Spark operator + jupyter notebook? #1652
Comments
|
@tamis-laan you can do it with the https://github.com/jupyter-server/enterprise_gateway backend for Jupyter. Here is my enterprise-gateway istio issue for reference: jupyter-server/enterprise_gateway#1168 |
I discovered Spark also allows for executing jobs directly on kubernetes: When you use So I'm not sure how the |
|
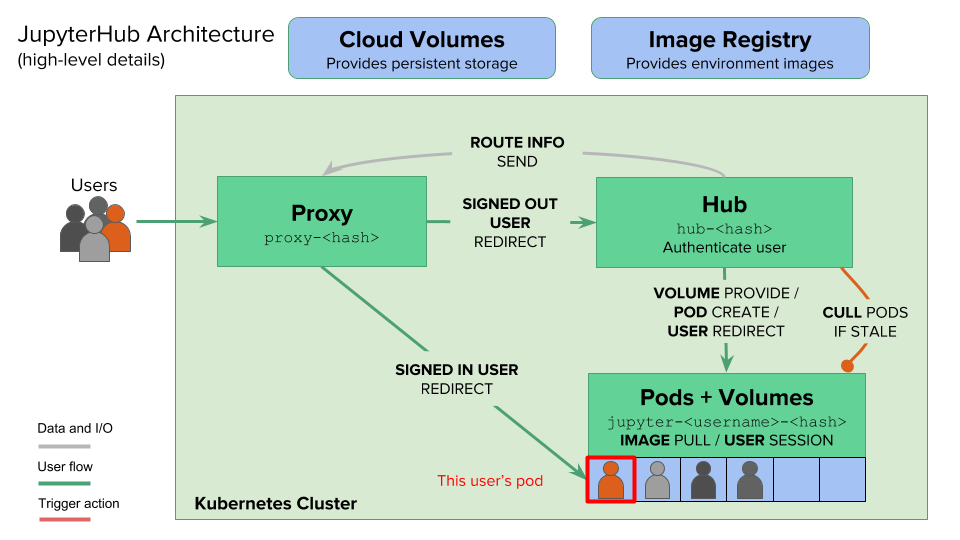
Jupyterhub extends Jupyter notebooks (see https://zero-to-jupyterhub.readthedocs.io/en/stable/_images/architecture.png). Thus, Jupyterhub starts a Jupyterlab or plain Jupyter Notebook for your user within a pod and does some management around that.
Yes. The upstream Apache Spark can spawn a driver which in turn spawns N many executors. The executors run your code. However, they do not have an interactive mode. Jupyter Notebooks are interactive in that they spawn a runtime and do not run a script.
See my argument regarding interactivity. AFAIU it won't work. However, if running individual Spark Jobs from your Jupyter Notebook (instead of your Jupyter Notebook kernel in Spark), check out: |
{kind=link}
|
@tahesse Thanks for providing a starting point! I'm curious as to how the enterprise gateway kernel would work with the operator though? I understand that enterprise gateway would allow us to run the Jupyter kernel in a k8s cluster, but I'm curious as to how this would enable us to submit jobs using the operator? Would the kernel generate job manifests? |
|
Following -- looking forward to this. |
@Shrinjay WDYM with job manifests? AFAIU enterprise-gateway is an operator itself. Your JupyterHub or JupyterLab (frontend-wise) communicates with enterprise-gateway if configured properly. Note that they do not spawn a service with the jupyter kernel pod (I thus didn't manage to make it work with istio for that very reason... but I'm out of ideas right now). I hope my explanation clears up some of the confusions. |
|
Perhaps what you need is PySpark SparkSession via client connect to a Spark Connect Server in Spark 3.4.0 sc mode: https://spark.apache.org/docs/latest/spark-connect-overview.html I've developed a module for deploying the latest 3.4.0 server-client mode on k8s and support config PySpark Session for direct connections. How about check this out? Alternatively, PySpark Session can be deployed in client mode on k8s, also avaliable in https://github.com/Wh1isper/sparglim#pyspark-app |
|
I got this working quit simple. Following this explainer about running Spark in client mode: https://medium.com/@sephinreji98/understanding-spark-cluster-modes-client-vs-cluster-vs-local-d3c41ea96073 deploy Jupyter Spark manifest Include an headless service to run in apiVersion: apps/v1
kind: Deployment
metadata:
name: jupyter
labels:
app: jupyter
spec:
replicas: 1
selector:
matchLabels:
app: jupyter
template:
metadata:
labels:
app: jupyter
spec:
containers:
- name: jupyter
image: jupyter/pyspark-notebook:spark-3.5.0
resources:
requests:
memory: 4096Mi
limits:
memory: 4096Mi
env:
- name: JUPYTER_PORT
value: "8888"
ports:
- containerPort: 8888
serviceAccount: spark
serviceAccountName: spark
---
kind: Service
apiVersion: v1
metadata:
name: jupyter
spec:
type: ClusterIP
selector:
app: jupyter
ports:
- protocol: TCP
port: 8888
targetPort: 8888
---
kind: Service
apiVersion: v1
metadata:
name: jupyter-headless
spec:
clusterIP: None
selector:
app: jupyterYou can port-forward the jupyter service on port Connecting to Spark Operator I got all configs from the documentation: import os
from pyspark.sql import SparkSession
spark = (
SparkSession.builder.appName("JupyterApp")
.master("k8s://https://kubernetes.default.svc.cluster.local:443")
.config("spark.submit.deployMode", "client")
.config("spark.executor.instances", "1")
.config("spark.executor.memory", "1G")
.config("spark.driver.memory", "1G")
.config("spark.executor.cores", "1")
.config("spark.kubernetes.namespace", "default")
.config(
"spark.kubernetes.container.image", "ghcr.io/apache/spark-docker/spark:3.5.0"
)
.config("spark.kubernetes.authenticate.driver.serviceAccountName", "spark")
.config("spark.kubernetes.driver.pod.name", os.environ["HOSTNAME"])
.config("spark.driver.bindAddress", "0.0.0.0")
.config("spark.driver.host", "jupyter-headless.default.svc.cluster.local")
.getOrCreate()
)This will create the executor pod with jupyter as the client: ❯ kubectl get po -n default
NAME READY STATUS RESTARTS AGE
jupyter-7495cfdddc-864rd 1/1 Running 0 2m7s
jupyterapp-d3c7258ec363aa87-exec-1 1/1 Running 0 88sIf you have any issue, questions and/or improvements. Let me know! |
|
@JWDobken It works, but doesn't communicate with the operator pod, is that right? I don't even need it running it seems. |
If I understand correctly, it's using I've been using this feature since spark 3.1.2, and if you need to build services via spark, this is lower latency than submitting tasks, but more costly to maintain (you may need to design the task's message queue). I built a simple GRPC data sampling service: https://github.com/Wh1isper/pyspark-sampling/ and provide an SDK for using spark in client mode or deploy connect service in k8s: https://github.com/Wh1isper/sparglim If you want to use a k8s cluster deployed spark remotely in jupyter (via client-server mode), I highly recommend you try https://github.com/Wh1isper/sparglim, given that I haven't seen any official documentation at this point (if there is, with thanks to anyone who can tell me!). |
|
How to delete pod once it is in an Error state? @JWDobken |
|
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions. |
|
This issue has been automatically closed because it has not had recent activity. Please comment "/reopen" to reopen it. |
We are running the spark k8s operator in order to process data using the yaml spec in production. This works great but we also want to do exploratory data analyses using Jupyter notebooks. Is this possible using the spark k8s operator?
The text was updated successfully, but these errors were encountered: