Massive performance problem with dependencies. #2596
Comments
|
I've hit the same issue in the past using Knockout, but it is generally known to be slow in loops. The way you explain it doesn't make 100% clear that the latency is due to Knockout and Knockout only: it could be that you have inadvertently created a structure with observables that results in overhead. So I only have a few tips that could help:
|
I would even venture to say that it is likely not due to knockout itself. I haven't studied the OP's code but it seems to modify internal knockout implementation data, and not only is that very likely not necessary to do but if you do, you are pretty much on your own. |
|
Hey, thanks for replying and taking an interest. And I begin apologizing that I am sounding combative. I did not come here with a lazy question, so I am getting a little nervous about lazy answers. Take it in collegial spirit for the purpose of fixing this problem.
it actually makes it abundantly clear. Look at the numbers! 1.4 MILLION evaluations, 700 thousand calls to the read function. And don't just throw FUD on it with "venturing to say". Every bit of this code is justified and necessary. I tried as hard as I could to make it as simple as possible. You may try to beat me at this game. In fact, we could simplify it by taking out the formula editing piece, any formula, and just make a table filling it with the functions. I will do that, to remove the distraction.
It is very likely very necessary. Every single piece of it I did reluctantly and rather would have not done. It is a bug IMO to dispose a computable only because it has no dependency subscription. Should never have been done. What if the computable generates a random number? Once I updated the formula I need to set dirty and ask to notifySubscribers because there is no other way to force the system to call the read function. This is so infuriating about the whole thing: the few times you want it to evaluate it refuses stubbornly, but then it runs 700 thousand re-evaluations over the same 100 observables due to one change!! As you can see, the isDirty and notifySubscribers is done only in the write function and I have shown you proof that the write function is being called only once. So it sets one cell dirty and calls notifySubscribers on one cell only. But in my next simplified test, I will do that from the outside, just in case if there is a state which is cleared only after the write function returns and that causes all of that. In fact, that's what I will try first.
Not crazy at all. Look, think, don't just feel and opine. There is nothing wrong with creating an observable on a naked value when it is not yet observable. Most of the time, only the view knows what it needs to have observable from the model. But I will remove this red herring in my simplified test.
You think I didn't try that first? Again, sorry for sounding combative. |
|
So, here is my radically simplified version of it. It's still with the spreadsheet formula write function. Then you can execute the following "script" on the console, one by one: The problem is still obvious, and if you do this with the A1 value (change from 0 to 1) you will completely blow this thing. Now I will go ahead and remove the spreadsheet features and use functions directly. Jut to make it as simple as possible. |
|
I will concede though that my spreadsheet requires the _state.isDirty = true and notifySubscribers call. Now I get rid of the table rendering, I have a suspicion that this is adding a lot of observables behind the scenes. Let's just do the sheet in javascript only. Code not changed, just rip out the table. This does not help. I also tried with the minified version, running into major problems with my attempt to mark _state.isDirty= true. But I hacked my way through to this and nothing else significantly changed. So it's not about using the debug version vs. minified. |
|
I no longer use Knockout so I have no interest in further analyzing this.
But this is not true. There's way too much going on in the code that may have an impact on perf (eg that very expensive regex) As I mentioned previously, Knockout is known to be slow in big loops, hence knockout-fast-foreach. |
|
Now I made another test, avoiding the computed observable altogether with it's need to use a fakeDependency to avoid being disposed and all that. In this example, which has the spreadsheet UI functionality again, here I am trying to just make every cell an observable which returns the formula evaluation function. Then when the function changes, re-evaluation happens. I have moved the formula editing business out of the scope of knockout in order to remove unnecessary observables. Now it is only the observable cell value functions. No more computed, no more writable. And it is worse. Even filling the cells in now gets slow, hence I reduce the 20 x 20 to 10 x 10. |
What do you use now?
That regex is executed only once before setting the new function. I proved to you that the write function doesn't get called much, only once when changing the one formula in J10 to trigger the cascade of insanity.
what would be? in spreadsheets you have exactly that issue: observables that check for values changing.
10 or 20 rows and columns are not big, the fast-foreach is about economy of DOM node turnover
But we have only 10 and 20 here. The issue is not DOM, the issue is observables and dependency tracking. I even proved that to you by removing any DOM data binding and just have an array of observables. How does Google sheets do it? There is clearly something wrong with the observables and dependencies. And I doubt TKO has resolved that either. PS: and you mention pureComputed, that too has no bearing on the issue here. What pure computed does is:
that isn't an issue because I do not change my dependencies once the formulas are populated. My test case is entirely about a complete exponentially exploding madness of updates. What my case shows is that the observables with dependencies have no benefit over just evaluating all cells or perhaps even a negative benefit. In my update the single leaf of the dependency tree of a 10 x 10 matrix, with 100 observable, I get hundreds of thousands of evaluation calls. If I just evaluated every cell, I would only run 100 evaluations. And if I have no idea where the dependency tree has their leaves so I could start there, I should evaluate at most 100 x 100 = 10,000, not 700,000 times. The point of maintaining dependencies should be to optimize the evaluation along the tree. Topological sort, isn't it? And then evaluate from the bottom (leaves that have no dependency subscriptions) up (roots that have no dependent observers). |
See my first comment, HTML canvas.
React, MithrilJS, VueJS, plain JS, but I would definitely encounter the same perf issues you do if I disregarded my own advice.
That is only one opinion. Observables, pubsub, streams, events, state snapshot diffing, all of these are patterns/tools that one could use to track dependencies. I would guess Google sheets uses state snapshot diffing (like git diffs, virtual dom diffs, Redux etc), because redrawing a canvas requires one to redraw all data at once. The only part of a spreadsheet app I would use KO for is the surrounding GUI frame (buttons, modal etc). This is my last comment on this issue. |
|
Well, whatever you want. But you are objectively 100% wrong. Simple test, just observables: results:
it is hereby proven that simply KO's dependency tracking is completely broken, as it performs in exponential time with increasing size of the dependency square. |
|
So, I just wrote my own observables testbed to drop in for knockout, and boy can I do better! Here it is: and here is the test, you can run the same test with knockout, just edit the first script src. I can run tables of 200 x 200 easily and it is at some O(n^2) probably, yes, here is the proof. The speed increase is thousand-folds in any sizeable tables.
And it has nothing whatsoever to do with DOM or any of this stuff. |

|
Looks like I'm gonna have to fix this myself. My fingers are itching to just write a complete replacement of knockout which would be radically simplified. But got other things to do, so lemme see if I can use this Friday to track down the cause for the horrible inefficiency. By mere code review I cannot locate the source of the problem yet. It looks pretty similar to my own noknockout.js dependency replacement (of course mine is way more tight and clean and readable code, haha, but has less bells and whistles, so ...) I think I'm going to just step though it on a 2 x 2 table, that already gives 7 evaluations where the correct number should be 3 evaluations. That should be easy to track. Even after correcting my comment here, I think I already have the issue determined right in the first line. I specifically want to know sheet[1][1]'s value, but knockout starts evaluating at sheet[0][1], which means knockout does too much! It has learned the dependencies and then it say "let me first evaluate the dependent's dependencies before I let the dependent take a crack at it". And it must be doing that in a wrong way, so in the end it has to re-evaluate a bunch of stuff because values have changed. I think that's just it. Trying to be too nifty is shooting itself in the foot! Note, this is just the 2 x 2 matrix, and the error seems insignificant, just one extra evaluation (if we allow for the extra run at setup before the value change experiment starts). But this tiny error here will later skyrocket exponentially.
Test code is just adding trace statements ... |

|
I made a bit of a mistake, which is where I can chase the problem further. The issue is that for the data binding, we have to push the value changes up and I had a bug in my subscribable that didn't actually direct the call-backs. So I ended up just evaluating everything correctly when I access the most dependent cell in this test. But of course it wouldn't trigger data binding to actually update any displayed number when I change the dependent (not that knockout doesn't have its own issues with computables not updating). So, to simulate that, I subscribe an observer function on the dependent. And I only accept my version if I get notified of the update on the last cell as I update cell (0, 0), and before I read that last cell. Once I have fixed my noknockout notification routing, then I can see if I end up in the same exponential problem as knockout, if so, I can learn how to fix that with my simpler code. And if I won't get the exponential behavior, I continue to know knockout can be improved somehow. UPDATE: still fixing my dependency tracker, and I see how it can get so bad. But that's the point, there is no way we have to accept exponential time. Yes, so it's obvious. We cannot do eager evaluation during notifySubscriber time and let it all cascade in a single pass. We need more passes.
Then the order does not matter. In my stress test, all values of the table change, but still each is re-evaluated only once, and since all that need reevaluation are marked dirty, we will not get into the problem that we are evaluating while not all the dependencies that are also dependents of the change, have been re-evaluated, so that we would later have to change again. |
|
And BINGO! That was exactly it. The results continue to be stunning and now I have the mark-dirty propagation just right and the evaluation without notification, and finally the update notification. Two-phase change propagation at great speed an O(n^2) instead of (slightly worse than) O(e^n). I found another tell-tale sign for the really awful performance of the knockout change propagation that it will provide incorrect updates to the original subscribers, thus cause DOM updates repeatedly, with incorrect values to boot, while the changes are still made. Given the debate I had with this guy above, who refused to actually think about the problem and just blamed on DOM updates, I now understand, perhaps, why he falsely believes it is a DOM update problem. Because he might have seen in his experience a lot of spurious DOM updates because of this change propagation problem.
with the test |

|
The standard dependency tracking in Knockout doesn't do well with a large dependency tree. That was the main motivation for adding "deferred updates". I see one of your examples that sets I took one of your examples that produces this result: 2 7 And simply turned on deferred updates. The results are here: 2 6 I then noticed that your test doesn't reset the count for each loop. Doing so shows a more accurate number of calls: 2 6 |
|
Hold you laughter @karimayachi . Thanks, @mbest , for your checking my work, and enlightening me about the deferredUpdate. But deferredUpdate really only sweeps the problem under the carpet. I challenge you to do size over 12 and see where that goes. While nominally your deferring makes the update count to what it ought to be, it still runs in exponential time behind the scenes. With my 2-pass algorithm I can run easily to over 600 (where then the numbers start hitting infinity, so the test is no longer valid at that point). Your current algorithm croaks at 15. It is because it still does all this repeated unnecessary work, more specifically, tree walk. The issue might just be unnecessary tree walk which can be cut when you walk across the same dependent for a second time. |
|
I notice your deferUpdates mode has some similarities with my solution. Notably, you notifiySubscribers with the 'dirty' event. That seems to be what I called 'mark-dirty'': and then then this markDirty: what you are missing is the dirtySet being populated by this pass -- I'll still try to do without a dirtySet -- but definitely you should not eval (delayed or otherwise) if the isDirty mark has already been set. You need to wait until all the dependents have been chased down, and only then notify the actual update. Then the order of execution of the evals doesn't matter any more. If you eval before the 'dirty' notifications have been cascaded through to all the dependents you get too many evals on changing (incorrect intermediary) results. |
|
... studying your code further to find where I can fix this. I'm reading aloud, step by step. nice separation of the two passes right here, 'dirty' vs. 'change'. If the subscribable defers updates, you need to be prepared to handle these two separately.
so, my question is, what is this._evalDelayed(false) (false I guess means is not a change yet, just the mark dirty cascade), let's see: suspense as we near the crucial point, to be sure, we are now passing this and true, informing we are in the mark-dirty phase: ahhh, the suspense is unbearable ... ah, bummer! This is where the mistake happens, I think. We were all set to cascade the markDirty events through the dependencies, instead we are telling us evaluate. I must say, it's getting really hard to follow. What is this notifyNextChange ... but let's assume shouldNotify is true, then we now call our original notifySubscribers without that limit feature. Let's review what that limit feature is: with hmm, this could still be salvaged, since in our 'dirty' cascade we should come down calling the original notifySubscribers still with the weird trick of passing ourselves as the value. so that would be this one, valueToNotify would be === this! But the sad thing is that we do not pass the 'dirty' event, and the missing event argument will soon be replaced by the defaultEvent 'change'. I think this is where it blows up or I have lost my trail. The valueToNotify was still the observable, not its value. And at this point we have forgotten all about that and just pass ourselves to the callback of our subscribers. The only reason this would not blow up is if in the 'dirty' event we never get here. In that case also, the event doesn't cascade. Wow, this is getting really hard and complicated. We know the algorithm is inefficient, regardless of the limiting on actual evaluations. One problem is that we may not have all computed observables deferred, but it may only be some. If it was all, we could make some assumptions. If it is some we have to decide every time if we follow two-pass 'dirty' - 'change' notification or single pass 'change' only. The original difference was made based on whether the observed subscribable (target) was deferring notifications. If it is deferring we added a 'dirty' callback. But now when in the end _callback is called on the dependents it happens as the (implicit) defaultEvent 'change'. In that case this function is called: let's say that we have already been visited here and we already have some _notificationIsPending, then we don't proceed, that is like me stopping the recursion of the 'mark-dirty' cascade when I am already marked dirty. Except, for some reason we would now tell ourselves that we are "stale". And I doubt that is accurate. We are not stale, we just happened to appear twice in the dependency tree, which is what happens a lot in my test, every cell is dependent through two paths to the changed cell. Remember this part above? yes, so that cascades to here: where now are falsely accused of being stale, and for that reason we are being forced to evaluate. I think the original author, @mbest could possibly see through this confusing jungle of states to find just a couple of lines of change to
|
|
It's cool that you're digging into the Knockout code. I think in trying to follow the code path, you might have confused what |
|
Thanks for coming back @mbest . I am sure you could do this in very short time, because it already seems to be almost there. I think people (example the first guy who replied here) are completely underestimating what knockout could do, and dismissing it. If only a small fix was made in the dependency chasing algorithm, you would see a whole universe of new applications. I think you might not even have needed all this complexity of deferred updates if you had looked at the problem from just an algorithmic improving perspective. Imagine people had dismissed Java or javascript because they never improved the GC algorithms (similar problem, mark & sweep). Here, to challenge you collegially (and anyone who dismissed or ridiculed it), what if time instead of reads was our outcome?
Since reads are not invoked, it proves that now the remaining awfulness of performance is entirely about tree walking problem. Cut the path when you come across the same node twice in the 'dirty' phase (assuming you actually have a proper cascading 'dirty' phase, I can still not quite tell) and you will reach 1000s-fold speed improvement. I am putting my updated code to keep it all reproducible. |
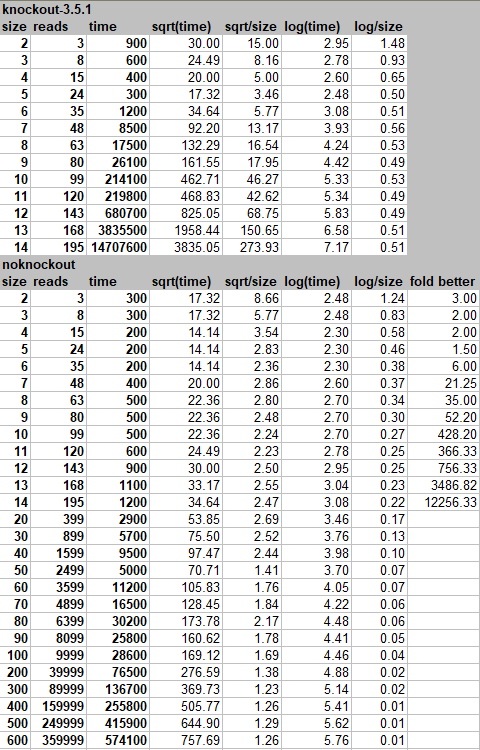
Aha, so ... wait, but that is the one I was discussing, no? Last line of _limitChange calls finish(), which is the var finish = wrapping the limit function around the functionArgument. So, OK, you are saying that this finish part is scheduled for later. Hmm, so then that means that we never cascade the 'dirty' event through the entire dependency tree! And this is the issue. Can you see it? If we were just cascading the 'dirty' event to every dependent (making sure we do not recurse when we hit one that's already marked isDirty), then we are done quickly and then all we need is to evaluate once along that chain,. Again making sure we do not evaluate twice, which isn't going to be a problem, as long as we don't again notify changes during that evaluation phase ... this is an important trickiness to distinguish an original change from a ripple change. |
|
I am trying in my noknockout code to get rid of the dirtySet collection during the mark 'dirty' phase of the update. And I am having a problem suggesting to me that the dirtySet is needed. The problem is if we just again traverse the tree during evaluation we can re-enter the same observable while it is being evaluated. And no, it's not a cyclic dependency, it's from notifying changes while fetching (and re-evaluating as needed) ones dependencies. Perhaps if I am setting a beingEvaluated flag, then when I come into it, I cannot just assume that the current value is good. Instead I have to abort the current evaluation without a value, backtrack. In my 3 x 3 field, we walk like this: (0,0) -> (0,1) -> (0,2) -> (1,2) -> (1,1)* -> (1,0) -> (2,0) -> (2,1) at this point (2,1) needs the value of (1,1), but that is currently still being evaluated. Only because of the change of its dependency, we came back to wanting its value. We need to first come back and then notify changes. It would be like a 3-phase traversal then:
It's really hard without a dirtySet. Sadly, I think there was never a need for the deferUpdate mode, and since it was put in now the real fix is much harder. |
|
It is absolutely necessary to put a 2-pass mark and update algorithm in and a dirtySet collected during mark 'dirty' pass is the easiest way to do it. Because once you start the update phase, your dependencies may actually change, and if you rely on the dependencies path to avoid the dirtySet, you're going to get into huge trouble if the dependencies change during the update. |
|
@gschadow It seems like you are onto something after all, and credit to you for investigating & proving it. However please do not assume I underestimate or dismiss Knockout, as you would have readers believe with this statement obviously referring to me :
I developed with Knockout for years, respect it, and have always tried to provide genuine, constructive feedback here and on SO. While KO's pubsub impl may be heavily improved, HTML canvas is always the answer for rendering large datasets in interactive grids. But that is beside the point of this issue now that it has a more isolated test case 😄. |
|
@webketje it's all in good spirits. The point is making stuff right. I apologized from the beginning for being a little intense, maybe because I have been around for a few more years and I see through certain patterns of explanations ... While you are here, can we lay one thing to rest, perhaps? Why would canvas be any better, where you have to draw boxes and letters all manually rather than just throwing some HTML at the rendering engine? Why would that be any better? I did some poking in the Google sheets DOM and I saw the canvas indeed. But I wonder if that isn't because of that complicated transpiler thing that they built their software with, like out of Java code or so. But as you say, correctly, that's really just a side quest. I wonder if you have worked with MobX before? I am trying to build the same test case to see if MobX has the same problem. If it doesn't, there may be more benefit of transplanting knockout's rendering framework over MobX rather than fixing knockout's observables. But if MobX had the same issue, then there would be real value to fix knockout quickly. I find it a little hard to get started with MobX, frankly. Too much indirection with typescript and magically appearing "files" after loading the .js and then some .js.map ... it's a bit over my head tight now. Thanks. |
|
Actually, I got it. MobX is about as fine as my noknockout, up unto table size 500, at 600 it croaks with a "RangeError: Maximum call stack size exceeded". So it might be just a configurable parameter. Mine does not croak at 600, it smoothly scales. The only reason I stop at 600 is that it leads to number overflow,. |
|
I don't know if MobX could be configured to increase that maximum stack size, but with my two-pass update algorithm with the dirtySet none of this will be a problem. So I really wish that @mbest , who knows the knockout code like his own back yard would help us out here with a relatively quick fix as it could be so simple. My next step to trying to do that would be to go back the source code history until before the time the deferred updates were introduced. Because they are just too wild for me to chase down. And I think it was entirely unnecessary to introduce the deferred updates, because there is no such thing as values being "unstable" if your update algorithm is correct. |
Sure, it's certainly much easier from a developer experience perspective. But the DOM is painfully slow to (re)render (not humanly noticable in 90% of apps/sites). WebGL also runs on HTML canvas because updating DOM nodes requires a lot of RAM as there's a whole virtual context attached to each node (event listeners, attributes etc) and if you're not careful with update order and CSS styles, can cause expensive repaints and reflows. Whereas a "dumb" canvas just renders a pixel snapshot of all the instructions you executed on it, it could literally support millions of cells. It's more math, it's lower-level and more performant. It is not that low-level that you have to draw each letter, it has methods like
I haven't but I know of it, as well as RxJS. I steered clear of it because IMO it's a lot of blah blah unnecessary complexity. There's even native DOM element MutationObservers. Observables are one way to keep state in sync (for other ways, see my earlier comment) but years ago the JS community decided to demonize two-way bindings (=Knockout) because of unpredictability in complex apps. 🤷 |
|
OK, let`s leave the canvas question aside. I get DOM changes may cause re-flowing, re-drawing, etc., but not if your table remains with static height of rows and width of each column. And once you change with of a column, you are going to have re-flow for the affected columns and redrawing. It is just a question of how optimized the rendering agent is. And of course WebGL is on a canvas because it's graphics. Now regarding MobX and I checked RxJS also, I agree with your "it's a lot of blah blah unnecessary complexity". I never thought of the rippling of changes as we see them in a spreadsheet as "state management". And I don't give much to "years ago the JS community decided to demonize two-way bindings (=Knockout) because of unpredictability in complex apps". I deal with complex business data and for me it's perfect. So, knockout it remains for me. We just need to fix the observable feature. First get that two-pass update algorithm fixed. And the more I think about it the clearer it is to me that we just need the mark 'dirty' phase that chases the dependencies and assembles a dirtySet, followed by one iteration over the dirtySet and update to re-evaluate anything that still isDirty, but not chase dependencies any more. I also think that given that a single user action might change more than one observable, that at that time it would be good to defer the processing of the dirtySet until all changes have been made. It's like starting a transaction and then committing it. For that, you would for each change initially only do the mark 'dirty' pass, collecting a single dirtySet across all the initial changes,, and then when the multi-change transaction is done, go through the dirtySet only once. The only other thing I'd love to change about knockout observables is to use Proxy objects so we can make ideomatic javascript transparently observable. No more |
|
The direction in which I like to go for my project is to split knockout use only the actual rendering and data binding stuff, but replace the observables. I hope I can do that. The reason is beyond the fixing of the performance, also the use of Proxy objects which avoid the need for the unwrap and function calls with and without arguments rather than just property accessor and assignment. These Proxy objects not only allow the observable feature to be completely transparent, they also allow safe navigation paths, where you don't get Null Pointer Exceptions just because some property has no value or doesn't exist. They can also help with evening out single vs. collection. Essentially, they allow me to have the power of XPath in javascript (and even more than that, including writable properties that ripple through a path and possibly cause writes higher up). But then, I am not asking anyone to do that for me, nor am I asking anyone to use what I like to use. Rather, I hope that knockout is so well done that it will be relatively easy to replace the observables and computes with my own, perhaps just having a simple compatibility layer on top of mine that knockout binding and rendering will use (e.g., the subscribe - subscription - notify callback API). The observableArrays I might do myself in other ways. Another thing that would be really cool is to just throw out all the unnecessary quirks from knockout. A clean ES6 version which has none of the workarounds for IE and nonsense like that which is fortunately not needed any more. |
|
Looks like you're reinventing vuejs (version 1) now. |
|
Vue has mutated into a very elaborated and abstract UI framwork. However if you like the simplicity and straightforward nature of KO I suggest to have a look at petite vue https://blog.logrocket.com/introduction-to-petite-vue/ which is basically a step back into the direction of knockout |
|
@gschadow , maybe you could check if the problem persists in https://github.com/knockout/tko and since it's better structured and still in beta, could take any improvements you make. |
|
It's sad that there is so little interest in this. All these references to vue and petite and this and that just looks like vultures eating off a dying carcass, trying to proselytize people. Let's summarize. The ko observables are massively flawed. Throw them out, and one can rewrite in a few screen full of code. Especially that entire "deferred" and throttled mode was unnecessary. The ko observables with the js parser trying to replace property references with observable function evaluation is not working consistently, so even my data bindings have now seen use of ko.unwrap sucked into them. A proxy based system would be much better, and again, could be done in a few screenfuls of code. No manual parsing if js expression s necessary. Lots of ko utilities like Util.arrayForEach were unnecessary even when IE was still around (there was nothing preventing me to write just to give an example. The point is you want to avoid all unnecessary branching logics like especially for arrays this should be totally unnecessary. The whole entire VDOM issue made by vue and react, is a huge red herring. It is not the reason foreach is slow in ko. Also, a refactored ko could even somehow use its own VDOM diffing tricks. But anyway, in a few years browser engines will do this diffing all by themselves on the DOM making all this complexity of VDOM approaches completely unnecessary. ko is unnecessarily obtuse. I don't know why it is trying to do so much hiding. For example, everything would be so much simpler if the current model object being bound to an element was just accessible directly from that element. (There are many more instances of ko trying to hide things in obtuse symbols, stuff that can work in debug mode suddenly breaks in the other mode. That's all not necessary. And yes it's worth rewriting ko because nothing else exists that is so well suited for simply taking HTML and binding it to data. But the benefits of ko that are so worthwhile to preserve and I see no other "templating engine" reproduce so nicely are that data binding is totally declarative and just defined in a js object. The virtual elements are nice. All the bindings are there that we need. I see the TKO approach not being a real re-take of what is good in knockout. It just looks like a next iteration with a bunch of incompatibilities so that people stopped just upgrading from major version 3 to 4. |
|
@gschadow Impressive work, sir. |
The main objective of TKO was to compartmentalize the code. The original code was basically a concatenation of source files, so for TKO I modularized it as proper ESM so it could be included. There's also been an ambition to use Typescript, and the TSX/JSX is good, but I definitely agree that there's a kernel of core principles in there that would make for a relatively very simple creature. The two main benefits of KO are that it's been used in a lot of places that are still using it, and it's quite productive in terms of binding HTML to JS. The latter could be improved with some refactoring/rewriting, but there's an incomprehensible amount of of legacy code (some of it written into regulations, standards, etc.). So these are competing. But yeah, the TKO objective wasn't meant to necessarily do more, it was to modularize it to make it maintainable and testable. The key benefit of that ought to be increased velocity. |
Isn't it the case, ($data within the binding, or ko.dataFor from the DOM)? |
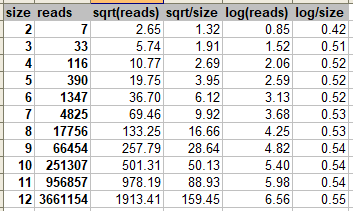
I have made a demo spreadsheet application with knockout to find out (a) how easy it is and (b) how well ko handles huge arrays of data with lots of dependencies. The result is that it's horribly slow for something that is certainly a stress-test, but Google sheets handles that with grace in 10,000 cells and more, while ko croaks in a table of only 400 cells. I first started this on stackoverflow here: https://stackoverflow.com/questions/72873850/any-way-to-make-knockout-faster-or-is-data-binding-fundamentally-flawed but then discussion ensued here which fired up my determination to prove absence of user error on my part, ultimately I created a subcribable, observable, and computed implementation with straight-forward dependency detection and propagation with objective measurements showing that knockout's is thousands-fold slower, behaves in O(e^n) time, while mine, does O(n^2). You can fast-forward to the head on comparison here below #2596 (comment) which also simmered down the code to just what matters.
By profiling I determined that the most time is spent here:
so I added this counter cccnt, and I could in a 20 x 20 table after filling it with the formula, go to J10 and add " + 1" to the formula there, something that changes the result value ( " * 1" does not).
Now here is the counts.
That's 1.4 million times evaluating for just 400 formulas (actually, in the J10 update it only affects 100 cells! This is definitely not right. When I put similar counters into my write and read functions, I get 420 writes after the whole test, which is good, but before the formula update in J10 I have read run 837 and after the update I have 706,268.
So this is clearly wrong and optimizable somehow. Since we have the dependencies once we should run the updates cascading them down one way J10 updates, the 2 immediately dependent cells are K10 and J11, so they update. Then their dependents, and so on which means only 100 cells should update. But somehow it runs amok here.
I am not sure how to start attacking this problem, but I have some optimism that it could be done. That it is actually a bug of some sort.
The text was updated successfully, but these errors were encountered: