Spleeterをリリース:Deezer Researchソース分離エンジン
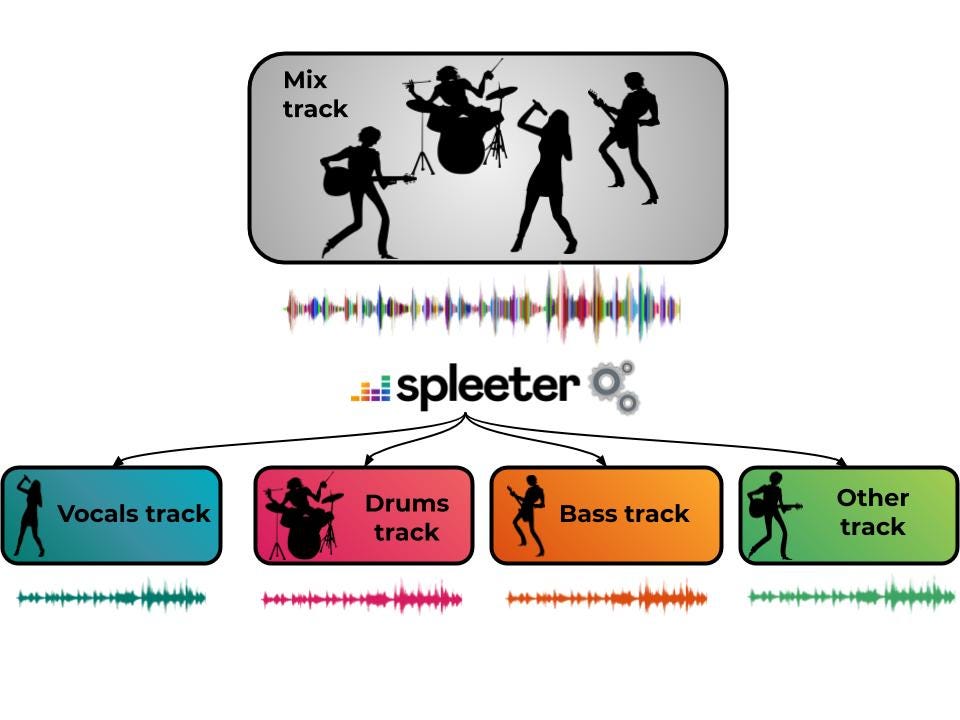
我々はSpleeterをリリースすることで、音楽情報検索(MIR)を研究するコミュニティが最先端のソース分離アルゴリズムの力をより活用できるようにします。SpleeterはTensorflowに基づいたPythonライブラリの形式で提供され、2、4、5ステムに分離できる事前学習済みモデルを備えています。Spleeterは、オランダのデルフトで開催される2019 ISMIRコンファレンスでの発表およびライブ・デモが行われる予定です。
広く知られたトピックでこそないものの、ソース分離にまつわる問題は、数十年にわたって非常に多くの音楽信号研究者から関心を持たれてきましした。一連のプロセスは簡単な観察からスタートします。そもそも音楽の録音作品は、複数の個別の楽器トラック(リード・ヴォーカル、ドラム、ベース、ピアノなど)のミックスから成り立っています。音楽ソース分離の課題は以下になります−与えられたミックスから、これらの個別のトラック(ステムと呼ばれることも)を果たして復元できるか? 潜在的に、ここには多くの用途があります。例えばリミックス、アップミキシング、アクティブ・リスニング、教育目的。他にも、採譜をはじめとする他の目的を準備することもできます。Spleeterのようなソース分離エンジンは、多くの楽器のミックスから、個々のトラック/ステムの一式を抽出します。
興味深いことに、私たちの脳は楽器の分離に非常に優れています。このトラックの楽器の1つ(たとえばリード・ヴォーカルなど)に焦点を合わせるだけで、それを他の楽器とはっきり区別して聞くことができます。しかし、同時にほかの全てのパートも聞こえるため、それは本当の意味での分離ではありません。多くの場合において、一緒にミックスされている個々のトラックを正確に復元することは不可能なのかもしれません。したがって課題は、可能な限りそれらを近似させることです。つまり、できるだけオリジナルに近づけて過度の歪みを生じさせないこと、になります。
長い期間にわたり、世界中の何十もの素晴らしい研究チームによって多くの戦略が研究されてきました。この魅力的な旅路にあなたが興味をお持ちならば、この文献の概要、もしくはこの文献をぜひお読みください。主に機械学習メソッドの上達のおかげで、進歩のペースは最近大きな飛躍を遂げました。把握のためにも、人々は国際的な評価キャンペーンで互いのアルゴリズムを比較し続けてきています。そのおかげで我々は、 Spleeter のパフォーマンスと現在提案されている最適なアルゴリズムのパフォーマンスが一致していると言えます。
加えて、 Spleeter は_とても高速_です。もしあなたがGPUバージョンを実行している場合は、 リアルタイムよりも100倍速く 分離することが期待できます。そのため、大きなデータセットを処理するのにも適しています。
かなりたくさんのこと、だと我々は考えています。もしあなたが音楽情報検索に取り組んでいる研究者で、もし常にソース分離のアーティファクトがあなたのパイプラインの前処理ステップとして不適切であると考えているなら...それではぜひ考え直して、 Spleeter を試してください。もしあなたが音楽ハッカーで Spleeter を使って何かすごいものを構築したいなら、どうぞそのまま進んでください。そもそも Spleeter はMITライセンスされているため、あなたが使いたいように自由にご使用いただけます。
言うまでもないことでしょうが、 Spleeter を著作権で保護された曲に使用する場合は、事前に権利保有者から適切な許可を得る必要があります。
Spleeter の内部はかなり複雑かつ細かく作られたエンジンですが、使いやすくするために我々はかなり努力しました。実際の分離は単一のコマンド・ラインで実現でき、オペレーティング・システムが何であろうとラップトップで作動するようになっています。より上級のユーザーに向けてSeparatorというpython APIクラスもあり、あなたの通常のパイプラインで直接操作することができます。
我々は綿密なドキュメンテーションの作成に尽力しました。従来のgithubツールから、どうぞ気軽にフィードバック、問題の指摘、改善の提案などをお寄せください。
短い回答:我々はこれを研究に使用します。皆さんもそうしたいかもしれない、と考えました。
我々は長きにわたり、ソース分離に取り組んできました(そして既にICASSP 2019で発表もしました)。
我々は Spleeter をOpen-Unmix (Inriaの研究チームが最近リリースした別のオープンソース・モデル) に対してベンチマークし、速度が向上するとパフォーマンスもわずかに向上すると報告しました(トレーニング・データセットは同一ではありません)。
MIRの研究者が直面する厳しい制限の1つに、著作権の問題のため公開のデータセットが不足していることが挙げられます。ここ Deezer ではかなり膨大なカタログにアクセスできるため、我々はそれを Spleeter の構築に活用しています。このデータを共有することはできませんが、アクセス可能なツールに変えることで我々の研究を誰でも再現できるようにしています。より倫理的な観点からみれば、著作権で保護された素材にアクセスできるかどうかを理由に、研究者間の競争に不公平があってはならないと我々は感じています。
大切なことを言い忘れていました、こういったモデルのトレーニングには多くの時間とエネルギーを必要とします。一度それを行い結果を共有することで、他の人々の手間やリソースを節約できればと我々は思っています。
Spleeter をリリースして以来、多くのフィードバックをいただきました。そのほとんどがとても好意的で、私たちの仕事が注目を集めていることをとても嬉しく思っています。ただ、いただいた反応のいくつかはやや過剰評価かもしれないため、いくつか今一度お伝えしておきます。まず、 Spleeter は整ったツールですが、我々がソース分離を_「解決した」_と主張することは決してありません。何百人もの研究者やエンジニアが何十年も取り組んできたからこそ、この進歩があり、 Spleeter のベースとなるツールが構築されました。これは生き生きと成長し続け、オープンなエコシステムに対する我々の貢献であり、他の人もさらに構築していくものであるよう願っております。
最後に、以下について触れておく必要があります。音楽ミキシングとは芸術であり、マスタリング・サウンド・エンジニアは独自の権利を持つアーティストです。我々は、明らかに、いかなる方法でも、彼らの作品を傷つけたり、誰かの信用に影響を与えるつもりはありません。あなたが Spleeter を使用する場合も、どうぞ責任とともにそのように行ってください。
みなさん、どうぞ Spleeter をお楽しみください!