Error in user YAML: (<unknown>): found character that cannot start any token while scanning for the next token at line 4 column 1
---
title: Hadoop Rpc源码分析
date: 2019-11-05 01:38:28
tags:
- 架构
- Hadoop
- Yarn
---
Hadoop生态系统中Rpc底层基本都是走的一套实现,所以有必要对Rpc底层实现做一次系统性的梳理总结。 知乎链接
Client&Server实现入口
RpcEngine作为Rpc实现的接口,用来获取client端proxy和server端的server
- 主要的实现是WritableRpcEngine,ProtobufRpcEngine(现默认),两者的区别主要是序列化与反序列化的协议不同;内部都有继承Server构成完整Rpc Server的实现类
- IPC.Server是两种序列化协议的基类,org.apache.hadoop.ipc.Server 主要实现了Reactor的请求处理模式
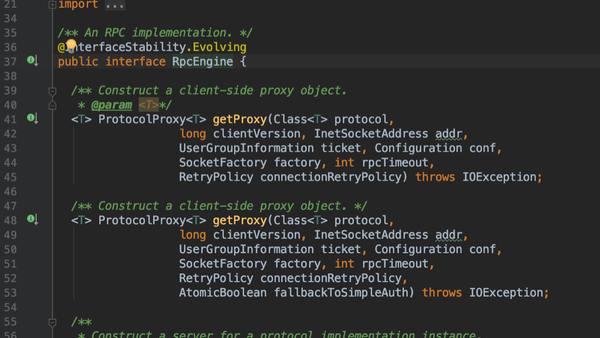
- 按照序列化协议区分两种实现:ProtobufRpcEngine, WriteableRpcEngine
- 通过接口getProxy 构造RpcClient

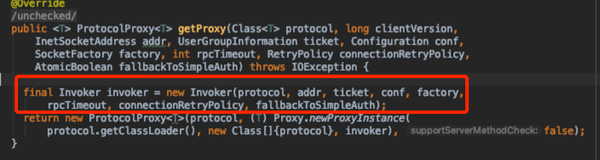
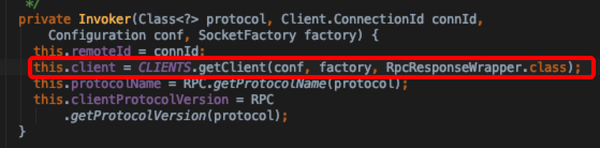
- getServer构造RpcServer
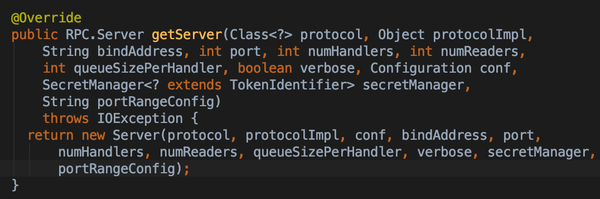
总体来说Client端实现比较简单,用hashTable的结构来维护connectionId -> connections以及callId -> calls 对应关系,使得请求响应不需要有严格的顺序性
- Ipc.Client构成
- callIdCounter:callId 发号器
- connections: HashTable结构,用来维护Id → Connection的映射
- sendParamsExecutor:请求发送线程池
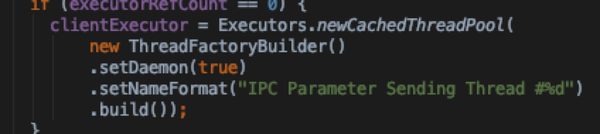
- Connection:自身是一个线程
- calls: HashTable结构,请求结束将从call从HashTable中移除
- sendRpcRequest:用户线程中通过call入口调用,用户线程阻塞
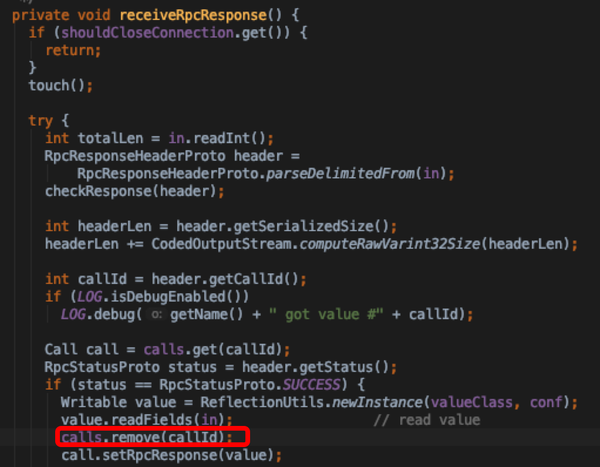
- receiveRpcResponse: run中不断轮询server看结果是否就绪
- client 处理过程

图片摘自《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理 》
- 通过反射获取到方法描述,走client Invoker调用远程实现
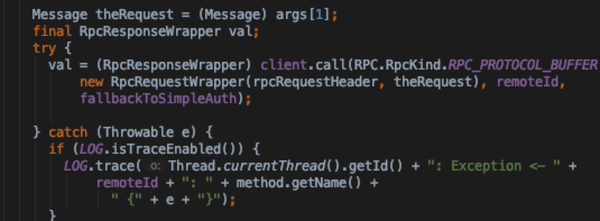
- getConnection中与远程server 建立socket 连接,并将连接加入connections集合中
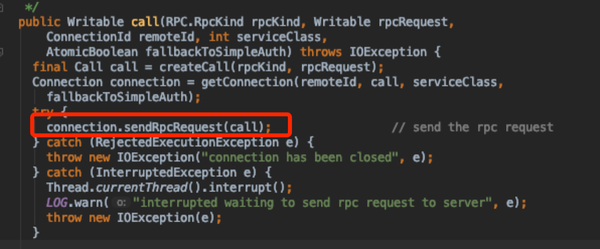
- 在用户线程中调用connection.sendRpcRequest,阻塞的获取结果
- Connection自身run方法中不停的轮询Server接收返回结果
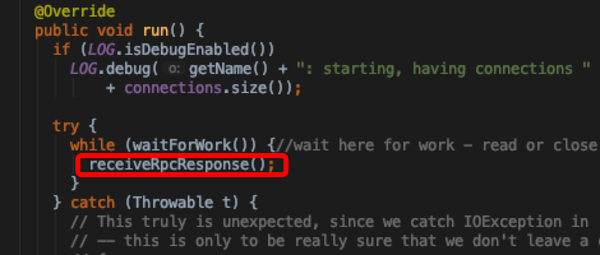
- waitForWork用来判断当前connection是否应该继续存在,返回true则继续轮询server,如果是false则关闭当前connection
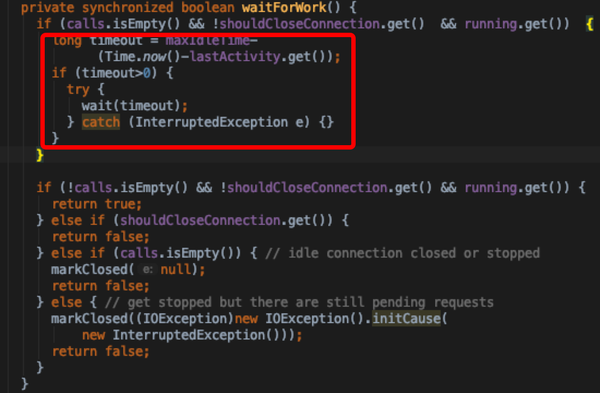
- receiveRpcResponse接收服务端返回结果,将calls移除table,可以乱序,通过ConnectionId索引,不需要同步代码块,因为只有一个receiver
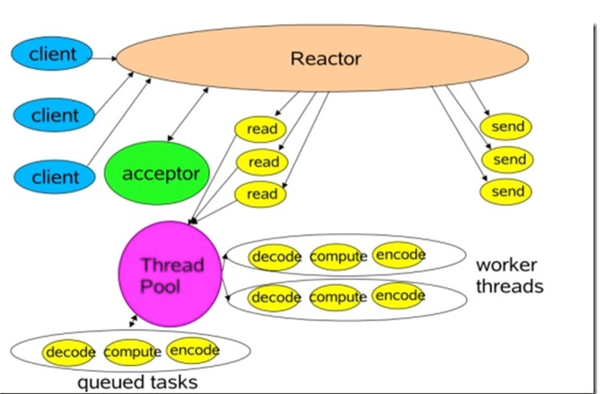
- Server端采用经典的Reactor模式,利用IO多路复用实现事件驱动
- 痛点在于多路复用之前的处理模式,socket read/write是阻塞的,一个线程只能处理一个socket;使用selector之后一个进程可以监视多个进程文件描述符
参考阅读:Reactor模式、Java NIO 底层原理 、select、poll、epoll

图片摘自《Hadoop技术内幕:深入解析MapReduce架构设计与实现原理 》
- Reactor 工作图
- Reactor:负责响应IO事件,将事件派发到工作线程
- Acceptor:用来接收Client端的请求,建立Client与handler的联系;向Reactor注册handler
- Reader/Sender:为了加快速度,同时做到请求和处理过程的隔离,reader和sender 分别是两个线程池,用来存放该过程处理完后的连接,处理完之后塞入中间队列,等待下一个过程的线程拿去处理就行
- Handler:connection对应的工作线程,会做一些decode, compute, encode工作
Hadoop RpcServer组成结构
- 序列化层:RpcRequestWrapper, RpcResponseWrapper
- 接口调用层:RpcInvoker,通过反射方式阻塞调用Server端具体的Service方法;调用前后记录一些metrics信息
- 在handler线程处理逻辑中,通过注册的rpcKind获取对应的RpcInvoker实现,通过反射来调用工作层的Service
- 请求接收/返回层Ipc.Server:基于Java NIO实现的Reactor 事件驱动模式
- Listener
- selector:监听请求 → 建立连接 → 派发到Reader线程
- Readers
- readSelector:解析&封装Call → 塞入CallQueue
- Handlers:工作线程
- 并行pull CallQueue,调用RpcInvoker处理
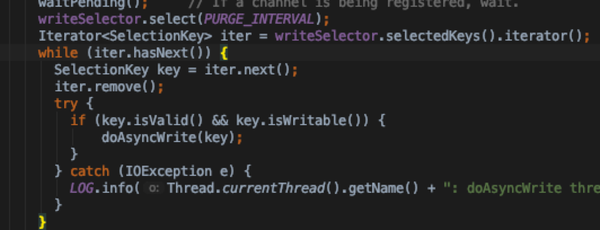
- Responder:read request和write response采用不同的selector实现读写分离
- writeSelector
- connectionManager: 定时清理idle时间过长的Connection
- CallQueue:reader handler之间的缓冲队列,生产消费者模型
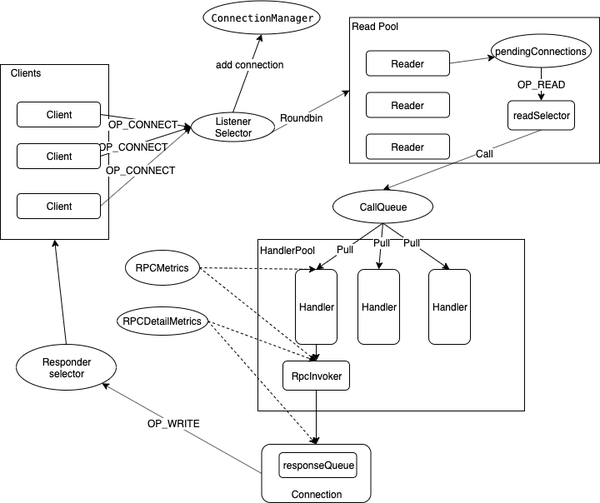
- Listener → Reader 请求建立过程:ListenerReaderConnection
- Listener线程只有一个,通过Selector方式监听客户端的Rpc请求(OP_ACCEPT事件),调用doAccept方法建立连接;此时connectionManager线程开始工作
- 建立连接后,roundbin方式获取一个reader线程,将连接塞入reader线程的pending队列和connectionManager中
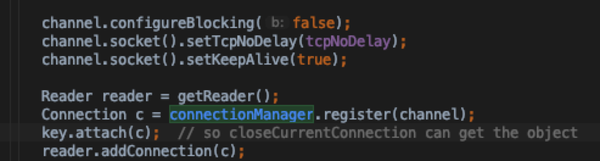

- Reader线程doRunLoop中,将pending的connections注册到readSelector中,用来监听一个connection读就绪事件
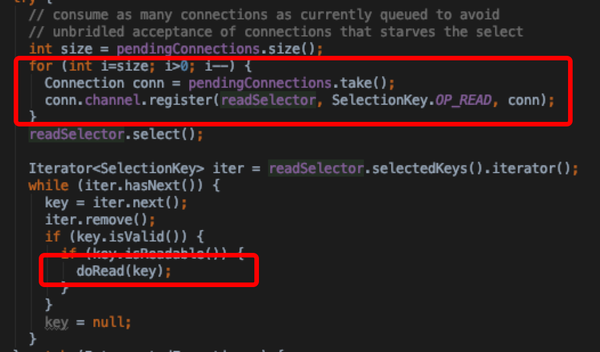
- 数据读入 → 工作线程 : ReaderConnectionCallQueue
- 而后Reader通过selector方式,只要监听的channel有读事件,则调用doRead方法;其中通过selectionKey获取关联的connection对象,调用connection的readAndProcess方法
- connection.readAndProcess: 主要是将channel里面的数据读入data byteBuffer中,数据读完之后调用processOneRpc 进一步处理
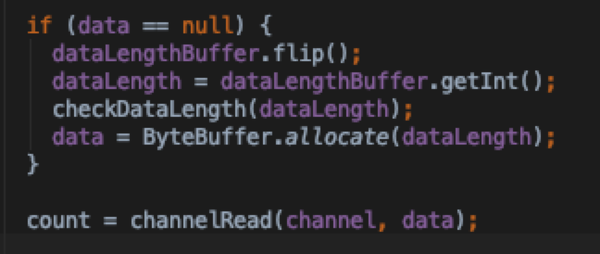
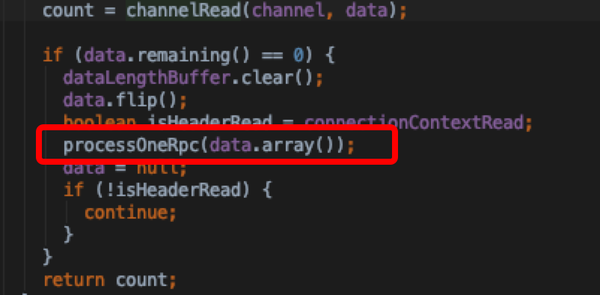
- connection. processOneRpc 对buffer decode构造成DataInputStream以及RpcHeader(请求元信息,协议类型等)通过processRpcRequest将请求塞入CallQueue中,等待handlers处理
- connection.processRpcRequest:通过header中指定的rpc engine将dataInputStream根据不同engine反序列化协议反序列化成rpcRequestWrapper;构造Call对象塞入CallQueue, 并incrRpcCount
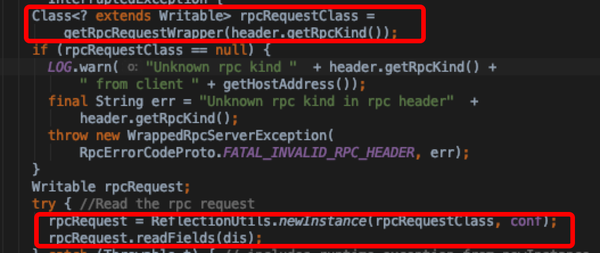

- Handler → RpcInvoker → Responder
- Handler线程在Server start的时候就已经构建启动了
- 并行pull callQueue获取队列中未处理的call,调用call方法
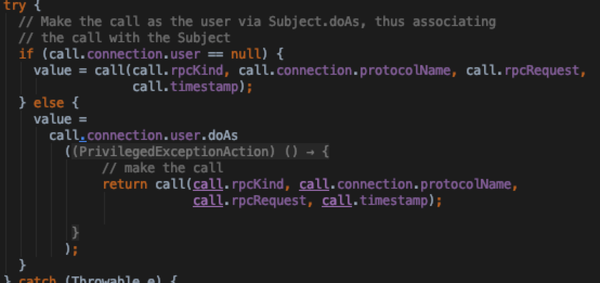
- 通过rpcKind获取对应的RpcInvoker实现;主看ProtoBufRpcInvoker.call

- 通过反射获取server端对应的接口实现,阻塞调用,在调用前后记录一些metrics信息;最后将结果包装成RpcResponseWrapper
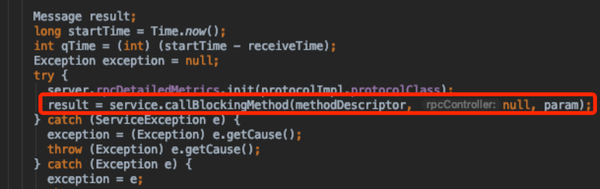
- 当结果处理完成之后,通过setupResponse将结果序列化成byte buffer根据不同engine实现的wrapper 序列化方式有所不同
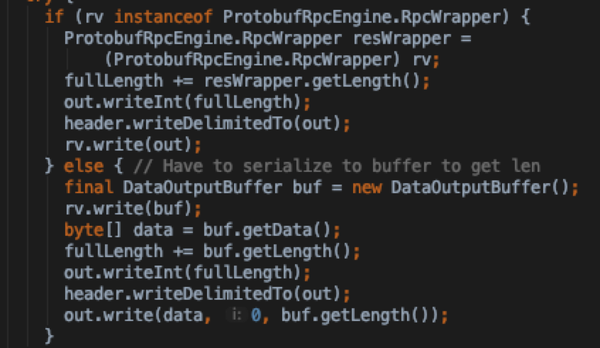

- 调用Responder.doRespond将请求结果返回客户端
- 请求返回处理过程: 通过Responder线程+ writeSelector
- Responder.doRespond
- 在handler中尽可能的将response一次性写入channel buffer,如果没有剩余则不用注册Responder的Responder.doRespond
- 如果一次性写不完且是在handler线程中,则唤醒writeSelector,将当前channel 注册 SelectionKey.OP_WRITE 异步去处理
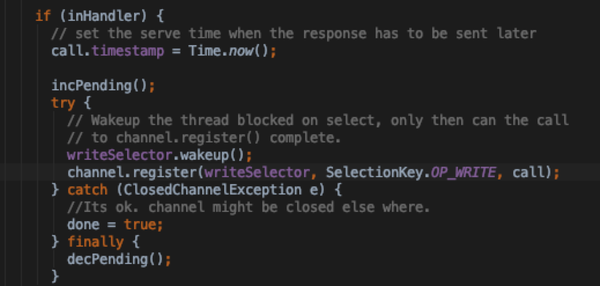
- Responder 线程自身的doRunLoop里面也是通过writeSelector监听OP_WRITE事件处理
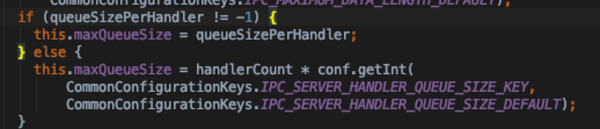
- CallQueueManager 相关
- 默认实现是LinkedBlockingQueue
- 大小通过queueSizePerHandler或ipc.server.handler.queue.size * handler_count 决定
- ConnectionManager相关:用来定时清理idle时间过长的connection
- idleScanThreshold: 每次轮询扫描的connections 阈值default 4000
- idleScanInterval: 定时检测线程轮询间隔 default 10000
- maxIdleTime: 一个connection最长idle时间,default 2* 10000
- maxIdleToClose : 一次轮询最多关闭的连接数 default 10
- 一个connection是不是可以被清理由以下条件决定
- connection.isIdle(): rpcCount为0, 也就是Call没有塞入callQueue;在connection.processRpcRequest末尾,如果成功塞入callQueue中的话会incrRpcCount
- lastContact < minLastContact:
- minLastContact: Time.now() - maxIdleTime
- startIdleScan:开启清理线程,随Listener线程启动