Bu defterde parkinson hastalığını teşhis etmek için lojistik regresyon uygulayacağız, veri seti Oxford Parkinson Hastalığı Tespit Veri Setinden (https://archive.ics.uci.edu/dataset/174/parkinsons) elde edilmiştir.
-
Bu veri seti, 23'ü Parkinson hastalığı (PD) olan 31 kişiden alınan bir dizi biyomedikal ses ölçümünden oluşmaktadır. Tablodaki her sütun belirli bir ses ölçüsüdür ve her satır bu bireylere ait 195 ses kaydından birine ("isim" sütunu) karşılık gelir. Verilerin temel amacı, sağlıklı kişiler için 0, Parkinson hastaları için 1 olarak ayarlanan "durum" sütununa göre sağlıklı kişileri Parkinson hastalarından ayırmaktır.
-
Veriler ASCII CSV formatındadır. CSV dosyasının satırları, bir ses kaydına karşılık gelen bir örneği içerir. Hasta başına yaklaşık altı kayıt vardır ve hastanın adı ilk sütunda belirtilmiştir. Daha fazla bilgi almak veya yorumlarınızı iletmek için lütfen Max Little (littlem '@' robots.ox.ac.uk) ile iletişime geçin.
-
İşte pandas kullanılarak göz atılan veri kümesinin kısa bir özeti


Ek Değişken Bilgiler
- Matris sütun girişleri (öznitelikler):
- ad - ASCII konu adı ve kayıt numarası
- MDVP:Fo(Hz) - Ortalama vokal temel frekansı
- MDVP:Fhi(Hz) - Maksimum vokal temel frekansı
- MDVP:Flo(Hz) - Minimum vokal temel frekansı
- MDVP:Jitter(%),MDVP:Jitter(Abs),MDVP:RAP,MDVP:PPQ,Jitter:DDP - Temel frekanstaki çeşitli varyasyon ölçümleri
- MDVP:Parıltı,MDVP:Parıltı(dB),Parıltı:APQ3,Parıltı:APQ5,MDVP:APQ,Parıltı:DDA - Genlikteki çeşitli varyasyon ölçümleri
- NHR,HNR - Gürültünün sesteki ton bileşenlerine oranının iki ölçüsü
- durumu - Deneğin sağlık durumu (bir) - Parkinson hastası, (sıfır) - sağlıklı
- RPDE,D2 - İki doğrusal olmayan dinamik karmaşıklık ölçüsü
- DFA - Sinyal fraktal ölçeklendirme üssü
- spread1,spread2,PPE - Temel frekans değişiminin üç doğrusal olmayan ölçümü
Referans:
Little, Max. (2008). Parkinson. UCI Makine Öğrenimi Havuzu. https://doi.org/10.24432/C59C74.
Veri analizi aşaması, temel ilişkileri, dağılımları ve özellik türlerini vurgulayarak veri kümesinin anlaşılmasını sağlamayı amaçlar. Bu bilgi, ön işleme adımlarına rehberlik edecek ve Parkinson hastalığının teşhisi için etkili bir lojistik regresyon modelinin geliştirilmesine katkıda bulunacaktır.
Korelasyon analizi:
- Her bir özellik ile hedef değişken (durum) arasındaki korelasyonun araştırılması ve güçlü bir korelasyon sergileyen özelliklerin tanımlanması, çünkü bunlar teşhis sürecinde önemli bir rol oynayabilir.

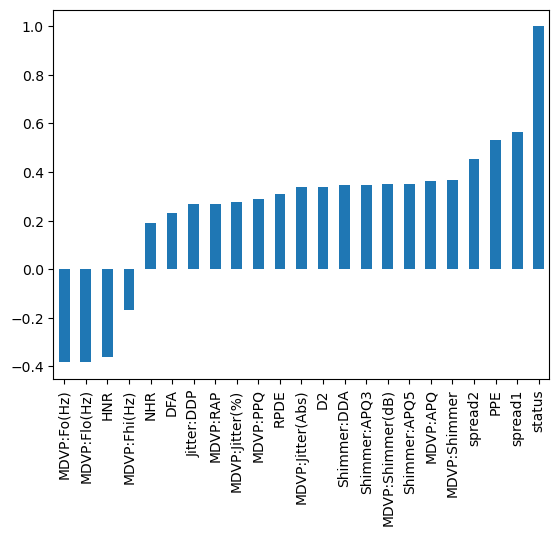
Dağıtım Analizi:
- Veri kümesindeki Parkinson hastalığının yaygınlığını anlamak ve model eğitimi ve değerlendirmesini etkileyebilecek potansiyel sınıf dengesizliklerini belirlemek için hedef değişken değerlerinin (1 ve 0) dağılımının incelenmesi.


Lojistik Regresyon (logit modeli olarak da bilinir) genellikle sınıflandırma ve tahmine dayalı analitik için kullanılır. Lojistik regresyon, bir olayın meydana gelme olasılığını tahmin eder. Sonuç bir olasılık olduğundan, bağımlı değişken burada ele aldığımız duruma uygun olarak 0 ile 1 arasında sınırlanır.
Referans:
IBM. (tarih yok). Lojistik regresyon. https://www.ibm.com/topics/logistic-regression

Sigmoid/Logistic function
Lojistik regresyon modeli şu şekilde temsil edilir:
burada
Python ile uygularsak:
def sigmoid(z):
"""
Compute the sigmoid of z
"""
g = 1 / (1 + np.exp(-z))
return g
Logistic Cost Function
Lojistik regresyon maliyet fonksiyonu şu şekildedir:
-
m veri kümesindeki eğitim örneklerinin sayısıdır
-
$loss(f_{\mathbf{w},b}(\mathbf{x}^{(i)}), y^{(i)})$ tek bir veri noktasının maliyetidir, yani -$$loss(f_{\mathbf{w},b}(\mathbf{x}^{(i)}), y^{(i)}) = (-y^{(i)} \log\left(f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) - \left( 1 - y^{(i)}\right) \log \left( 1 - f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) \tag{2}$$ -
$f_{\mathbf{w},b}(\mathbf{x}^{(i)})$ modelin tahminidir,$y^{(i)}$ ise gerçek etikettir -
$f_{\mathbf{w},b}(\mathbf{x}^{(i)}) = g(\mathbf{w} \cdot \mathbf{x^{(i)}} + b)$ burada$g$ fonksiyonu sigmoid fonksiyonudur.
Python ile uygularsak:
def compute_cost(X, y, w, b, *argv):
"""
Computes the cost over all examples
"""
m, n = X.shape
cost = 0.
for i in range(m):
z_i = np.dot(X[i], w) + b
f_wb_i = sigmoid(z_i)
cost += - y[i] * np.log(f_wb_i) - (1 - y[i]) * np.log(1 - f_wb_i)
total_cost = cost / m
return total_cost
Gradient Descent
Dereceli Azalma algoritması:
burada,
Bu compute_gradient işlevi
-
m veri kümesindeki eğitim örneklerinin sayısıdır
-
$f_{\mathbf{w},b}(x^{(i)})$ modelin tahminidir,$y^{(i)}$ ise gerçek etikettir
Python ile uygularsak:
def compute_gradient(X, y, w, b, *argv):
"""
Computes the gradient for logistic regression
"""
m, n = X.shape
dj_dw = np.zeros(w.shape)
dj_db = 0.
for i in range(m):
z_wb = np.dot(X[i], w) + b
f_wb = sigmoid(z_wb)
dj_db_i = f_wb - y[i]
dj_db += dj_db_i
for j in range(n):
dj_dw[j] += X[i, j] * dj_db_i
dj_db /= m
dj_dw /= m
return dj_db, dj_dwPython kullanılarak Lojistik Regresyondan elde edilen çıktı
Accuracy: 76.410256karşılaştırma yaparak:
- Scikit Logistic Regression
Accuracy: 89.74358974358975- Scikit MLP Classifier Neural Network
Accuracy with Neural Network: 94.87179487179486Optimum accuracy ve precision ulaşmak için özellik mühendisliği, ön işleme, hiperparametre ayarı gibi bazı parametrelerde ince ayar yapmak gerekir.