Shield:
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.

@article{he2022context,
title={A context-aware deconfounding autoencoder for robust prediction of personalized clinical drug response from cell-line compound screening},
author={He, Di and Liu, Qiao and Wu, You and Xie, Lei},
journal={Nature Machine Intelligence},
volume={4},
number={10},
pages={879--892},
year={2022},
publisher={Nature Publishing Group UK London}
}
CODE-AE is a Python implementation of Context-aware Deconfounding Autoencoder (CODE-AE) that can extract common biological signals masked by context-specific patterns and confounding factors.
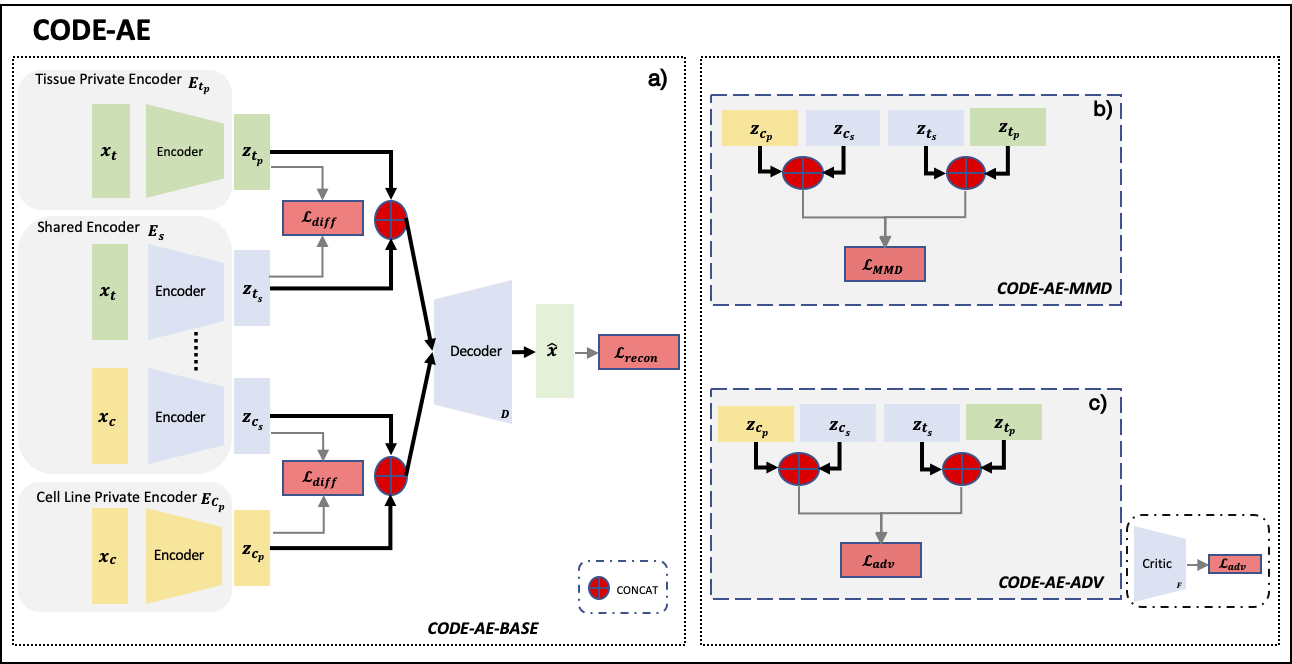
CODE-AE depends on Numpy, SciPy, PyTorch (CUDA toolkit if use GPU), scikit-learn, pandas. You must have them installed before using CODE-AE.
The simple way to install them is using Docker: the Dockerfile is given within folder code/
Benchmark datasets available at Zenodo[http://doi.org/10.5281/zenodo.4776448] (version 2.0)
$ python pretrain_hyper_main.pyArguments in this script:
--method: method to be used for encoder pre-training, choose from ['code_adv', 'dsna', 'dsn', 'code_base', 'code_mmd', 'adae', 'coral', 'dae', 'vae','vaen', 'ae']--train: retrain the encoders--no-train: no re-training--norm: use L2 normalization for embedding--no-norm: don't use L2 normalization for embedding
$ python drug_ft_hyper_main.pyArguments in this script:
--method: method to be used for encoder pre-training, choose from ['code_adv', 'dsna', 'dsn', 'code_base', 'code_mmd', 'adae', 'coral', 'dae', 'vae','vaen', 'ae']--train: retrain the encoders--no-train: no re-training--norm: use L2 normalization for embedding--no-norm: don't use L2 normalization for embedding--metric: metric used in early stopping--pdtc: fine-tune PDTC drugs (target therapy agents)--no-pdtc: fine-tune chemotherapy drugs
- adae_hyper_main.py: run ADAE de-confounding experiments
- drug_inference_main.py: generate TCGA sample prediction
- generate_encoded_features.py: generate encoded features by pre-trained encoders
- ml_baseline.py: get benchmark experiments' results using random forest and elastic net
- mlp_main.py: get benchmark experiments' results using simple multi-layer neural network
- tcrp_main.py: get benchmark experiments' results using TCRP
- vaen_main.py: get benchmark experiments' results using VAEN (VAE+elastic net)