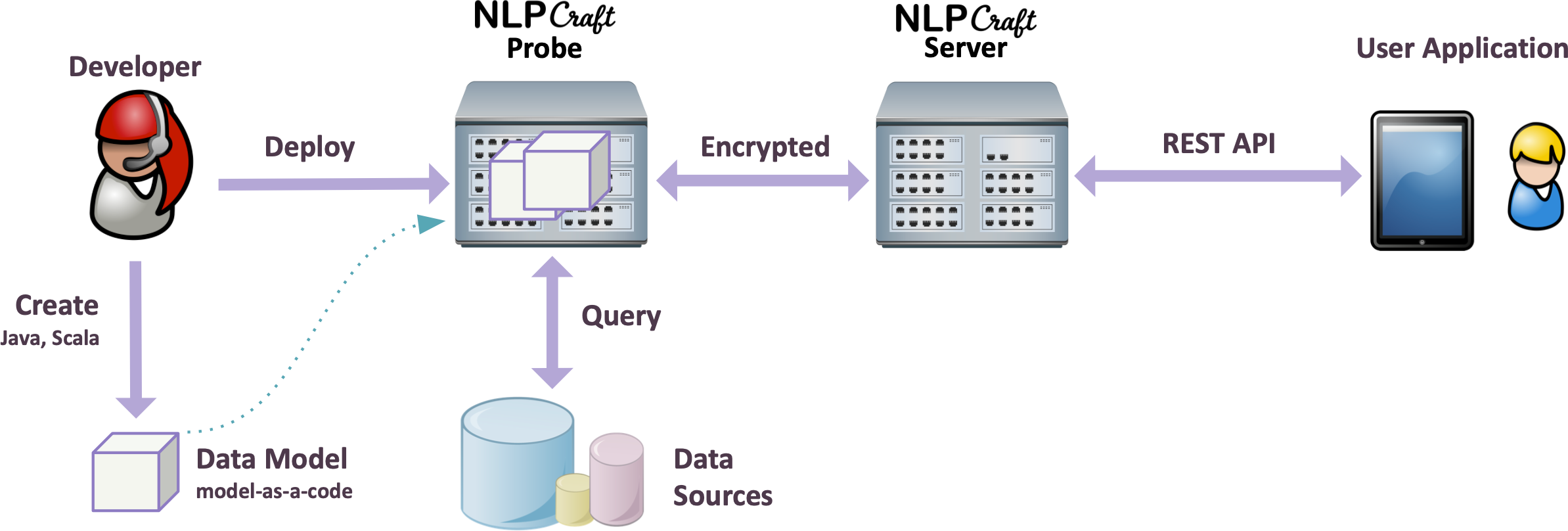
Groovy code examples can be found in the LanguageProcessingNLPCraft/src/main/groovy directory. This example is interacting with one of the built-in example language models for light switches:
start(LightSwitchModel)
def cli = new NCTestClientBuilder().newBuilder().build()
cli.open("nlpcraft.lightswitch.ex")
println cli.ask('Turn on the lights in the main bedroom')
println cli.ask("Light 'em all up")
println cli.ask('Make it dark downstairs') // expecting no match
if (cli) {
cli.close()
}
stop()Running the example gives the following output:
Lights are [on] in [main bedroom].
Lights are [on] in [entire house].
No matching intent found.We could now revise our model if we wanted the last example to also succeed.
Requirements:
- The version of NLPCraft being used requires JDK11+.