Page not found :(
+The page you are looking for doesn't exist or has been moved.
+The page you are looking for doesn't exist or has been moved.
+这里列出部分 Databend 设计和实现过程中参考和借鉴的论文,供感兴趣的朋友阅读。
+Databend 除了支持本机构建外,还可以使用 build tool 来进行跨平台构建。
+Databend 在 Makefile 中封装了大量常见命令。采用 make 构建只会开启默认特性,并且会一次性构建 databend-meta、databend-query 以及 databend-metactl 。
按 前文 设置好开发环境后。
+make build 即可轻松构建 debug 版本。make build-release 则会构建 release 版本,并会采用 objcopy 减少二进制体积。使用 cargo 构建的好处在于可以按需开启特性,并灵活控制要构建的目标二进制文件。
+常用的命令格式如:
+RUSTFLAGS="--cfg tokio_unstable" cargo build --bin=databend-query --features=tokio-console
+即可构建启用 tokio-console 支持的 databend-query ,使用 RUSTFLAGS="--cfg tokio_unstable" 是因为 tokio 的 tracing 特性还没有稳定下来。
Databend features 速览
+simd = ["common-arrow/simd"]:默认开启的特性,启用 arrow2 的 SIMD 支持(meta & query)。tokio-console = ["common-tracing/console", "common-base/tracing"]:用于 tokio 监控和调试,(meta & query)。memory-profiling = ["common-base/memory-profiling", "tempfile"]:用于内存分析,(meta & query)。storage-hdfs = ["opendal/services-hdfs", "common-io/storage-hdfs"]:用于提供 hdfs 支持,(query)。hive = ["common-hive-meta-store", "thrift", "storage-hdfs"]:用于提供 hive 支持,(query)。Databend 提供了 build-tool image,可以简化跨平台构建所需工作。
+示例选用 x86_64-unknown-linux-musl 目标平台,其他支持平台也类似:
IMAGE='datafuselabs/build-tool:x86_64-unknown-linux-musl' RUSTFLAGS='-C link-arg=-Wl,--compress-debug-sections=zlib-gabi' ./scripts/setup/run_build_tool.sh cargo build --target x86_6
+4-unknown-linux-musl
+在最近的一个 Issue 中 (#9387),Databend 社区的朋友希望能够通过 PGO 构建性能优化的二进制。让我们一起来看一下如何使用 Rust 构建 PGO 优化后的 Databend 吧!
+Profile-guided optimization 是一种编译器优化技术,它会收集程序运行过程中的典型执行数据(可能执行的分支),然后针对内联、条件分支、机器代码布局、寄存器分配等进行优化。
+引入这一技术的背景是:编译器中的静态分析技术能够在不执行代码的情况下考虑代码优化,从而提高编译产物的性能;但是这些优化并不一定能够完全有效,在缺乏运行时信息的情况下,编译器无法考虑到程序的实际执行。
+PGO 可以基于应用程序在生产环境中的场景收集数据,从而允许优化器针对较热的代码路径优化速度并针对较冷的代码路径优化大小,为应用程序生成更快和更小的代码。
+rustc 支持 PGO ,允许创建内置数据收集的二进制文件,然后在运行过程中收集数据,从而为最终的编译优化做准备。其实现完全依赖 LLVM 。
+构建 PGO 优化的二进制文件通常需要进行以下几步工作:
+.proraw 的形式存在.proraw 文件转换为 .prodata 文件.prodata 文件进行构建优化运行过程中的收集到的数据最终需要使用 llvm-profdata 进行转换,经由 rustup 安装 llvm-tools-preview 组件可以提供 llvm-profdata ,或者也可以考虑使用最近版本的 LLVM 和 Clang 提供的这一程序。
rustup component add llvm-tools-preview
+安装之后的 llvm-profdata 可能需要被添加到 PATH ,路径如下:
~/.rustup/toolchains/<toolchain>/lib/rustlib/<target-triple>/bin/
+这里并没有选用某个具体生产环境的工作负载,而是使用 Databend 的 SQL 逻辑测试作为一个示范。在性能上可能并不具有积极意义,但可以帮助我们了解如何进行这一过程。
+++特别提示: 提供给程序的数据样本必须在统计学上代表典型的使用场景; 否则,反馈有可能损害最终构建的整体性能。
+
清除旧数据
+rm -rf /tmp/pgo-data
+编译支持收集 profile 数据的 release ,使用 RUSTFLAGS 可以将 PGO 编译标志应用到所有 crates 的编译中。
RUSTFLAGS="-Cprofile-generate=/tmp/pgo-data" \
+cargo build --release --target=x86_64-unknown-linux-gnu
+运行编译好的程序,实际情况下推荐使用符合生产环境典型工作负载的数据集和查询。
+示例中选择执行 SQL 逻辑测试,仅供参考。
+BUILD_PROFILE=release ./scripts/ci/deploy/databend-query-standalone.sh
+ulimit -n 10000;ulimit -s 16384; cargo run -p sqllogictests --release -- --enable_sandbox --parallel 16 --no-fail-fast
+使用 llvm-profdata 合并 profile 数据
llvm-profdata merge -o /tmp/pgo-data/merged.profdata /tmp/pgo-data
+在 profile 数据指导下进行编译,其实可以注意到,两次编译都使用 --release 标志,因为实际运行情况下,我们总是使用 release 构建的二进制。
RUSTFLAGS="-Cprofile-use=/tmp/pgo-data/merged.profdata -Cllvm-args=-pgo-warn-missing-function" \
+cargo build --release --target=x86_64-unknown-linux-gnu
+再次运行编译好的程序,运行之前的工作负载以检查性能。
+BUILD_PROFILE=release ./scripts/ci/deploy/databend-query-standalone.sh
+ulimit -n 10000;ulimit -s 16384; cargo run -p sqllogictests --release -- --enable_sandbox --parallel 16 --no-fail-fast
+工欲善其事,必先利其器。在开启 Databend 贡献之旅前,一起来配置适合自己的开发环境吧。
+为方便开发者快速建立开发环境,Databend 维护了一个复杂的 shell 脚本,位于 scripts/setup/dev_setup.sh 。
只需执行一条指令即可完成开发环境配置:
+$ make setup -d
+++注意:此过程会辅助安装部分 python 环境,可能会对本地原开发环境造成影响,建议预先执行以下命令以创建并启用专属虚拟环境。
++$ python -m venv .databend +$ source .databend/bin/activate +
如果遇到依赖缺失问题,可以参考「分步安装 - 测试必备」这一部分的内容安装。
+这里以 Fedora 36 为例,考虑到不同系统和发行版之间的差异,你可能需要自行安装 gcc,python 和 openssl 。
推荐使用 rustup 来管理 Rust toolchain ,参考 https://rustup.rs/ 进行安装。
+对于 MacOS 和 Linux 用户,执行:
+$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
+Databend 通常使用最新发布的 nightly 工具链进行开发,相关信息记录在 rust-toolchain.toml 中。
Rustup 会在使用时对工具链进行自动重载,安装时只需默认配置。
+$ cargo build
+info: syncing channel updates for 'nightly-2022-05-19-x86_64-unknown-linux-gnu'
+info: latest update on 2022-05-19, rust version 1.63.0-nightly (cd282d7f7 2022-05-18)
+以下列出了一些安装构建和测试必备依赖的关键步骤,说明及报错信息以注释形式呈现。
+构建必备
+# common-hive-meta-store 需要,thrift not found
+$ sudo dnf install thrift
+# openssl-sys 需要,Can't locate FindBin.pm, File/Compare.pm in @INC
+$ sudo dnf install perl-FindBin perl-File-Compare
+# prost-build 需要,is `cmake` not installed?
+# The CMAKE_CXX_COMPILER: c++ is not a full path and was not found in the PATH.,安装 clang 时也会安装 gcc-c++ 和 llvm
+$ sudo dnf install cmake clang
+测试必备
+# 功能测试和后续体验需要
+$ sudo dnf install mysql
+# 包含目前功能测试和 lint 需要的所有 Python 依赖
+$ cd tests
+$ pip install poetry
+$ poetry install
+$ poetry shell
+# sqllogic 测试需要(包含在上面步骤中,按需选用)
+(tests) $ cd logictest
+$ pip install -r requirements.txt
+# fuzz 测试需要
+(tests) $ cd fuzz
+$ pip install -r requirements.txt
+Lint 必备
+# taplo fmt 需要
+$ cargo install taplo-cli
+
rust-analyzer
+crates
+CodeLLDB
+Remote - Containers
+安装「Remote - Containers」插件,打开 Databend 后会看到右下角弹出窗口并提示「Reopen in Container」。
+安装 Docker
+根据 Docker Docs - Install 安装并启动对应你发行版的 docker 。
+以 Fedora 36 为例,步骤如下:
# 移除旧版本 docker
+$ sudo dnf remove docker \
+ docker-client \
+ docker-client-latest \
+ docker-common \
+ docker-latest \
+ docker-latest-logrotate \
+ docker-logrotate \
+ docker-selinux \
+ docker-engine-selinux \
+ docker-engine
+# 设置存储库
+$ sudo dnf -y install dnf-plugins-core
+$ sudo dnf config-manager \
+ --add-repo \
+ https://download.docker.com/linux/fedora/docker-ce.repo
+# 安装 Docker Engine
+$ sudo dnf install docker-ce docker-ce-cli containerd.io docker-compose-plugin
+将当前 User 添加到 'docker' group 中
+参考 Docker Docs - PostInstall 中 Manage Docker as a non-root user 一节配置,可能需要重启。
+步骤如下:
+# 添加 docker 用户组
+$ sudo groupadd docker
+# 将用户添加到 docker 这个组中
+$ sudo usermod -aG docker $USER
+# 激活更改
+$ newgrp docker
+# 更改权限以修复 permission denied
+$ sudo chown "$USER":"$USER" /home/"$USER"/.docker -R
+$ sudo chmod g+rwx "$HOME/.docker" -R
+其他步骤
+启用 Docker :
+$ sudo systemctl start docker
+点击左下角「打开远程窗口」选中「Reopen in Container」即可体验。
+这里列出一些可能有助于 Databend 开发的实用工具,根据实际情况按需选用。
+轻量级、反应迅速、可无限定制的高颜值终端!
+ +
参考 starship - installation 进行安装。
+curl -sS https://starship.rs/install.sh | sh
+命令行基准测试工具。
+ +参考 hyperfine - installation 进行安装。
+cargo install hyperfine
+开发和调试 Databend 时,难免会遇到一些小问题,这里列出一些解决方案供大家参考。
+下面是 16g 内存的一台设备编译 Databend 时的 Swap 情况。
+$> swapon -s
+Filename Type Size Used Priority
+/dev/nvme0n1p3 partition 134217724 32632196 50
+/dev/zram0 partition 8388604 8388264 100
+通常情况下,OOM 会在链接阶段发生。一些可能有效的解决方案包括:
+可以参考下面内容:
+用于判断兼容性的代码会检查当前的 tag,可能是 fork 的 tags 落后于 datafuselabs/databend 。
+$> git fetch git@github.com:datafuselabs/databend.git --tags
+protoc 现在可以随源码一起构建,考虑到发行版中的 protoc 版本不好统一,建议删除并重新构建项目源码。
提示需要 lzma,安装 xz 或者 lzip 可以解决。
Undefined symbols for architecture x86_64:
+ "_lzma_auto_decoder", referenced from:
+ xz2::stream::Stream::new_auto_decoder::hc1bac2a8128d00b2 in databend_query-6ac85c55ade712f3.xz2
+ld: symbol(s) not found for architecture x86_64
+clang: error: linker command failed with exit code 1 (use -v to see invocation)
+Databend 的设计目标之一就是保持最佳性能,为了更好观测和评估性能,社区不光提供一套简单的本地基准测试方案,还建立了可视化的持续基准测试。
+hyperfine 是一种跨平台的命令行基准测试工具,支持预热和参数化基准测试。
+Databend 建议使用 hyperfine 通过 ClickHouse / MySQL 客户端执行基准测试,本文将使用 MySQL 客户端来介绍它。
+进行本地基准测试之前,必须完成以下几项准备工作:
+根据你的数据集特征和关键查询设计 SQL 语句,如果需要预先加载数据,请参考 Docs - Load Data 。
+为方便示范,这里选用 Continuous Benchmarking - Vectorized Execution Benchmarking 列出的 10 条语句,保存到 bench.sql 中。
SELECT avg(number) FROM numbers_mt(100000000000)
+SELECT sum(number) FROM numbers_mt(100000000000)
+SELECT min(number) FROM numbers_mt(100000000000)
+SELECT max(number) FROM numbers_mt(100000000000)
+SELECT count(number) FROM numbers_mt(100000000000)
+SELECT sum(number+number+number) FROM numbers_mt(100000000000)
+SELECT sum(number) / count(number) FROM numbers_mt(100000000000)
+SELECT sum(number) / count(number), max(number), min(number) FROM numbers_mt(100000000000)
+SELECT number FROM numbers_mt(10000000000) ORDER BY number DESC LIMIT 10
+SELECT max(number), sum(number) FROM numbers_mt(1000000000) GROUP BY number % 3, number % 4, number % 5 LIMIT 10
+下面给出一个 benchmark.sh 范本,可以简化整个基准测试流程:
#!/bin/bash
+
+WARMUP=3
+RUN=10
+
+export script="hyperfine -w $WARMUP -r $RUN"
+
+script=""
+function run() {
+ port=$1
+ sql=$2
+ result=$3
+ script="hyperfine -w $WARMUP -r $RUN"
+ while read SQL; do
+ n="-n \"$SQL\" "
+ s="echo \"$SQL\" | mysql -h127.0.0.1 -P$port -uroot -s"
+ script="$script '$n' '$s'"
+ done <<< $(cat $sql)
+
+ script="$script --export-markdown $result"
+ echo $script | bash -x
+}
+
+
+run "$1" "$2" "$3"
+在这个脚本中:
+-w/--warmup & WARMUP 在实际基准测试之前运行 3 次程序执行来预热。-r/--runs & RUN 要求执行 10 次基准测试。在使用前需要先运行 chmod a+x ./benchmark.sh 赋予其可执行权限。
用法如下所示:
+./benchmark.sh <port> <sql> <result>
+在这个例子中,MySQL 兼容服务的端口是 3307 ,基准测试用到的 SQL 文件为 bench.sql , 预期的输出在 databend-hyperfine.md 。
./benchmark.sh 3307 bench.sql databend-hyperfine.md
+当然,你可以根据自己的配置和需要进行调整。
+++注意:下面的示例是在 AMD Ryzen 9 5900HS & 16GB RAM 配置下运行产生,仅供参考。
+
终端中的输出如下所示:
+Benchmark 1: "SELECT avg(number) FROM numbers_mt(100000000000)"
+ Time (mean ± σ): 3.486 s ± 0.016 s [User: 0.003 s, System: 0.002 s]
+ Range (min … max): 3.459 s … 3.506 s 10 runs
+最终的结果会保存在 databend-hyperfine.md 中,如下所示。
| Command | Mean [s] | Min [s] | Max [s] | Relative |
|---|---|---|---|---|
"SELECT avg(number) FROM numbers_mt(100000000000)" | 3.690 ± 0.193 | 3.425 | 4.086 | 2.58 ± 0.16 |
"SELECT sum(number) FROM numbers_mt(100000000000)" | 3.660 ± 0.156 | 3.386 | 3.911 | 2.56 ± 0.13 |
"SELECT min(number) FROM numbers_mt(100000000000)" | 9.581 ± 0.158 | 9.246 | 9.884 | 6.69 ± 0.23 |
"SELECT max(number) FROM numbers_mt(100000000000)" | 6.388 ± 0.142 | 6.203 | 6.624 | 4.46 ± 0.17 |
"SELECT count(number) FROM numbers_mt(100000000000)" | 2.647 ± 0.108 | 2.424 | 2.757 | 1.85 ± 0.09 |
"SELECT sum(number+number+number) FROM numbers_mt(100000000000)" | 19.408 ± 1.125 | 17.857 | 21.616 | 13.55 ± 0.89 |
"SELECT sum(number) / count(number) FROM numbers_mt(100000000000)" | 3.869 ± 0.133 | 3.600 | 4.073 | 2.70 ± 0.12 |
"SELECT sum(number) / count(number), max(number), min(number) FROM numbers_mt(100000000000)" | 15.488 ± 0.263 | 15.133 | 16.064 | 10.81 ± 0.38 |
"SELECT number FROM numbers_mt(10000000000) ORDER BY number DESC LIMIT 10" | 2.971 ± 0.085 | 2.871 | 3.186 | 2.07 ± 0.09 |
"SELECT max(number), sum(number) FROM numbers_mt(1000000000) GROUP BY number % 3, number % 4, number % 5 LIMIT 10" | 1.432 ± 0.044 | 1.399 | 1.545 | 1.00 |
Databend 的持续基准测试由 GitHub Action + Vercel + DatabendCloud 强力驱动,在 datafuselabs/databend-perf 这个 repo 中开源了源代码和 Workflow 。
+项目布局
+.
+├── .github/workflows # 持续集成工作流
+├── benchmarks # YAML 格式的 SQL Query 测试套件
+├── collector # 分类存放性能数据
+├── front # 可视化前端
+├── reload # YAML 格式的 Data Load 测试套件
+└── script # 数据预处理脚本
+Workflow
+持续基准测试工作流定时计划执行,Perf Workflow 会在每天 00:25 UTC(北京时间 08:25)执行,Reload Workflow 会在每周五 08:25 UTC(北京时间 16:25)执行。
+databend-perf 中的测试套件分为 Query Benchmark 和 Load Benchmark 两类,前者放在 benchmarks 目录下,后者放在 reload 目录下。
+测试用 YAML 格式定义:
+metadata:
+ table: numbers
+
+statements:
+ - name: Q1
+ query: "SELECT avg(number) FROM numbers_mt(10000000000);"
+metadata 中的 table 字段是必须的,且分配给每类 benchmark 的值都唯一。statements 则只需要指定 name 和 query 。
向量化执行基准测试
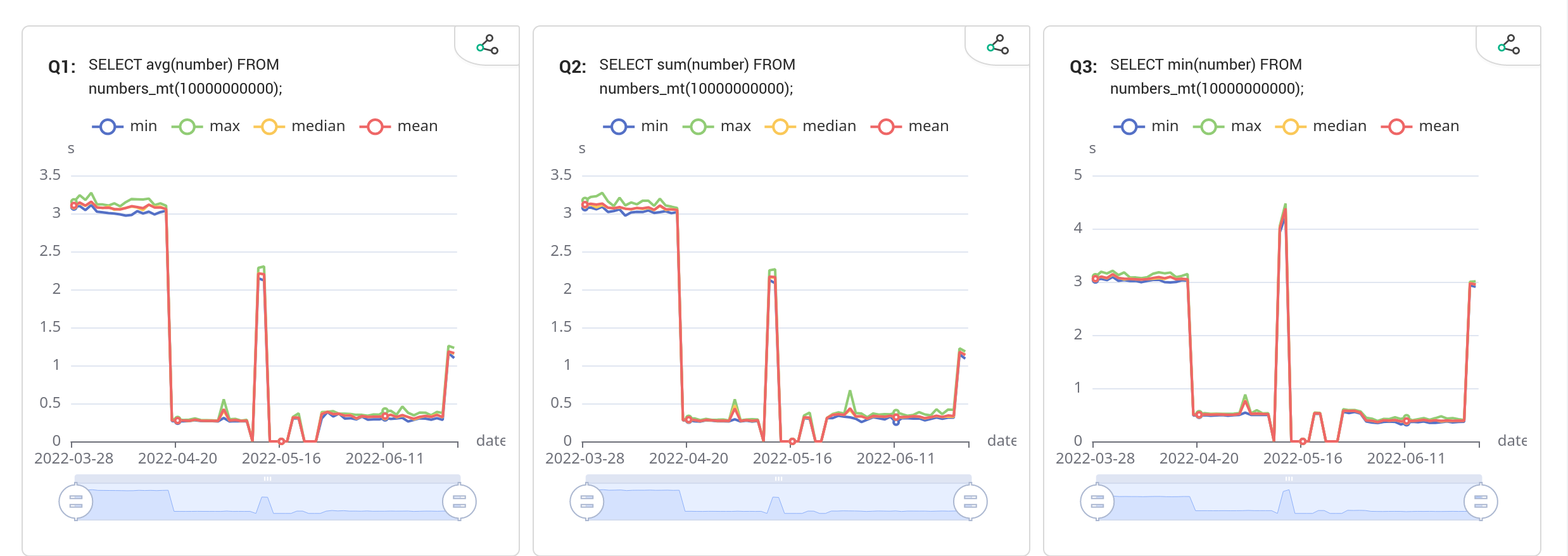
+定义在 benchmarks/numbers.yaml ,一组数值计算 SQL,利用 Databend 的 numbers 表函数提供百亿级别的数据量。
+完整语句也可以在 Continuous Benchmarking - Vectorized Execution Benchmarking 查看。
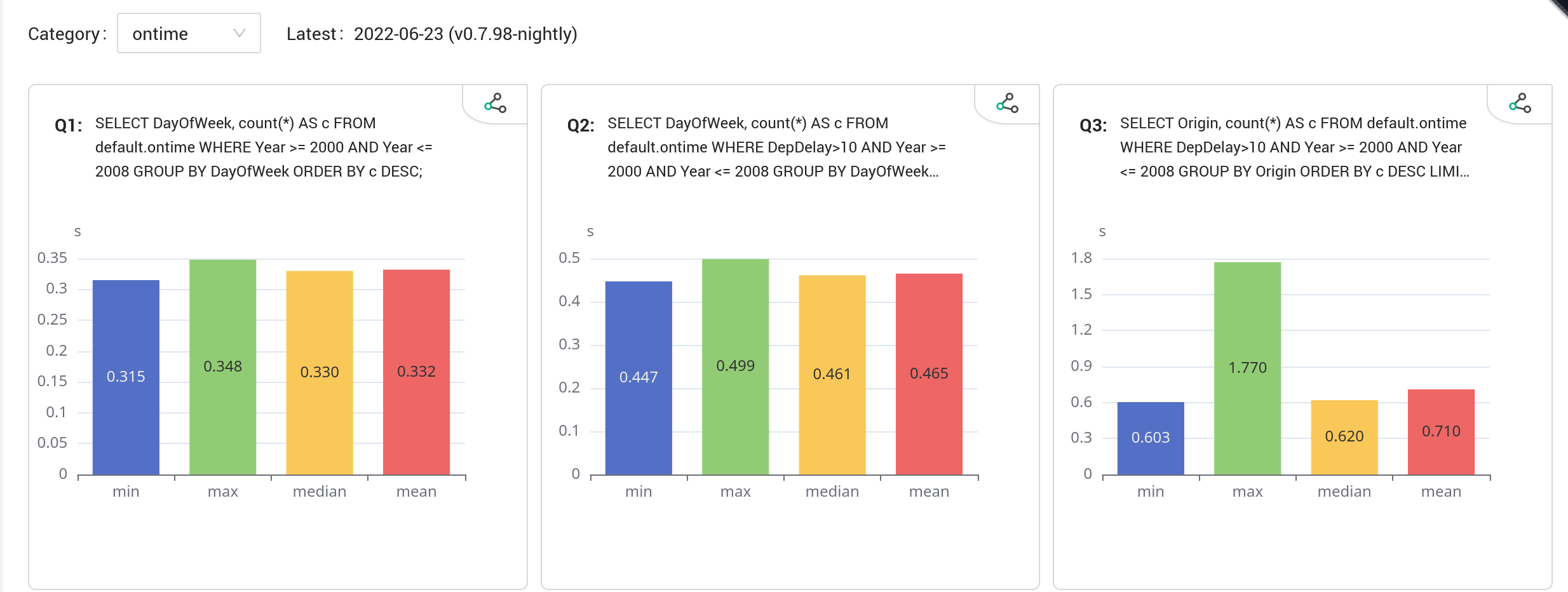
+Ontime 常见分析场景基准测试
+定义在 benchmarks/ontime.yaml ,一组常见的空中交通分析 SQL ,基于美国交通部公开的 OnTime 数据集,共计 202,687,654 条记录。
+当前此基准测试不包含 JOIN 语句,Q5、Q6、Q7 均采用优化后的形式。
+完整语句也可以在 Continuous Benchmarking - Ontime Benchmarking 查看。
+Ontime 数据集载入基准测试
+定义在 reload/ontime.yaml ,同样基于美国交通部公开的 OnTime 数据集,通过 s3 进行 COPY INTO 。
+关键语句:
+COPY INTO ontime FROM 's3://<bucket>/m_ontime/'
+credentials=(aws_key_id='AWS_KEY_ID' aws_secret_key='AWS_SECRET_KEY')
+pattern ='.*[.]csv' file_format=(type='CSV' field_delimiter='\t' record_delimiter='\n' skip_header=1);
+上面 SQL 语句中的 m_ontime/ 目录即为数据集:由原来 60.8 GB 数据全部合并后,再拆分成 100 个大小相近的文件。
基准测试得到的数据是 Json 格式的,会分类存放到 collector 这个目录下。
+metadata 部分是包含表、版本、机器规格的信息;schema 部分则是对每条语句执行情况的统计,包括中位数、平均数等。
示例:
+{
+ "metadata":{
+ "table":"numbers",
+ "tag":"v0.7.92-nightly",
+ "size":"Large"
+ },
+ "schema":[
+ {
+ "name":"Q1",
+ "sql":"SELECT avg(number) FROM numbers_mt(10000000000);",
+ "min":0.305,
+ "max":0.388,
+ "median":0.354,
+ "std_dev":0.02701407040784487,
+ "read_row":10000000000,
+ "read_byte":80000000000,
+ "time":[
+ 0.315,
+ 0.326,
+ ...
+ ],
+ "error":[
+
+ ],
+ "mean":0.34774024905853534
+ },
+ ...
+ ]
+}
+经由 stript/transform.go 处理,为每个查询的对应图表聚合数据,主要强调最大、最小、均值、中位数四个指标。
示例:
+{
+ "title":"Q1",
+ "sql":"SELECT avg(number) FROM numbers_mt(10000000000);",
+ "lines":[
+ {
+ "name":"min",
+ "data":[
+ 3.084,
+ 3.097,
+ 3.043,
+ ...
+ ],
+ ...
+ }
+ ],
+ "version":[
+ "v0.7.0-nightly",
+ "v0.7.1-nightly",
+ "v0.7.2-nightly",
+ ...
+ ],
+ "legend":[
+ "min",
+ ...
+ ],
+ "xAxis":[
+ "2022-03-28",
+ "2022-03-29",
+ "2022-03-30",
+ ...
+ ],
+}
+目前可视化方案采用 React + Echarts 实现,每个图表都对应上面处理得到的一个 Json 文件。在添加新的基准测试后,无需修改前端即可展现新的图表。
+Graphs
+
Compare
+
Status
+
目前 https://perf.databend.rs 为 Databend 提供了基本的持续性能监控方案,但仍然需要关注以下几个方向的内容:
+Databend 是一个开源的云数仓项目,这意味着你可以轻松参与“设计->研发->使用->反馈”的整个链路。这篇文章总结了参与 Databend 开源协作时需要注意的一些事项,以使贡献流程更加清晰和透明。+
在这篇文章中,主要从“沟通”和“实施”两个方面介绍 Databend 的开源协作。
+沟通是参与开源的重要环节,正是得益于开源世界中沟通的公开与透明,才能迸发出如此生机与活力。
+参与 Databend 开源协作的主要沟通方式有 Issues 、RFCs 以及 Channels 三种。
+Issues 通常用于 Bug 反馈和新特性请求,Databend 使用 GitHub Issues 来跟踪和管理这些反馈。
+https://github.com/datafuselabs/databend/issues/new/choose
+Bug 反馈
+Databend 提供了一个基本的 Bug 反馈模板以确保沟通的顺畅进行。
+在进行 Bug 反馈之前,请检索是否存在已知的解决方案,并确定你正在运行的版本,最好包含 commit id 。
当然,提供清晰的问题描述和可复现步骤也是非常重要的环节。
+好例子:https://github.com/datafuselabs/databend/issues/6564
+++Databend 的迭代速度非常快,每天都会发布新的 nightly 供用户尝鲜,建议尝试新版本以确定能否复现。
+
新特性请求
+对于新特性请求,请尽可能提供详细的描述或是预期的行为,如果有可以参考的文档就更好了。
+好例子:https://github.com/datafuselabs/databend/issues/5979
+对于小的功能点,打开 Issues 进行沟通就足够了。而大的功能、设计上的变动或者是需要充分讨论和同步的想法,请以 RFC 的形式提交。
+在设计和沟通的早期阶段,推荐使用 Discusssions 进行讨论。
+一旦确认实施和落地,提交 RFC 文档并建立用于跟踪的 Issues 则是更为合适的做法。
+好例子:https://github.com/datafuselabs/databend/discussions/5438
+Channels 通常用于一般的交流和讨论,Databend 团队鼓励使用 GitHub Discusssions 进行一般问题的咨询和讨论,形成一个“知识库”,方便检索和参与。
+当然,Databend 也提供 Slack 频道和微信群用于日常交流与讨论。
+Slack:https://link.databend.rs/join-slack
+进入到实施环节,你将亲自动手改进 Databend 的代码或者文档,并踏上成为 Databend 维护者的道路,接下来让我们一起看一下有哪些环节需要重视。
+前置环境
+在「Databend 贡献之路 | 如何设置 Databend 开发环境」一文中,已经详细介绍过如何配置 Databend 开发环境。
+需要注意的是,考虑到不同系统和发行版之间的差异,你可能需要自行安装 gcc,python 和 openssl 等相关基础程序。
代码文档
+任何公共字段、函数和方法都应该用 Rustdoc 进行文档化。
+必要的时候,请使用 Diagon 或其他 ASCII 图像生成器生成示意图以对设计进行充分描述。
+下面给出一个简单的例子:
+/// Represents (x, y) of a 2-dimensional grid
+///
+/// A line is defined by 2 instances.
+/// A plane is defined by 3 instances.
+#[repr(C)]
+struct Point {
+ x: i32,
+ y: i32,
+}
+前置环境
+本机上需要安装有用于 node 环境管理的 nvm ,以及用于 node 依赖管理的 yarn 。
文档的开发环节需要进入 website 目录后根据 README.md 中的描述进行配置。
通常情况下,包含以下步骤:
+node 版本:nvm useyarn installyarn start重要提示
+文档应当正确放置在 docs 目录下,请本地预览确认无误后再进行提交。
最终文档会托管到 https://databend.rs 。
+License 检查
+如果引入了新文件,建议执行 License 以确认是否添加了合适的许可信息。对于非代码文件,可能需要编辑 .licenserc.yaml 以跳过检查。
make check-license
+代码风格
+请运行下述命令以完成代码风格的统一:
+make lint
+依赖审计
+如果你引入了一些新的依赖项,可以使用:
+cargo udeps --workspace
+cargo audit
+测试
+在「Databend 贡献之路 | 如何为 Databend 添加新的测试」中,已经对测试做了详细的描述。
+通常情况下,使用 make test 一次性执行 单元测试 和 功能测试 就可以。
但是,也建议执行 集群 相关的测试,以确保分布式执行不会出现差错。
一般流程
+make lint 。@mergify 的回复,它会提供一些指导。PR 标题填写
+PR 标题需要符合 <类型>(<范围>): <描述> 的约束。
fix(query): fix group by string bug
+^--^ ^------------^
+| |
+| +-> Summary in present tense.
+|
++-------> Type: feat, fix, refactor, ci, build, docs, website, chore
+PR 模板填写
+Databend 提供了一个基本的 PR 模板,请不要修改模板上下文,并填充对本次 PR 的总结信息,包括是否修复/修复了哪个已知的 Issue 。
+I hereby agree to the terms of the CLA available at: https://databend.rs/dev/policies/cla/
+
+## Summary
+
+Summary about this PR
+
+Fixes #issue
+好例子:https://github.com/datafuselabs/databend/pull/6665
+持续集成相关的文件位于 .github 目录中的 actions 和 workflows 目录下。
文档
+文档相关的持续集成会通过 Vercel 进行,需要关注 Status ,并点击 Visit Preview 查看渲染情况。
检查
+包括 License 检查、代码风格检查、依赖关系审计等内容。
+构建
+主要是测试跨平台构建,主要是针对 x86_64 和 aarch64 架构,对 Linux 的 GNU 和 MUSL 支持处于第一优先级别。MacOS 虽然标记为 optional ,但是需要尽量保证。
+测试
+主要是执行各种测试确保代码和功能都符合要求,包括单元测试、功能测试、分布式测试、模糊测试等:
+有两位或两位以上维护者投下赞同票,并满足下述条件,Mergify 将会帮助我们完成代码合并工作:
+在合并之后,你的 git name 将收集在 Databend 的 system.contributors 表中,在新版本 release 之后,执行 SELECT * FROM system.contributors 即可查看。
Databend 整合了一些性能剖析工具,可以方便进行深入分析。本文将会介绍如何进行 CPU / Memory Profiling 。
+CPU 分析,按照一定的频率采集所监听的应用程序 CPU(含寄存器)的使用情况,可确定应用程序在主动消耗 CPU 周期时花费时间的位置。
+pprof 是 Google 开源的代码性能分析工具,可以直接生成代码分析报告,不仅支持通过命令式交互查看,也便于可视化展示。Databend 使用 pprof-rs 完成对 pprof 工具的支持。
+go tool pprof http://localhost:<your-databend-port>/debug/pprof/profile?seconds=<your-profile-second>
+若 http 端口为 8080 ,采样时间为 20 秒,结果示例如下:
+$ go tool pprof http://localhost:8080/debug/pprof/profile?seconds=20
+Fetching profile over HTTP from http://localhost:8080/debug/pprof/profile?seconds=20
+Saved profile in ~/pprof/pprof.samples.cpu.001.pb.gz
+Type: cpu
+Time: Jul 15, 2022 at 9:45am (CST)
+Duration: 20s, Total samples = 141.41ms ( 0.71%)
+Entering interactive mode (type "help" for commands, "o" for options)
+(pprof) top
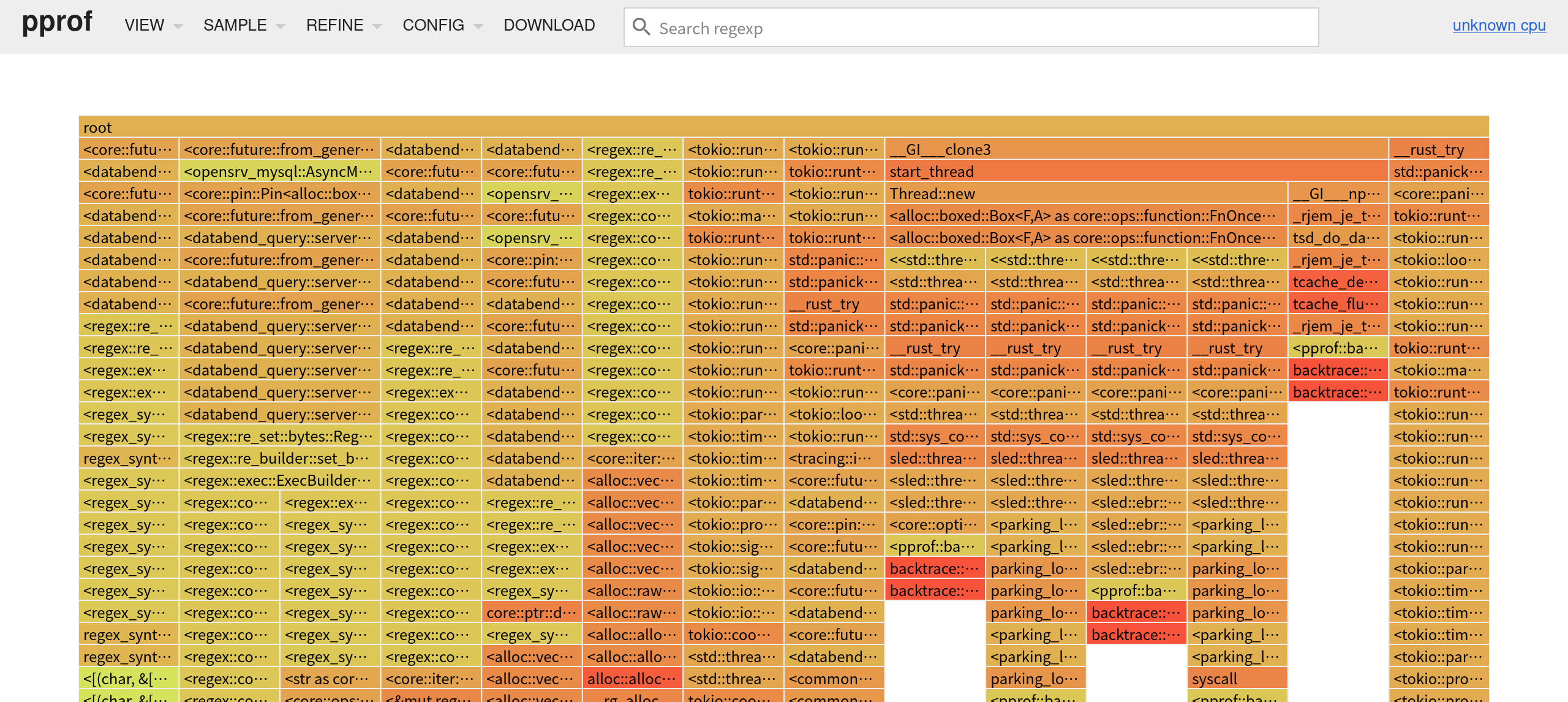
+Showing nodes accounting for 141.41ms, 100% of 141.41ms total
+Showing top 10 nodes out of 218
+ flat flat% sum% cum cum%
+ 141.41ms 100% 100% 141.41ms 100% backtrace::backtrace::libunwind::trace
+ 0 0% 100% 10.10ms 7.14% <&mut regex_syntax::utf8::Utf8Sequences as core::iter::traits::iterator::Iterator>::next
+ 0 0% 100% 10.10ms 7.14% <<std::thread::Builder>::spawn_unchecked_<sled::threadpool::queue::spawn_to<sled::pagecache::iterator::scan_segment_headers_and_tail::{closure#0}::{closure#0}, core::option::Option<(u64, sled::pagecache::logger::SegmentHeader)>>::{closure#0}::{closure#0}, ()>::{closure#1} as core::ops::function::FnOnce<()>>::call_once::{shim:vtable#0}
+ 0 0% 100% 10.10ms 7.14% <<std::thread::Builder>::spawn_unchecked_<sled::threadpool::queue::spawn_to<sled::pagecache::iterator::scan_segment_headers_and_tail::{closure#0}::{closure#0}, core::option::Option<(u64, sled::pagecache::logger::SegmentHeader)>>::{closure#0}::{closure#1}, ()>::{closure#1} as core::ops::function::FnOnce<()>>::call_once::{shim:vtable#0}
+ 0 0% 100% 10.10ms 7.14% <<std::thread::Builder>::spawn_unchecked_<sled::threadpool::queue::spawn_to<sled::pagecache::iterator::scan_segment_headers_and_tail::{closure#0}::{closure#0}, core::option::Option<(u64, sled::pagecache::logger::SegmentHeader)>>::{closure#0}::{closure#2}, ()>::{closure#1} as core::ops::function::FnOnce<()>>::call_once::{shim:vtable#0}
+ 0 0% 100% 10.10ms 7.14% <<std::thread::Builder>::spawn_unchecked_<sled::threadpool::queue::spawn_to<sled::pagecache::iterator::scan_segment_headers_and_tail::{closure#0}::{closure#0}, core::option::Option<(u64, sled::pagecache::logger::SegmentHeader)>>::{closure#0}::{closure#3}, ()>::{closure#1} as core::ops::function::FnOnce<()>>::call_once::{shim:vtable#0}
+ 0 0% 100% 10.10ms 7.14% <[&str]>::iter
+ 0 0% 100% 10.10ms 7.14% <[(char, &[char])]>::binary_search_by::<<[(char, &[char])]>::binary_search_by_key<char, regex_syntax::unicode::simple_fold::imp::{closure#0}>::{closure#0}>
+ 0 0% 100% 10.10ms 7.14% <[(char, &[char])]>::binary_search_by_key::<char, regex_syntax::unicode::simple_fold::imp::{closure#0}>
+ 0 0% 100% 10.10ms 7.14% <[(char, &[char])]>::binary_search_by_key::<char, regex_syntax::unicode::simple_fold::imp::{closure#0}>::{closure#0}
+执行下述命令可以进行可视化:
+go tool pprof -http=0.0.0.0:<your-profile-port> <your profile data>
+例如,执行下述语句可以在 8088 端口开启 WEB UI 。
+go tool pprof -http=0.0.0.0:8088 ~/pprof/pprof.samples.cpu.001.pb.gz
+访问 http://0.0.0.0:8088/ui/flamegraph 即可得到火焰图。
Databend 暂时不支持在 musl 平台上运行 pprof 。
+内存分析,在应用程序进行堆分配时记录堆栈追踪,用于监视当前和历史内存使用情况,以及检查内存泄漏。
+通过与 jemalloc 的集成,Databend 得以整合多种内存分析能力。这里使用 jeprof 进行内存分析。
安装 Jemalloc,并启用其剖析能力 ./configure --enable-prof
在构建二进制文件时启用 memory-profiling 特性:cargo build --features memory-profiling
在创建 Databend 实例时,设置环境变量 MALLOC_CONF=prof:true 以启用内存分析。示例:
MALLOC_CONF=prof:true ./target/debug/databend-query
+jeprof <your-profile-target> http://localhost:<your-databend-port>/debug/mem
+下面的例子选用 debug 模式下编译的 databend-query 作为 target,端口为 8080,结果如下所示:
+$ jeprof ./target/debug/databend-query http://localhost:8080/debug/mem
+Using local file ./target/debug/databend-query.
+Gathering CPU profile from http://localhost:8080/debug/mem/pprof/profile?seconds=30 for 30 seconds to
+ ~/jeprof/databend-query.1658367127.localhost
+Be patient...
+Wrote profile to ~/jeprof/databend-query.1658367127.localhost
+Welcome to jeprof! For help, type 'help'.
+(jeprof) top
+Total: 11.1 MB
+ 6.0 54.6% 54.6% 6.0 54.6% ::alloc_zeroed
+ 5.0 45.4% 100.0% 5.0 45.4% ::alloc
+ 0.0 0.0% 100.0% 0.5 4.5% ::add_node::{closure#0}
+ 0.0 0.0% 100.0% 5.0 45.4% ::alloc_impl
+ 0.0 0.0% 100.0% 5.0 45.4% ::allocate
+ 0.0 0.0% 100.0% 4.5 40.8% ::allocate_in
+ 0.0 0.0% 100.0% 0.5 4.5% ::apply_batch_inner
+ 0.0 0.0% 100.0% 11.1 100.0% ::block_on::
+ 0.0 0.0% 100.0% 11.1 100.0% ::block_on::::{closure#0}
+ 0.0 0.0% 100.0% 0.5 4.5% ::clone
+(jeprof)
+常见的用例之一是查找内存泄漏,通过比较间隔前后的内存画像即可完成这一工作。
+在下面的命令行中,以 10s 为间隔,获取前后两个时间节点的内存画像。
+curl 'http://localhost:<your-databend-port>/debug/mem/pprof/profile?seconds=0' > a.prof
+sleep 10
+curl 'http://localhost:<your-databend-port>/debug/mem/pprof/profile?seconds=0' > b.prof
+接着,可以利用这两份内存画像来生成 pdf 格式的内存分配调用图。
jeprof \
+ --show_bytes \
+ --nodecount=1024 \
+ --nodefraction=0.001 \
+ --edgefraction=0.001 \
+ --maxdegree=64 \
+ --pdf \
+ <your-profile-target> \
+ --base=a.prof \
+ b.prof \
+ > mem.pdf
+同样选用 debug 模式下编译的 databend-query 作为 target,端口为 8080,结果如图所示:
+
目前无法在 Mac 上进行内存分析,不管是 x86_64 还是 aarch64 平台。
+ + + + + + + + +如果你对自定义类型系统或者数据库项目的研发感兴趣,可以看看 Databend 是如何做的。
+现在 Databend 正在尝试将一些旧的函数迁移到全新表达式框架中,你愿意来试试看吗?
+近期,Databend 围绕全新表达式框架的设计与实现开展了许多工作,将会带来一些有意思的特性。
+旧的函数位于 query/functions/src/scalars ,它们需要被迁移到 query/functions-v2/src/scalars/ 。
通常情况下,旧函数实现中的核心逻辑是可以复用的,只需要进行少量重写使其符合新的实现方案。
+类似地,旧的测试位于 query/functions/tests/it/scalars/ ,也应该迁移到 query/functions-v2/tests/it/scalars/ 。
新测试将会使用 goldenfile 进行编写,所以可以轻松生成测试用例而无需大量繁重的手写工作。
LENGTH 将会按字节数返回字符串的长度。
仅仅使用 6 行,就可以在 query/functions-v2/src/scalars/strings.rs 中实现 LENGTH 函数。
registry.register_1_arg::<StringType, NumberType<u64>, _, _>(
+ "length",
+ FunctionProperty::default(),
+ |_| None,
+ |val| val.len() as u64,
+);
+由于 OCTET_LENGTH 是 LENGTH 的同义函数,只需为其添加一个函数别名即可,仅用一行。
registry.register_aliases("length", &["octet_length"]);
+接下来,需要写一些测试,来确保函数实现的正确性。编辑 query/functions-v2/tests/it/scalars/string.rs。
fn test_octet_length(file: &mut impl Write) {
+ run_ast(file, "octet_length('latin')", &[]);
+ run_ast(file, "octet_length(NULL)", &[]);
+ run_ast(file, "length(a)", &[(
+ "a",
+ DataType::String,
+ build_string_column(&["latin", "кириллица", "кириллица and latin"]),
+ )]);
+}
+将其注册到 test_string 函数中:
#[test]
+fn test_string() {
+ let mut mint = Mint::new("tests/it/scalars/testdata");
+ let file = &mut mint.new_goldenfile("string.txt").unwrap();
+
+ ...
+ test_octet_length(file);
+ ...
+}
+通过命令行,可以直接生成完整的测试用例,并附加到对应的 goldenflie 中:
REGENERATE_GOLDENFILES=1 cargo test -p query-functions-v2 --test it
+请使用 git diff 检查一下生成的测试是否符合预期,如果一切顺利,LENGTH 函数的迁移工作就完成了。
function 中暴露了多套注册方法, 根据函数接受的参数个数不同, 分为: register_0_arg, register_1_arg ..
另外, 根据不同的功能需求, 我们提供了不同Level的注册API
+| Auto Vectorization | Access Output Column Builder | Auto Null Passthrough | Auto Combine Null | Auto Downcast | Throw Runtime Error | Varidic | Tuple | |
|---|---|---|---|---|---|---|---|---|
| register_n_arg | ✔️ | ❌ | ✔️ | ❌ | ✔️ | ❌ | ❌ | ❌ |
| register_passthrough_nullable_n_arg | ❌ | ✔️ | ✔️ | ❌ | ✔️ | ✔️ | ❌ | ❌ |
| register_combine_nullable_n_arg | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ | ❌ |
| register_n_arg_core | ❌ | ✔️ | ❌ | ❌ | ✔️ | ✔️ | ❌ | ❌ |
| register_function_factory | ❌ | ✔️ | ❌ | ❌ | ❌ | ✔️ | ✔️ | ✔️ |
Domain是函数的输入的值域经过函数转换后得出的值域, 一些函数计算是符合单调性等特性的, 利用这类特性我们轻量级计算出函数的值域,这对后续的Partition Prune 有很大帮助, 例如: 数据在底层是通过 timestamp 排序的, 在索引层我们会有timestamp列的 Min/Max 索引, 那么对于带 where to_date(timestamp) > '2020-01-01' 过滤条件的SQL查询, 根据索引数据可以利用 Domain 计算出 to_date(timestamp) 列的 Min/Max 索引,从而进入 Prune 逻辑。
i8 --> i16 --> i32 --> i64u32 --> i64, u64 ---> i64, 转型过程出现溢出会抛出错误i32 --> f64, u64 --> f64, 转型过程出现溢出会抛出错误null类型能转为nullable<T>类型, 如: null --> nullable<i32>T 类型能转为 nullable<T> 类型, 如: i32 --> nullable<i32>T 能转为 U 类型,则 nullable<T> 类型能转为 nullable<U> 类型, 则 Array<T> 类型能转为 Array<U> 类型由于数值类型较多,大部分情况下我们只需要定义 最大类型即可,如 asin 只需要定义 NumberType<f64> 类型的参数, 接收到其他类型的参数时会自动转型, 例如: asin(i32) 会自动转型为 asin(f64); 在少数性能敏感计算,我们会给较小范围的 数值参数定义额外函数重载, 如 plus, minus, 此时由于自动转换规则的存在,我们必须注意重载的函数必须定义在最大类型的函数之前, 因为函数的查找是按注册顺序进行查找, 只捕获符合条件的第一个函数。
所以: i32 优先 定义于 i64, u64 优先定义于 i64, i64 优先定义于 f64, null 优先定义于 nullable。
Databend 的绝大部分系统表都位于 query/storage 这个目录下,当然,如果因为一些特殊的构建原因无法放在这个位置的话,也可以考虑临时放到 service/databases/system 这个目录(不推荐)。
系统表的定义主要关注两个内容:一个是表的信息,会包含表名、Schema 这些;另一个就是表中数据的生成/获取。刚好可以对应到 SyncSystemTable 和 AsyncSystemTable 这两个 Trait 中的 get_table_info 和 get_full_data 。到底是同步还是异步,取决于在获取数据时,是否涉及到异步函数的调用。
本文将会以 credits 表的实现为例,介绍 Databend 系统表的实现,代码位于 https://github.com/datafuselabs/databend/blob/main/src/query/storages/system/src/credits_table.rs 。credits 会返回 Databend 所用到的上游依赖的信息,包括名字、版本和许可三个字段。
首先,需要参考其他系统表的实现,去定义表对应的结构,只需要保有表信息的字段就可以了。
+pub struct CreditsTable {
+ table_info: TableInfo,
+}
+接下来是为 CreditsTable 表实现 create 方法,对应的函数签名如下:
pub fn create(table_id: u64) -> Arc<dyn Table>
+传入的 table_id 会在创建表时由 sys_db_meta.next_table_id() 生成。
schema 用于描述表的结构,需要使用 TableSchemaRefExt 和 TableField 来创建,字段名字和类型取决于表中的数据。
let schema = TableSchemaRefExt::create(vec![
+ TableField::new("name", TableDataType::String),
+ TableField::new("version", TableDataType::String),
+ TableField::new("license", TableDataType::String),
+]);
+对于字符串类数据,可以使用 TableDataType::String ,其他基础类型也类似。但如果你需要允许字段中存在空值,比如字段是可以为空的 64 位无符号整数,则可以使用 TableDataType::Nullable(Box::new(TableDataType::Number(NumberDataType::UInt64))) 的方式,TableDataType::Nullable 表示允许空值,TableDataType::Number(NumberDataType::UInt64) 表征类型是 64 位无符号整数。
接下来就是定义表的信息,基本上只需要依葫芦画瓢,把描述、表名、元数据填上就好。
+let table_info = TableInfo {
+ desc: "'system'.'credits'".to_string(),
+ name: "credits".to_string(),
+ ident: TableIdent::new(table_id, 0),
+ meta: TableMeta {
+ schema,
+ engine: "SystemCredits".to_string(),
+ ..Default::default()
+ },
+ ..Default::default()
+};
+
+SyncOneBlockSystemTable::create(CreditsTable { table_info })
+对于同步类型的表往往使用 SyncOneBlockSystemTable 创建,异步类型的则使用 AsyncOneBlockSystemTable 。
接下来,则是实现 SyncSystemTable ,SyncSystemTable 除了需要定义 NAME 之外,还需要实现 4 个函数 get_table_info 、get_full_data、get_partitions 和 truncate ,由于后两个有默认实现,大多数时候不需要考虑实现自己的。(AsyncSystemTable 类似,只是没有 truncate )
NAME 的值遵循 system.<name> 的格式。
const NAME: &'static str = "system.credits";
+get_table_info 只需要返回结构体中的表信息。
fn get_table_info(&self) -> &TableInfo {
+ &self.table_info
+}
+get_full_data 是相对重要的部分,因为每个表的逻辑都不太一样,credits 的三个字段基本类似,就只举 license 字段为例。
let licenses: Vec<Vec<u8>> = env!("DATABEND_CREDITS_LICENSES")
+ .split_terminator(',')
+ .map(|x| x.trim().as_bytes().to_vec())
+ .collect();
+license 字段的信息是从名为 DATABEND_CREDITS_LICENSES 的环境变量(参见 common-building)获取的,每条数据都用 , 进行分隔。
字符串类型的列最后是从 Vec<Vec<u8>> 转化过来,其中字符串需要转化为 Vec<u8> ,所以在迭代的时候使用 .as_bytes().to_vec() 做了处理。
在获取所有数据后,就可以按 DataBlock 的形式返回表中的数据。非空类型,使用 from_data ,可空类型使用 from_opt_data 。
Ok(DataBlock::new_from_columns(vec![
+ StringType::from_data(names),
+ StringType::from_data(versions),
+ StringType::from_data(licenses),
+]))
+最后,要想将其集成到 Databend 中,还需要编辑 src/query/service/src/databases/system/system_database.rs,将其注册到 SystemDatabase 中 。
impl SystemDatabase {
+ pub fn create(sys_db_meta: &mut InMemoryMetas, config: &Config) -> Self {
+ ...
+ CreditsTable::create(sys_db_meta.next_table_id()),
+ ...
+ }
+}
+系统表的相关测试目前仍然位于 src/query/service/tests/it/storages/system.rs 。
对于内容不会经常动态变化的表,可以使用 Golden File 测试,其运行逻辑是将对应的表写入指定的文件中,然后对比每次测试时文件内容是否发生变化。
+#[tokio::test(flavor = "multi_thread")]
+async fn test_columns_table() -> Result<()> {
+ let (_guard, ctx) = crate::tests::create_query_context().await?;
+
+ let mut mint = Mint::new("tests/it/storages/testdata");
+ let file = &mut mint.new_goldenfile("columns_table.txt").unwrap();
+ let table = ColumnsTable::create(1);
+
+ run_table_tests(file, ctx, table).await?;
+ Ok(())
+}
+对于内容可能会变化的表,目前缺乏充分的测试手段。可以选择测试其中模式相对固定的部分,比如行和列的数目;也可以验证输出中是否包含特定的内容。
+
+#[tokio::test(flavor = "multi_thread")]
+async fn test_metrics_table() -> Result<()> {
+ ...
+ let result = stream.try_collect::<Vec<_>>().await?;
+ let block = &result[0];
+ assert_eq!(block.num_columns(), 4);
+ assert!(block.num_rows() >= 1);
+
+ let output = pretty_format_blocks(result.as_slice())?;
+ assert!(output.contains("test_test_metrics_table_count"));
+ #[cfg(feature = "enable_histogram")]
+ assert!(output.contains("test_test_metrics_table_histogram"));
+
+ Ok(())
+}
+目前 Databend 采用 nightly 发布模式,每天夜里都会打包二进制文件,并递增 patch 版本。
+目前主要关注的 targets 包括:
+为方便体验,release 中除了 meta 和 query 的二进制文件之外,还包含一份默认配置和用于快速启动的脚本。
+✦ ❯ tree .
+.
+├── bin
+│ ├── databend-meta
+│ ├── databend-metabench
+│ ├── databend-metactl
+│ └── databend-query
+├── configs
+│ ├── databend-meta.toml
+│ └── databend-query.toml
+├── readme.txt
+└── scripts
+ ├── start.sh
+ └── stop.sh
+
+3 directories, 11 files
+readme.txt 中包含一些必要的提示信息,只需执行 ./scripts/start.sh 即可快速启动 databend 。
尽管采用 nightly 发布模式,但 Databend 并非野蛮生长。除了年度路线图外,Databend 还会按开发阶段发布版本路线图,这也决定了当前 minor 版本的分配。
+日常维护工作虽然简单,但却是保证项目活力和竞争力的有效手段。本文将会介绍 Databend 是如何与最新的工具链/依赖关系协同的。
+Databend 的日常维护工作主要分为两大类:一类是工具链更新,另一类则是依赖关系更新。
+工具链更新会随着 Rust 版本更新进行。在新的 stable 版本发布后,Databend 就会升级到对应日期附近的 nightly 工具链。
+更新工具链的必要步骤是编辑 scripts/setup/rust-toolchain.toml 的 channel 字段,并提交 Pull Request 。PR 合并后,会构建新的 build-tool 镜像,以确保 Databend 的 CI workflow 可以正常运行。
在镜像构建完成后,还需要完成以下工作:
+rust-toolchain.toml,确保它和 scripts/setup/rust-toolchain.toml 一致。scripts/setup/run_build_tool.sh make lint,确保 clippy 无警告。
+#[allow(clippy::xxx)] 来跳过部分 clippy 规则。scripts/setup/run_build_tool.sh make test,确保测试通过。依赖关系更新以大约 30 天一次的频率进行,需要在应用上游最新成果和维持项目稳定构建之间进行权衡。
+当前 Databend 有数以千计的第三方依赖,除了 crates.io 上的依赖外,还有部分源自 github 上的某次提交或者是分叉的上游项目。
+这里列出一套相对普适的更新步骤:
+cargo upgrade --workspace 以更新来源为 crates.io 的依赖。
+upgrade 子命令依赖 cargo-edit,在使用前需要安装。rev 。
+version 或 branch 字段,这不利于后续更新维护。make lint 和 make test,以确保更新顺利进行。
+cargo upgrade --workspace 无法更新依赖,可以尝试先执行一遍 cargo update 。Cargo.lock 做一些手脚,请确保一切检查都可以顺利通过,并在 PR 中进行解释。全链路追踪意味着能够追踪到每一个调用请求的完整调用链路、收集性能数据并反馈异常。Databend 使用 tracing 赋能可观测性,实现全链路追踪。
+初步了解 Databend 怎么实现全链路追踪。
+
Tracing 是由 Tokio 团队维护的 Rust 应用追踪框架,用来收集结构化的、基于事件的诊断信息。
+项目地址:https://github.com/tokio-rs/tracing
+示例:
+use tracing::{info, Level};
+use tracing_subscriber;
+
+fn main() {
+ let collector = tracing_subscriber::fmt()
+ // filter spans/events with level TRACE or higher.
+ .with_max_level(Level::TRACE)
+ // build but do not install the subscriber.
+ .finish();
+
+ tracing::collect::with_default(collector, || {
+ info!("This will be logged to stdout");
+ });
+ info!("This will _not_ be logged to stdout");
+}
+Databend 的 tracing-subscriber 被统一整合在 common/tracing,由 query 和 meta 共用。
// Use env RUST_LOG to initialize log if present.
+// Otherwise use the specified level.
+let directives = env::var(EnvFilter::DEFAULT_ENV).unwrap_or_else(|_x| level.to_string());
+let env_filter = EnvFilter::new(directives);
+let subscriber = Registry::default()
+ .with(env_filter) # 根据环境变量过滤
+ .with(JsonStorageLayer) # 利用 tracing-bunyan-formatter 格式化为 json
+ .with(stdout_logging_layer) # 标准输出
+ .with(file_logging_layer) # 输出到文件,默认位于 `_logs` 目录下
+ .with(jaeger_layer); # opentelemetry-jaeger
+
+#[cfg(feature = "console")]
+let subscriber = subscriber.with(console_subscriber::spawn()); # tokio console
+
+tracing::subscriber::set_global_default(subscriber)
+ .expect("error setting global tracing subscriber");
+具体到内部的 tracing 记录,大致有两类:
普通:与其他 log 方式一样,利用 info!、debug! 来收集信息。
use common_tracing::tracing;
+
+tracing::info!("{:?}", conf);
+tracing::info!("DatabendQuery {}", *databend_query::DATABEND_COMMIT_VERSION);
+Instruments:在调用函数时创建并进入 tracing span(跨度),span 表示程序在特定上下文中执行的时间段。
+use common_tracing::tracing::debug_span;
+#[tracing::instrument(level = "debug", skip_all)]
+async fn read(&mut self) -> Result<Option<DataBlock>> {
+ ...
+ fetched_metadata = read_metadata_async(&mut self.reader)
+ .instrument(debug_span!("parquet_source_read_meta"))
+ .await
+ .map_err(|e| ErrorCode::ParquetError(e.to_string()))?;
+ ...
+}
+示例:
+{
+ "v": 0,
+ "name": "databend-query-test_cluster@0.0.0.0:3307",
+ "msg": "Shutdown server.",
+ "level": 30,
+ "hostname": "dataslime",
+ "pid": 53341,
+ "time": "2022-05-11T00:51:56.374807359Z",
+ "target": "databend_query",
+ "line": 153,
+ "file": "query/src/bin/databend-query.rs"
+}
+Databend 原生提供了多种观测方式,以方便诊断和调试:
+_logs 目录(根据配置)。select * from system.tracing limit 20; 。使用 Jaeger 对 Databend 进行全链路追踪。
+OpenTelemetry 是工具、API 和 SDK 的集合。使用它来检测、生成、收集和导出遥测数据(度量、日志和追踪),以帮助您分析软件的性能和行为。
+Jaeger 是一个开源的端到端分布式追踪系统。由 Uber 捐赠给 CNCF 。它可以用于监视基于微服务的分布式系统,提供以下能力:
+
遵循下述步骤,即可使用 Jaeger 探索 Databend :
+cargo build(可以使用 --bin 指定)。DEBUG ,接着运行需要调试的应用程式。例如,DATABEND_JAEGER_AGENT_ENDPOINT=localhost:6831 LOG_LEVEL=DEBUG ./databend-query 。docker run -d -p6831:6831/udp -p6832:6832/udp -p16686:16686 jaegertracing/all-in- one:latest 。http://127.0.0.1:16686/ 以查看 jaeger 收集的信息。注意 只有正确配置 DATABEND_JAEGER_AGENT_ENDPOINT 才能启用 Jaeger 支持。
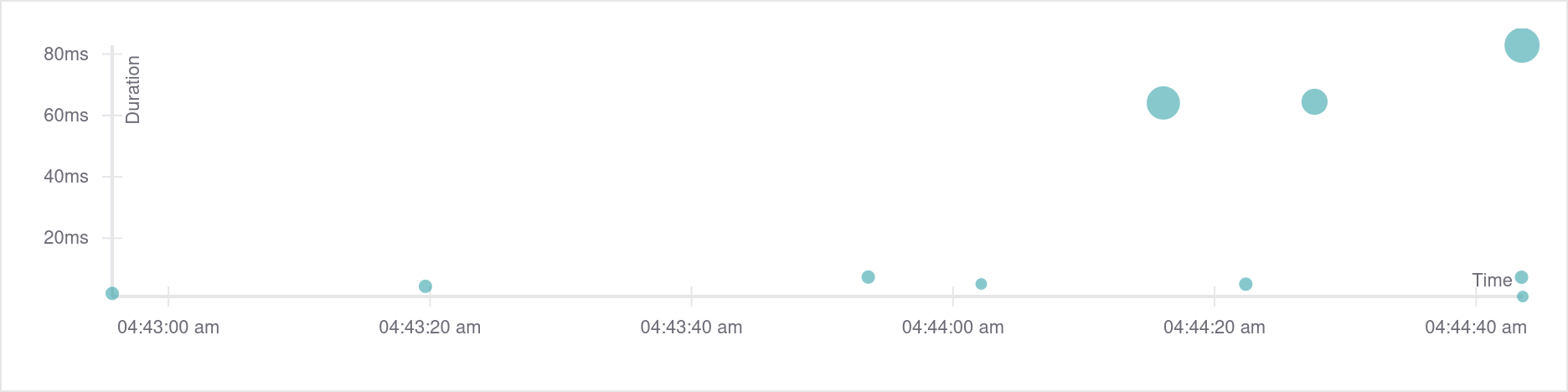
x 轴是执行时刻,y 轴是持续的时间,圆点反映 span 的聚集程度。
+执行下述语句即可得到上图所示追踪结果:
+CREATE TABLE t1(a INT);
+INSERT INTO t1 VALUES(1);
+INSERT INTO t1 SELECT * FROM t1;
+Timeline
+下图是点击最大的圆点得到的追踪情况:
+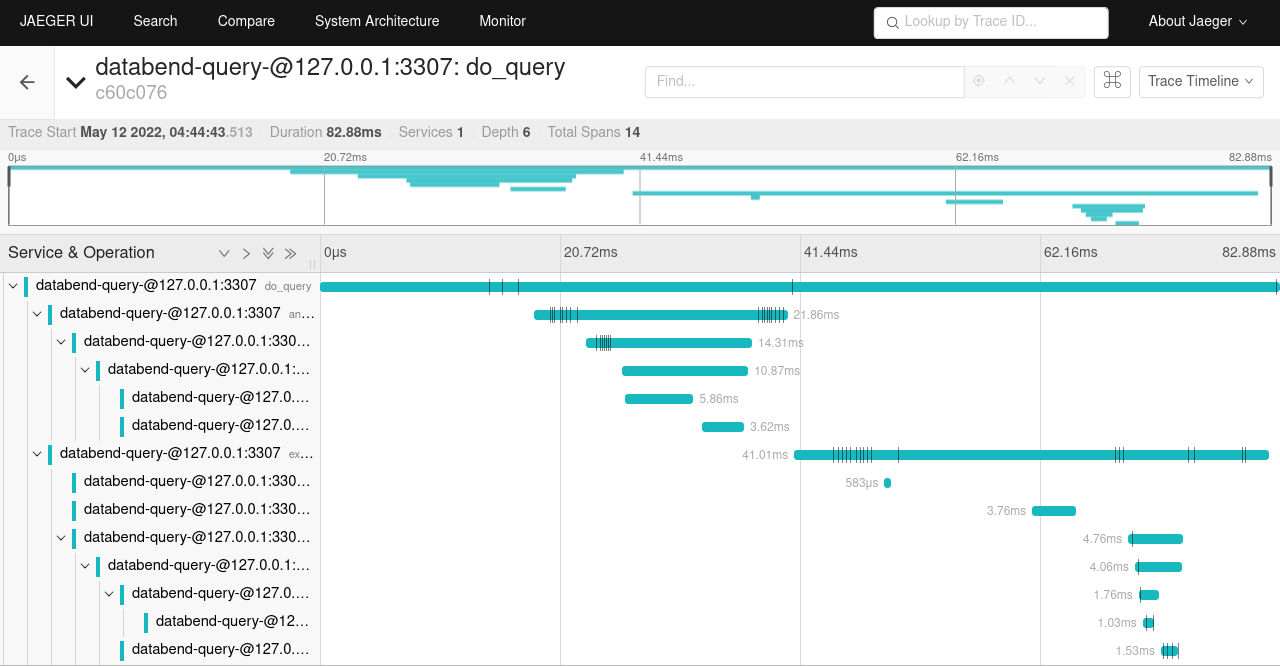
使用 timeline 模式来展现 tracing 的各个跨度之间的关系。以时间为主线进行分析,方便使用者观看在某个时间点观看程序信息。
+点开第一个跨度,可以看到这是执行 INSERT INTO t1 SELECT *FROM t1 查询时的情况。
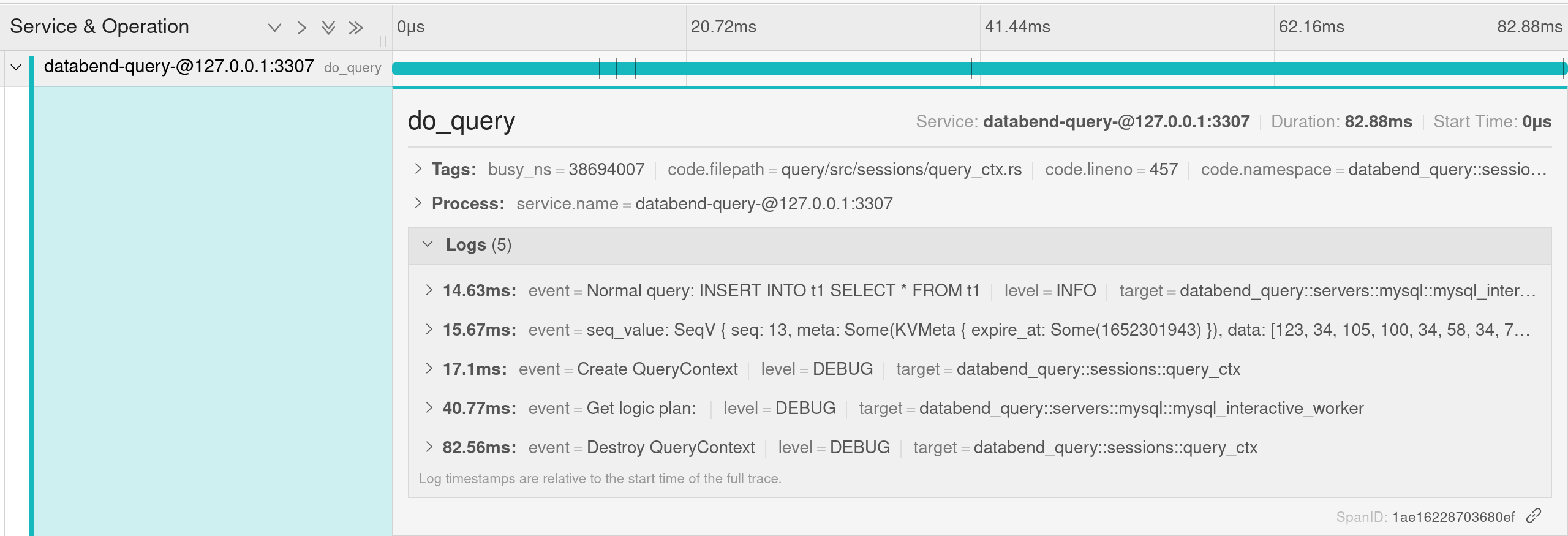
Graph
+切换到 graph 模式,可以看到各个 span 之间的调用链,每个 span 具体用时 ,以及百分比。
+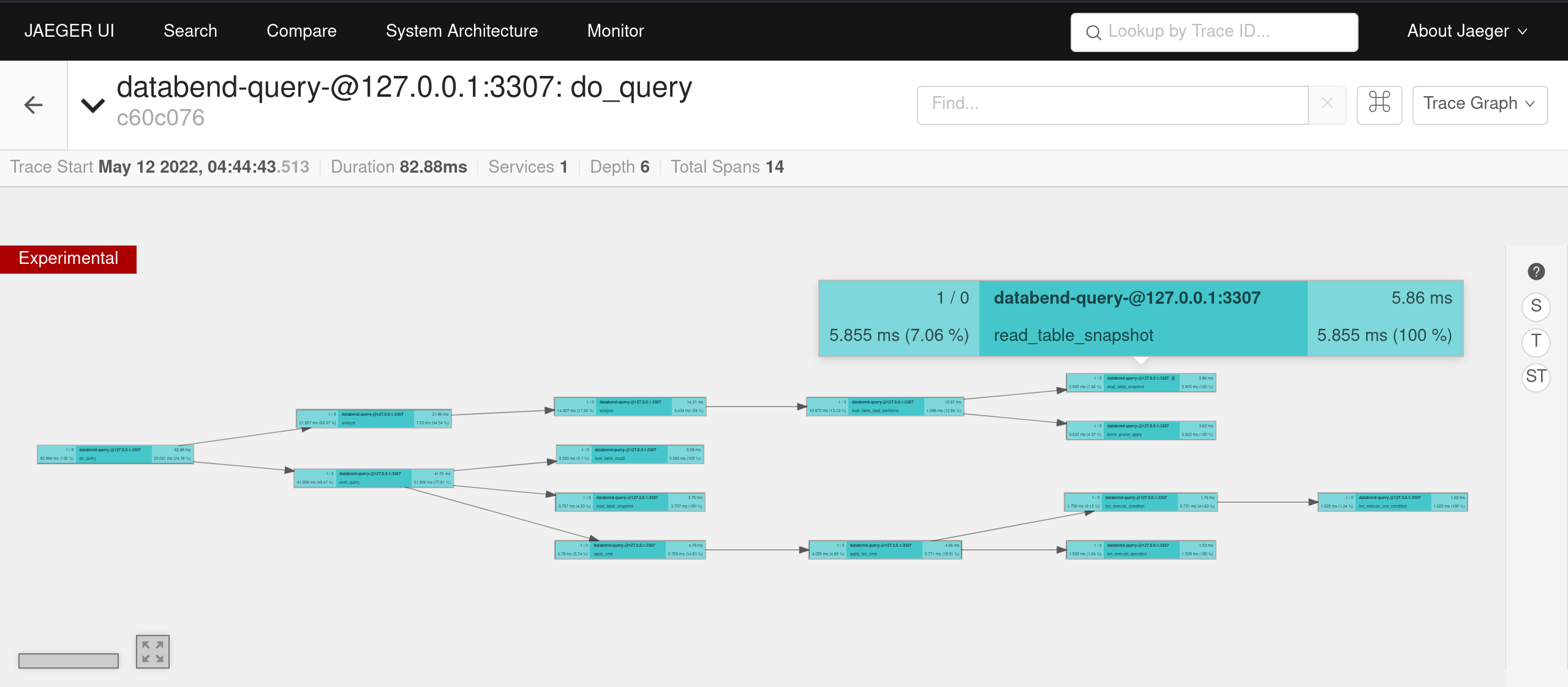
通过这个视图使用者很容易知道系统瓶颈,快速定位问题。
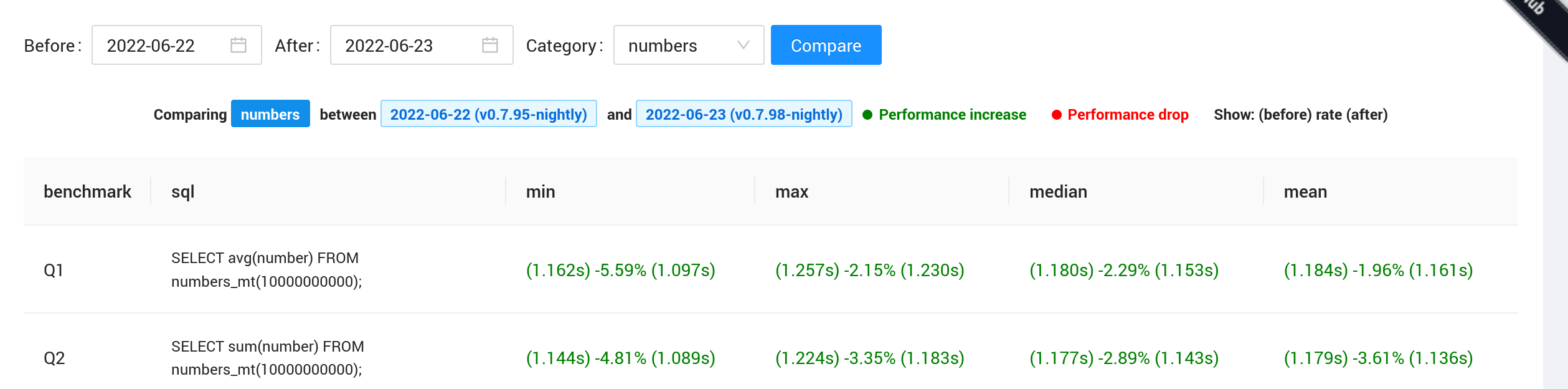
+Compare
+连起来的各个部分形成整个 trace 的调用链。因为比较时一般会比较两个相同类型的调用,所以看到的会是重合后的视图。
+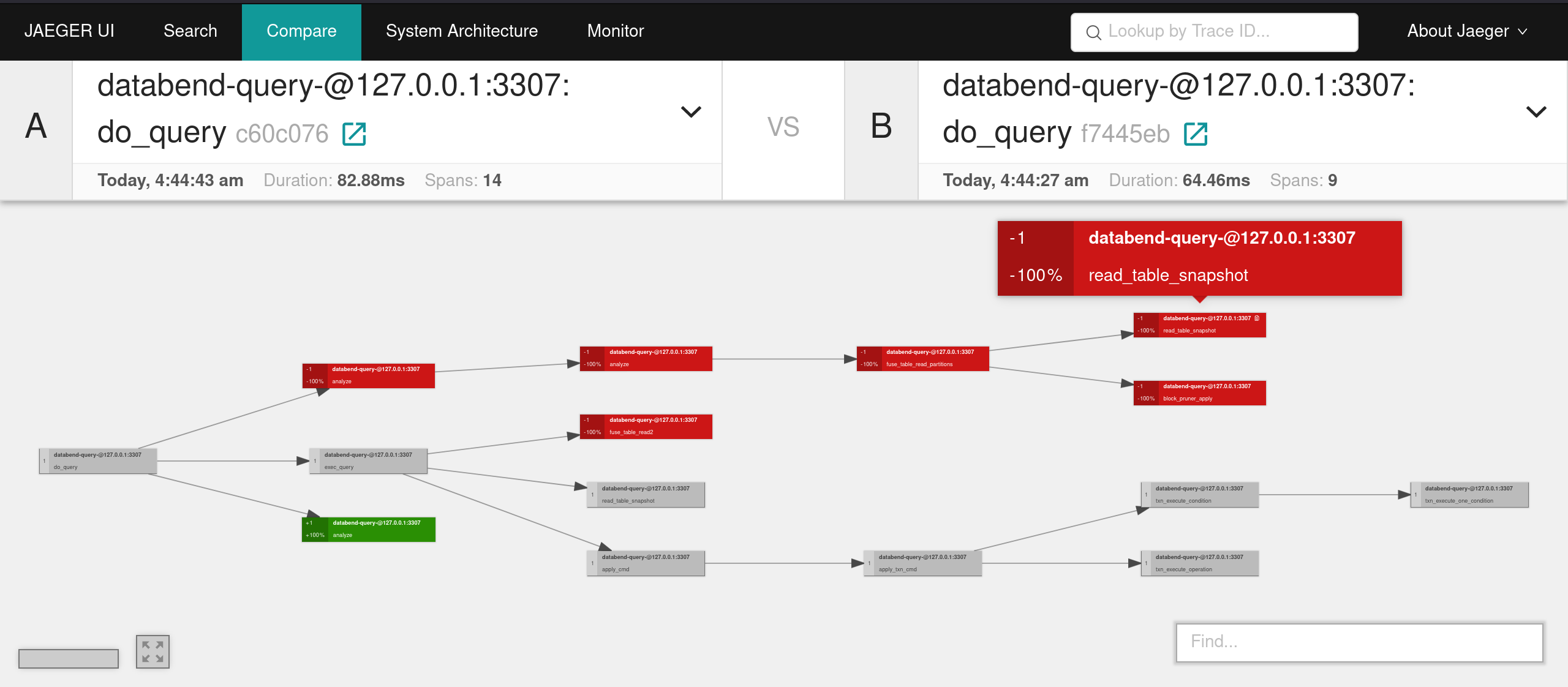
对于颜色的一个说明:
+tokio-rs 团队出品的诊断和调试工具,可以帮助我们诊断与 tokio 运行时相关的问题。
+
tokio-console 是专为异步程序设计的调试与诊断工具,能够列出 tokio 的任务,提供对程序的任务和资源的实时、易于导航的视图,总结了它们的当前状态和历史行为。主要包含以下组件:
+项目地址:https://github.com/tokio-rs/console
+rustflags 和 features 来构建:
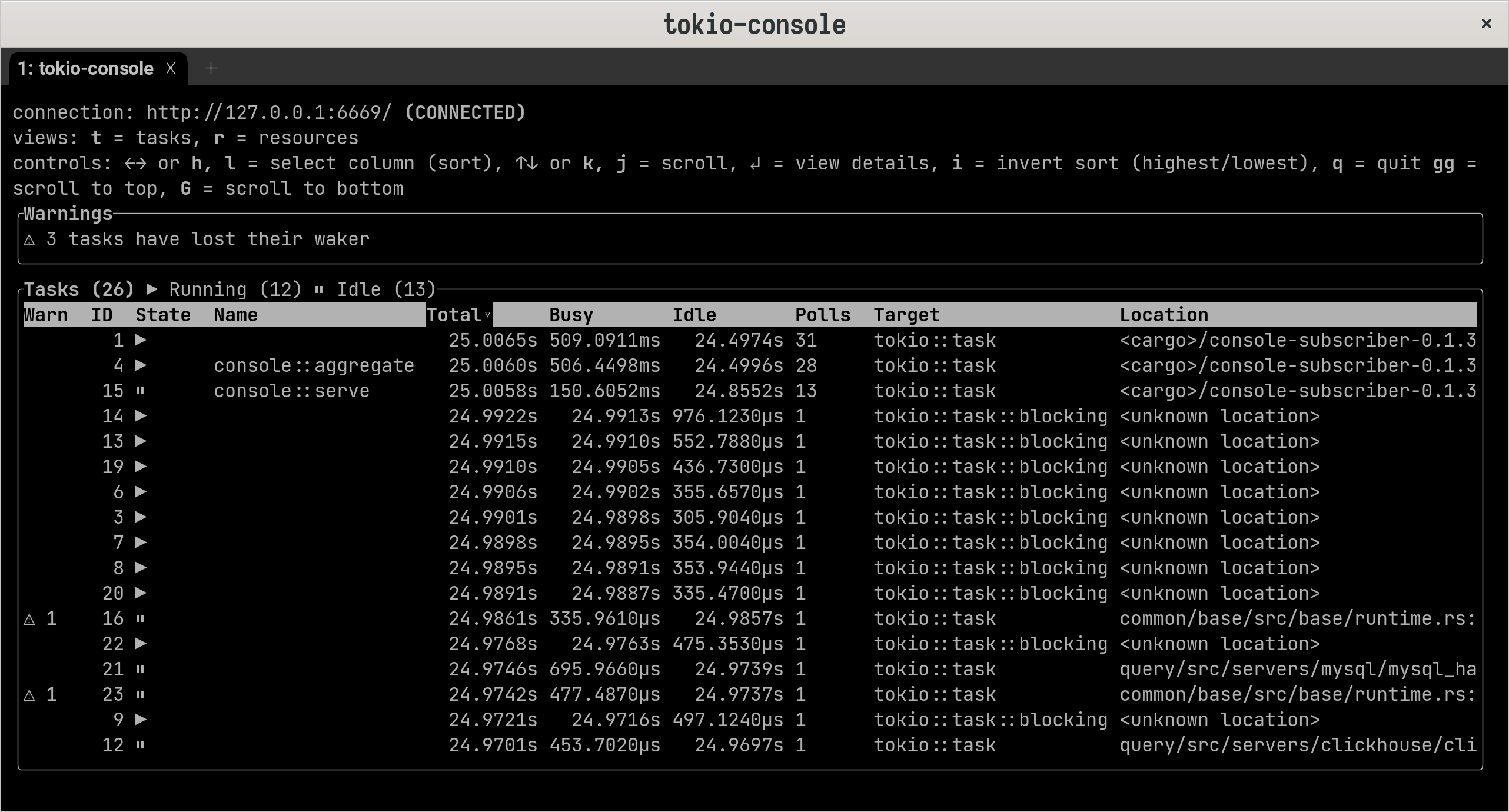
+RUSTFLAGS="--cfg tokio_unstable" cargo build --features tokio-console ,也可以只构建单个二进制程式,使用 --bin 进行指定。TRACE ,运行需要调试的应用程式 LOG_LEVEL=TRACE databend-query 或者 databend-meta --single --log-level=TRACE。可以使用 TOKIO_CONSOLE_BIND 指定端口,以避免潜在的端口抢占问题。tokio-console,默认连接到 http://127.0.0.1:6669 。任务
+先看什么是 tokio 任务:
+
基础视图
+通过左右切换,可以得到总忙时间或轮询次数等指标对任务进行排序。控制台通过高亮来提示较大差异,比如从毫秒到秒的切换。
+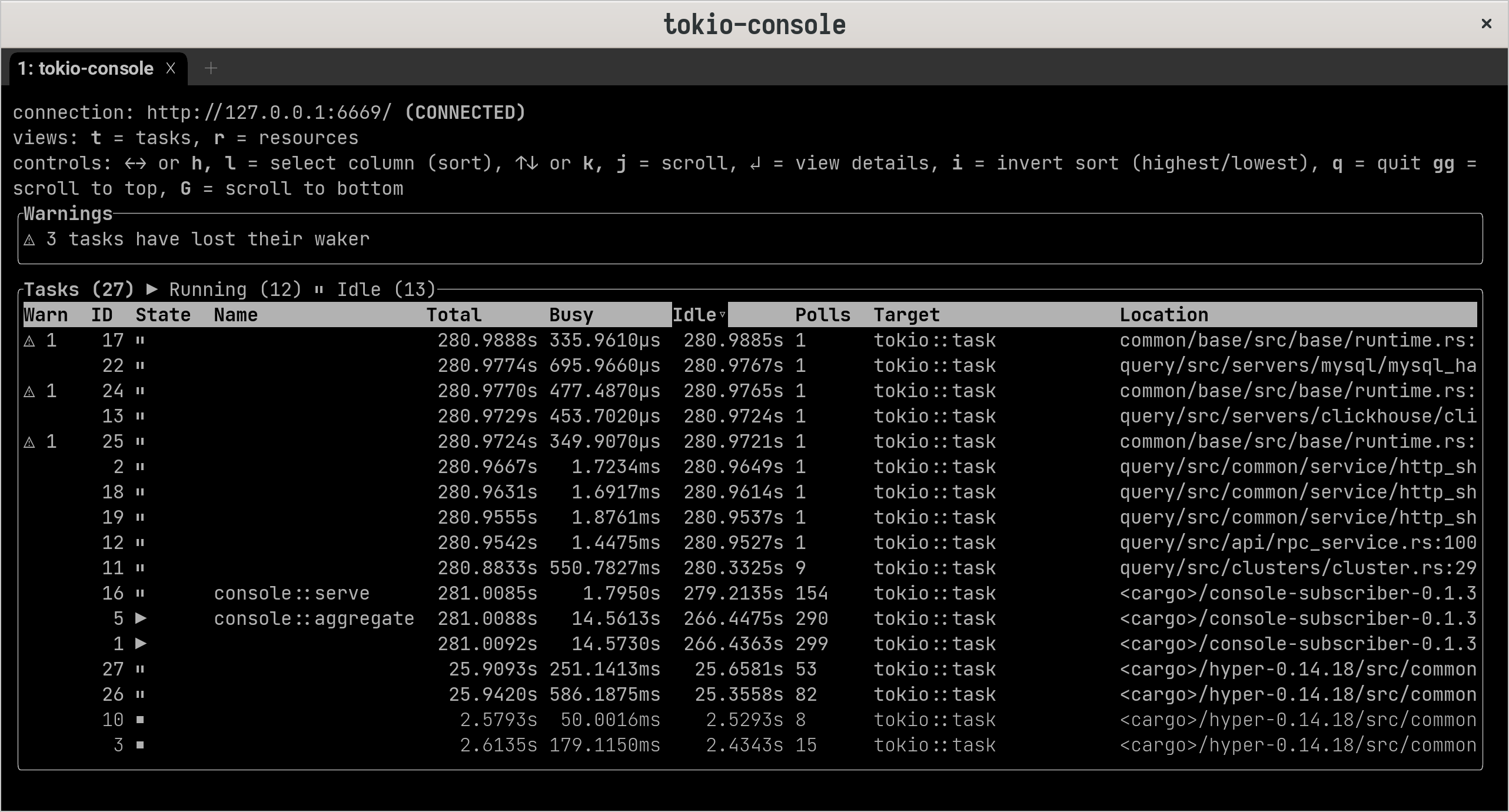
控制台还实现了一个“警告”系统。通过监视应用程序中任务的运行时操作,控制台可以检测可能提示 bug 或性能问题的行为模式,并突出显示这些行为模式供用户分析。比如已经运行了很长时间而没有让步的任务,唤醒的次数比被其他任务唤醒的次数还要多的任务。
+任务视图
+上下切换选中任务,enter 查看关于每个任务的翔实数据,比如轮询持续时间的直方图。
+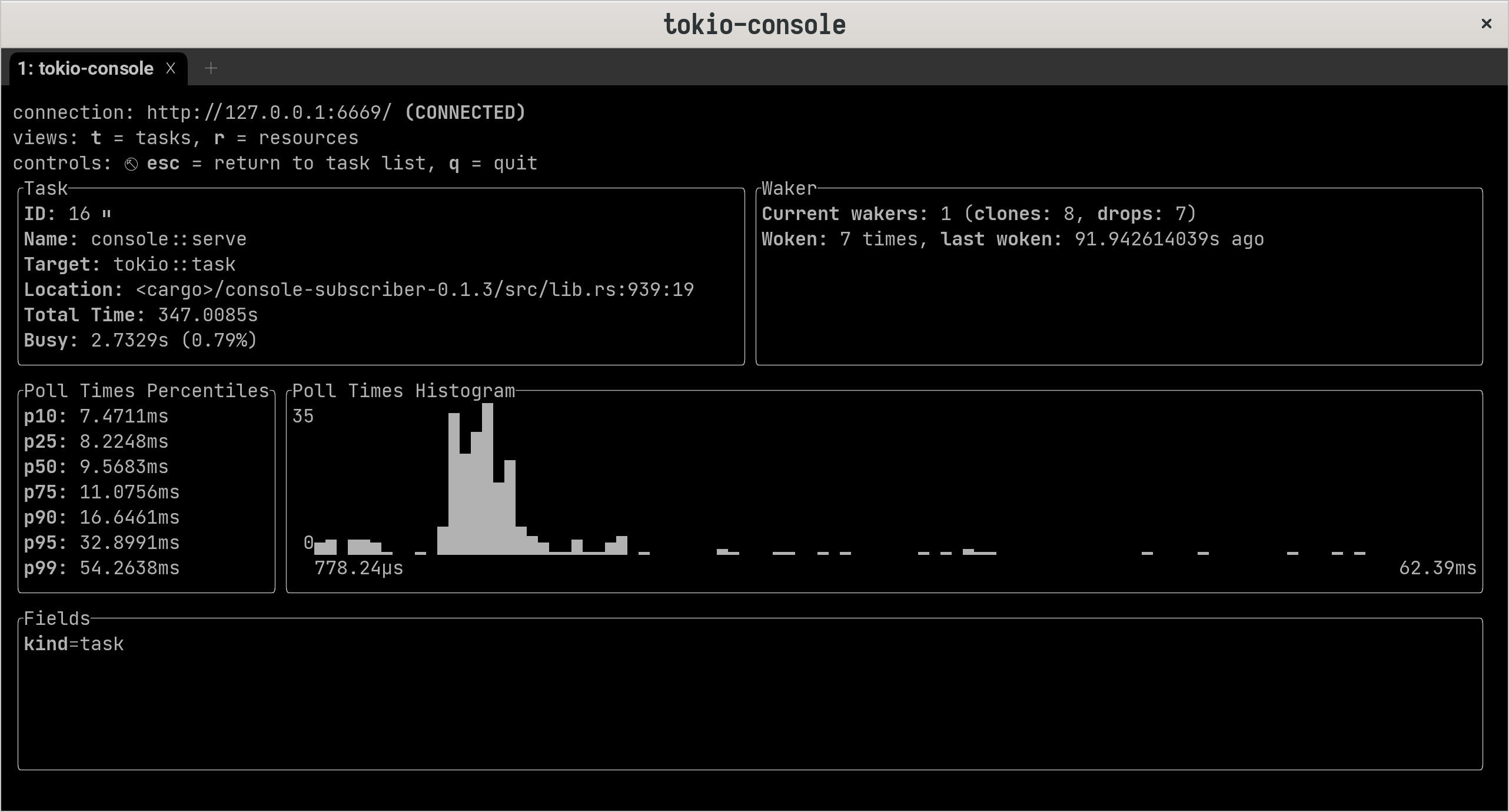
不仅列出任务。console 还会插入异步互斥和信号量等资源。Tokio Console 的资源详细信息视图显示了哪些任务已经进入临界区,哪些任务正在等待获得访问权限。
+与分布式追踪和日志系统相关的一些其他内容。
+目前还有一系列关于可观测性和 Tracing 的 Issue 有待解决:
+另外,更进一步的考量是,如何基于可观测性来自动/半自动地发现问题并对系统进行调优。
+Tracing
+Jaeger
+tokio-console
+测试是提高软件健壮性、加速迭代进程的不二法宝。本文将会介绍如何为 Databend 添加不同种类的测试。
+++在「产品力:Databend 的质量保障」一文中,已经介绍到组成 Databend 测试的两个重要部分 —— 单元测试和功能测试。如有遗忘,不妨回顾一下。
+
Databend 的单元测试组织形式有别于一般的 Rust 项目,是直接一股脑放在 tests/it 目录下的。同时,在各个 crate 的 Cargo.toml 中,也针对性地禁用了 doctest 和 bin/lib test 。
优点
+src),只需要编译对应的 it(test) ,节省时间。缺点
+tests/it 会把需要测试的 crate 当作一个外部对象,所有待测试的内容都需要被设定为 pub 。不利于软件设计上的分层,整个项目结构会迅速的被破坏,需要引入编码规范并更加依赖开发者的主动维护。可以简单地将单元测试分为两类,一类是不需要外部文件介入的纯 Rust 测试,一类是 Golden Files 测试。
+Rust 测试
+与平时编写 Rust 单元测试相同,只是待测试的内容需要设为 pub ,且引用待测试 crate 需要使用该 crate 的名字。
Databend 提供一些用于模拟全局状态的函数,如 create_query_context 等,可能会有助于编写测试。
#[tokio::test(flavor = "multi_thread", worker_threads = 1)]
+async fn test_credits_table() -> Result<()> {
+ let ctx = crate::tests::create_query_context().await?;
+
+ let table = CreditsTable::create(1);
+ let source_plan = table.read_plan(ctx.clone(), None).await?;
+
+ let stream = table.read(ctx, &source_plan).await?;
+ let result = stream.try_collect::<Vec<_>>().await?;
+ let block = &result[0];
+ assert_eq!(block.num_columns(), 3);
+ Ok(())
+}
+上面示例来自 credits_table 的测试,先构建 read_plan 读取新建的 CreditsTable 表,再对列数进行断言。
Golden Files 测试
+++Golden File Testing are like unit tests, except the expected output is stored in a separate file. -- Max Grigorev at ZuriHac
+
Golden Files 测试是一种常用的测试手段,相当于是一类快照测试,如果执行情况和预期结果存在差异则认为测试失败。
+Databend 使用 goldenfile 这个 crate 来编写 Golden Files 测试。目前 Databend 有计划用此替代 assert_blocks 系列断言。
#[test]
+fn test_expr_error() {
+ let mut mint = Mint::new("tests/it/testdata");
+ let mut file = mint.new_goldenfile("expr-error.txt").unwrap();
+
+ let cases = &[
+ r#"5 * (a and ) 1"#,
+ r#"a + +"#,
+ r#"CAST(col1 AS foo)"#,
+ r#"1 a"#,
+ r#"CAST(col1)"#,
+ r#"G.E.B IS NOT NULL AND
+ col1 NOT BETWEEN col2 AND
+ AND 1 + col3 DIV sum(col4)"#,
+ ];
+
+ for case in cases {
+ run_parser!(file, expr, case);
+ }
+}
+编写 Golden Files 测试时需要指定挂载的目录和对应预期结果的文件。
+在执行测试的主体部分(如上面示例中的 run_parser! 宏),除了封装运行测试的必要逻辑外,还需要定义输出时的格式。
测试文件必须按指定格式编写。或者,使用 REGENERATE_GOLDENFILES=1 生成。
下面 Golden File 的例子节选自 common/ast 模块测试的 testdata/expr-error.txt,Output 对应解析 5 * (a and ) 1 的预期结果。
---------- Input ----------
+5 * (a and ) 1
+---------- Output ---------
+error:
+ --> SQL:1:12
+ |
+1 | 5 * (a and ) 1
+ | - ^ expected more tokens for expression
+ | |
+ | while parsing expression
+单元测试的运行可以运行 make unit-test 或者是 cargo test --workspace 。
二者的区别在于 make unit-test 封装了 ulimit 命令控制最大文件数和栈的大小以确保测试能够顺利运行,如果使用 MacOS 则更建议使用 make unit-test 。
通过过滤机制,可以轻松指定运行名字中具有特定内容的测试,例如 cargo test test_expr_error 。
Rust 测试
+同其他项目中的 Rust 测试一样,可以根据友好的错误提示轻松定位出现故障的测试。如果需要详细的 Backtrace ,可以在运行测试命令时添加环境变量 RUST_BACKTRACE=1 。
failures:
+
+---- buffer::buffer_read_number_ext::test_read_number_ext stdout ----
+Error: Code: 1046, displayText = Cannot parse value:[] to number type, cause: lexical parse error: 'the string to parse was empty' at index 0.
+
+<Backtrace disabled by default. Please use RUST_BACKTRACE=1 to enable>
+thread 'buffer::buffer_read_number_ext::test_read_number_ext' panicked at 'assertion failed: `(left == right)`
+ left: `1`,
+ right: `0`: the test returned a termination value with a non-zero status code (1) which indicates a failure', /rustc/cd282d7f75da9080fda0f1740a729516e7fbec68/library/test/src/lib.rs:185:5
+note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
+Golden Files 测试
+Golden Files 测试的执行命令与 Rust 测试相同,但在错误提示方面有所差异。得益于 goldenfiles 引入了 similar-assert ,可以轻松识别 diff :
Differences (-left|+right):
+ ---------- Output ---------
+ 'I'm who I'm.'
+ ---------- AST ------------
+ Literal {
+ span: [
+- QuotedString(0..18),
++ QuotedString(0..16),
+ ],
+ lit: String(
+ "I'm who I'm.",
+ ),
+ }
+.cargo/git/checkouts/rust-goldenfile-6352648ef139d984/16c5783/src/differs.rs:15:5
+note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
+上面示例中,+ 对应测试实际结果,- 对应测试预期结果,其他为相关的上下文。
goldenfiles 的报错可能会涉及多个测试文件,受限于长文本支持和空格显示,排查仍可能存在不便。
+这里提供一个相对友好的排查思路:
+REGENERATE_GOLDENFILES=1 cargo test -p <package> --test it 重新生成对应的测试。git diff 来显示前后 goldenfiles 文件的差异。功能测试主要由 SQL 逻辑测试(sqllogictest)和 stateful 测试两个部分组成。
+从本质上讲,这两类功能测试流程相同:
+在设计上,SQL 逻辑测试可以提供更全面的能力:
+SQL 逻辑测试
+SQL 逻辑测试放在 tests/logictest 目录下。
语句规范在 sqlite sqllogictest 的基础上进行拓展,可以分成以下几类:
+statement ok :SQL 语句正确,且成功执行。statement error <error regex> :SQL 语句输出期望的错误。statement query <desired_query_schema_type> <options> <labels> :SQL语句成功执行并输出预期结果。statement query B label(mysql,http)
+select count(1) > 1 from information_schema.columns;
+
+---- mysql
+1
+
+---- http
+true
+上面的例子展示了如何对 mysql 和 http 分别设计对应的输出结果。其中 B 表示结果为布尔类型,label 用来标记协议。
SQL 逻辑测试同样支持测试集生成 python3 gen_suites.py 。
stateful 测试
+stateful 测试放在 tests/suites 目录下:
++这里展示的是一类 stateless 写法,stateful 与之类似,区别在于 stateful 会加载数据集并执行查询。
+
输入是一系列 sql 语句,对应目录中的 *.sql 文件。
SELECT '==Array(Int32)==';
+
+CREATE TABLE IF NOT EXISTS t2(id Int null, arr Array(Int32) null) Engine = Fuse;
+
+INSERT INTO t2 VALUES(1, [1,2,3]);
+INSERT INTO t2 VALUES(2, [1,2,4]);
+INSERT INTO t2 VALUES(3, [3,4,5]);
+SELECT max(arr), min(arr) FROM t2;
+SELECT arg_max(id, arr), arg_min(id, arr) FROM (SELECT id, arr FROM t2);
+输出对应查询结果(含报错),如果没有输出则需要置空,对应目录中的 *.result 文件。
==Array(Int32)==
+[3, 4, 5] [1, 2, 3]
+3 1
+测试可以覆盖 SQL 执行过程中遇到预期错误的情况,有两种方式:
+沿用上面的方法,在 result 文件中标注具体报错信息。
也可以采用 ErrorCode 注释的方式,此时无需在 result 文件中添加对应内容。
SELECT INET_ATON('hello');-- {ErrorCode 1060}
+++由于 stateful 测试和 sqllogictest 测试均由 Python 编写,在运行前请确保你已经安装全部的依赖。
+
这几类测试都有对应的 make 命令,并支持集群模式测试:
sqllogictest 测试:make sqllogic-test & make sqllogic-cluster-test 。stateful 测试:make stateful-test & make stateful-cluster-test 。(一般在 CI 中运行,本地需要正确配置 MINIO 环境)。sqllogictest 测试
+sqllogictest 测试能提供精准到语句的报错,并提供更多有效的上下文帮助排查问题。
+AssertionError: Expected:
+INFORMATION_SCHEMA
+default
+ Actual:
+ INFORMATION_SCHEMA
+ db_12_0003
+ default
+ Statement:
+Parsed Statement
+ at_line: 77,
+ s_type: Statement: query, type: T, query_type: T, retry: False,
+ suite_name: gen/02_function/02_0005_function_compare,
+ text:
+ select * from system.databases where name not like '%sys%' order by name;
+ results: [(<re.Match object; span=(0, 4), match='----'>, 83, 'INFORMATION_SCHEMA\ndefault')],
+ runs_on: {'mysql', 'clickhouse', 'http'},
+ Start Line: 83, Result Label:
+make: *** [Makefile:82: sqllogic-test] Error 1
+stateful 测试
+目前 stateful 测试能够提供文件级的报错和 diff ,但无法确定报错是由哪一条语句产生。
+++这里展示的是过去 stateless 引发的报错,stateful 与之类似。
+
02_0057_function_nullif: [ FAIL ] - result differs with:
+--- /projects/datafuselabs/databend/tests/suites/0_stateless/02_function/02_0057_function_nullif.result
++++ /projects/datafuselabs/databend/tests/suites/0_stateless/02_function/02_0057_function_nullif.stdout
+@@ -3,7 +3,7 @@
+ 1
+ 1
+ NULL
+-a
++b
+ b
+ a
+ NULL
+
+Having 1 errors! 207 tests passed. 0 tests skipped.
+The failure tests:
+ /projects/datafuselabs/databend/tests/suites/0_stateless/02_function/02_0057_function_nullif.sql
+提示
+databend-query-standalone-embedded-meta.sh 等脚本中的 nohup 有助于在测试时同时输出日志到终端,可能同样有助于排查。databend-test 文件中的 timeout 改短。1、启动databend-query并创建用户
+./databend/bin/databend-query &
+mysql -uroot -h127.0.0.1 -P3307 -e "CREATE USER 'sqlancer' IDENTIFIED BY 'sqlancer'; GRANT ALL ON *.* TO sqlancer;"
+2、打包sqlancer
+git clone https://github.com/sqlancer/sqlancer.git
+cd sqlancer
+mvn package -DskipTests
+3、运行sqlancer
+#方式一,运行test单元
+DATABEND_AVAILABLE=true mvn -Dtest=TestDatabend test
+#方式二,运行jar包,可指定参数
+cd target
+java -jar sqlancer-*.jar --num-threads 4 --random-string-generation ALPHANUMERIC databend --oracle WHERE
+#运行成功每5s输出一条信息
+[2022/10/01 19:33:12] Executed 1037 queries (207 queries/s; 0.80/s dbs, successful statements: 100%). Threads shut down: 0.
+[2022/10/01 19:33:17] Executed 2133 queries (219 queries/s; 0.00/s dbs, successful statements: 100%). Threads shut down: 0.
+[2022/10/01 19:33:22] Executed 3248 queries (223 queries/s; 0.00/s dbs, successful statements: 100%). Threads shut down: 0.
+[2022/10/01 19:33:27] Executed 4351 queries (220 queries/s; 0.00/s dbs, successful statements: 100%). Threads shut down: 0.
+4、列举以下常用options(主可选项定义在MainOptions类,另外一个定义在DatabendOptions类)
+-h:查看帮助
+--num-threads:线程数
+--timeout-seconds:运行时间,单位秒,默认-1无限执行
+--num-tries:指定多少次异常后停止测试,默认100
+--database-prefix:数据库的前缀名
+--random-string-generation:随机字符串模式
+--host:主机,默认localhost
+--port:端口,默认3307
+--username:用户名,默认sqlancer
+--password:密码,默认sqlancer
+databend:指定的DBMS
+--oracle:测试的方式
+Non-optimizing Reference Engine Construction (NoREC)
+Ternary Logic Partitioning (TLP)
+当sqlancer停止测试后,会先清除原来的日志文件(注意备份),然后将所有错误写入到新的日志文件中 ./sqlancer/logs/databend/*.log 其中 *-cur.log 为某个db执行的sql记录。
若TLP检测出logic bug,日志文件会包含以下信息(错误的 query sql与重现db的sql):其中cardinality不一致说明发生了logic bug。
+--java.lang.AssertionError: the size of the result sets mismatch (3 and 6)!
+-- Time: 2022/08/29 16:57:50
+-- Database: databend1
+-- Database version: 8.0.26-v0.8.12-nightly-74d0287-simd(rust-1.64.0-nightly-2022-08-27T03:09:50.519081067Z)
+-- seed value: 1
+DROP DATABASE IF EXISTS databend1;
+CREATE DATABASE databend1;
+USE databend1;
+CREATE TABLE t0(c0BOOLEAN BOOLEAN NULL DEFAULT(true));
+CREATE TABLE t1(c0FLOAT DOUBLE NULL DEFAULT(0.8522535562515259), c1VARCHAR VARCHAR NULL);
+INSERT INTO t1(c0float) VALUES (0.48751503229141235);
+INSERT INTO t1(c0float, c1varchar) VALUES (0.8522535562515259, NULL);
+INSERT INTO t1(c1varchar) VALUES ('2'), ('78');
+INSERT INTO t0(c0boolean) VALUES (false), (false), (true);
+INSERT INTO t1(c0float) VALUES (0.8522535562515259), (0.48751503229141235);
+INSERT INTO t1(c0float, c1varchar) VALUES (0.48751503229141235, '7555834'), (0.7298239469528198, '8');
+-- SELECT t0.c0boolean FROM t0;
+-- cardinality: 3
+-- SELECT t0.c0boolean FROM t0 WHERE (NULL BETWEEN NULL AND NULL) UNION ALL SELECT t0.c0boolean FROM t0 WHERE (NOT (NULL BETWEEN NULL AND NULL)) UNION ALL SELECT t0.c0boolean FROM t0 WHERE (((NULL BETWEEN NULL AND NULL)) IS NULL);
+-- cardinality: 6
+TLP发现的bug例如:sqlancer: expression expansion error · Issue #7360 · datafuselabs/databend (github.com)
+若NoREC检测出logic bug,日志文件会包含以下信息(错误的query sql与重现db的sql):
+第一条 query sql 返回的是结果的row数,第二条 query sql 返回的是count的和,若两数不一致则出现logic bug。
+java.lang.AssertionError: SELECT t1.c0float, t1.c1varchar, t0.c0boolean FROM t1 RIGHT JOIN t0 ON true WHERE (NOT -1257754687); -- 3
+SELECT SUM(count) FROM (SELECT (((NOT -1257754687) IS NOT NULL AND (NOT -1257754687)) ::BIGINT)as count FROM t1 RIGHT JOIN t0 ON true) as res -- 0
+-- Time: 2022/09/24 09:27:50
+-- Database: databend1
+-- Database version: 8.0.26-v0.8.46-nightly-f524701-simd(rust-1.66.0-nightly-2022-09-23T16:20:13.611527635Z)
+-- seed value: 1
+DROP DATABASE IF EXISTS databend1;
+CREATE DATABASE databend1;
+USE databend1;
+CREATE TABLE t0(c0BOOLEAN BOOLEAN NULL DEFAULT(true));
+CREATE TABLE t1(c0FLOAT DOUBLE NULL DEFAULT(0.8522535562515259), c1VARCHAR VARCHAR NULL);
+INSERT INTO t1(c0float) VALUES (0.48751503229141235);
+NoREC发现的bug例如:bug: select error · Issue #7863 · datafuselabs/databend (github.com)
+NoREC与TLP测试期间还会检测出使得databend错乱的bug:
+如果报错信息有 Cause by 且报错信息很复杂则极有可能是bug,也可能是sqlancer生成的sql语法错误。
情况比较多,例如:
+long SQL makes parser work really slow. · Issue #7225 · datafuselabs/databend (github.com)
+ +Bug in numerical_coercion of in operator · Issue #7203 · datafuselabs/databend (github.com)
+sqlancer: expression expansion error · Issue #7360 · datafuselabs/databend (github.com)
+ +bug: where clause error · Issue #7457 · datafuselabs/databend (github.com)
+bug: expression evaluation error · Issue #7460 · datafuselabs/databend (github.com)
+ +bug: expression evaluation error · Issue #7460 · datafuselabs/databend (github.com)
+bug: the content of the result sets mismatch · Issue #7463 · datafuselabs/databend (github.com)
+ + +bug: Hash table capacity overflow · Issue #7495 · datafuselabs/databend (github.com)
+bug: cannot convert NULL to a non-nullable type · Issue #7498 · datafuselabs/databend (github.com)
+bug: expression explain error · Issue #7543 · datafuselabs/databend (github.com)
+bug: select view error · Issue #7573 · datafuselabs/databend (github.com)
+bug: select error · Issue #7863 · datafuselabs/databend (github.com)
+bug: where clause explain error · Issue #7864 · datafuselabs/databend (github.com)
+ +bug: return error after adding form and join · Issue #8000 · datafuselabs/databend (github.com)
+ + + + + + + + +身为项目维护者和贡献者,我们承诺使社区参与者不受骚扰,无论其年龄、体型、可见或不可见的缺陷、族裔、性征、性别认同和表达、经验水平、教育程度、社会与经济地位、国籍、相貌、种族、种姓、肤色、宗教信仰、性倾向或性取向如何。
+我们承诺以有助于建立开放、友善、多样化、包容、健康社区的方式行事和互动。
+有助于创造积极和谐环境的例子包括:
+不可接受的参与者行为包括:
+项目的维护者有责任解释和落实我们所认可的行为准则,并妥善公正地对他们认为不当、威胁、冒犯或有害的任何行为采取纠正措施。
+项目的维护者有权力和责任删除、编辑或拒绝或拒绝与本行为准则不相符的评论(comment)、提交(commits)、代码、维基(wiki)编辑、议题(issues)或其他贡献,并在适当时机知采取措施的理由。
+本守则适用于任何个人代表此项目或此项目社区时的项目空间和公共空间。项目代表将由项目维护者进一步定义和阐述。
+如遇到辱骂、骚扰或其它不被接受的行为,请联系 psiace@datafuselabs.com 上报项目团队。所有投诉都将被审核调查,并给出核定后的结果。具体措施的细节可能会单独发布。
+违背行为守则的项目维护者, 在其他的项目维护者决定下,可能面临临时或永久的惩罚。
+本行为准则改编自 Contributor Covenant 2.1 版, 参见 https://www.contributor-covenant.org/version/2/1/code_of_conduct.html。
+ + + + + + +这里列出一些协作相关的基本流程。
+++适用于已经列在大纲下面的文章/主题。
+
++适用于已规划的大纲中不涉及的文章/主题。
+
欢迎 打开 issue 或 新建 Pull Request 帮助改进内容和版面。
+在反馈/修改时,请提供相关上下文以帮助判断问题现状。
+本站使用 https://giscus.app/ 关联 Github Discussions 。
+文章相关的讨论建议在对应文章的评论区中进行。如有一般性话题,请在 Github Discussions 中选择合适的板块发布。
+可以向以下 Databend 贡献者寻求 Review 支持:
+| 分类 | GitHub |
|---|---|
| Meta | drmingdrmer |
| Query | sundy-li |
| Optimizer | leiysky |
| Cluster | zhang2014 |
| Storage | dantengsky Xuanwo |
| Common | PsiACE |
已上线
+进行中
+规划中
+需调整
+规划中
+已上线
+规划中
+预计以视频和文字稿形式发布,按模块进行规划。
+已上线
+规划中
+规划中
+待定
+预期会以视频结合文字稿的形式发布。
+ + + + + + + + +Databend 是一个使用 Rust 研发、开源、完全面向云架构的新式数仓。
+「Databend 内幕大揭秘」将会透过 Databend 的设计与实现,为你揭开面向云架构的现代数据库的面纱。
+「Databend 内幕大揭秘」并不致力于展示数据库领域的全貌,而是紧紧围绕 Databend 来展示现代云数仓的方方面面:设计与架构、算法与实现等。
+本书大概可以分为三个部分:
+「Databend 内幕大揭秘」的内容完全开源,有意向参与协作和贡献的,请参考「贡献相关」一节的内容。
+ + + + + + + + +本篇是 minibend 系列的第二期,将会介绍 Data Source 部分的设计与实现,当然,由于是刚开始涉及到编程的部分,也会提到包括 类型系统 和 错误处理 之类的一些额外内容。
+++前排指路视频和 PPT 地址
+视频(哔哩哔哩):https://www.bilibili.com/video/BV1A84y1Y7Ff/
+PPT:https://databend-internals.psiace.me/minibend/ppt/minibend-002-datasource.pdf
+
这里仅仅是进行一个初步的介绍,类型系统相关的实现请期待下一期内容。
+在构建查询引擎的时候,很重要的一个问题就是「数据在查询引擎中是如何表示的?」。这往往意味着我们需要考虑引入一套类型系统来完成这一工作。
+为了能够让查询引擎处理来自不同数据源的数据,通常情况下,会选择设计并构建一套能够涵盖所有数据源所涉及的全部数据类型的类型系统,并引入一些额外的机制使得数据能够从数据源轻松转换到这套类型系统之上。
+当然,如果查询引擎仅仅针对单一数据源设计,或许可以考虑复用数据源的类型系统。
+解决了数据类型的问题,那么就该考虑数据存储时候的模型。行式存储和列式存储都属于流行的方案,当然,这往往取决于要面对什么样的查询任务。另外还有混合行式和列式存储的方案,但这并不在今天讨论的范畴之中。
+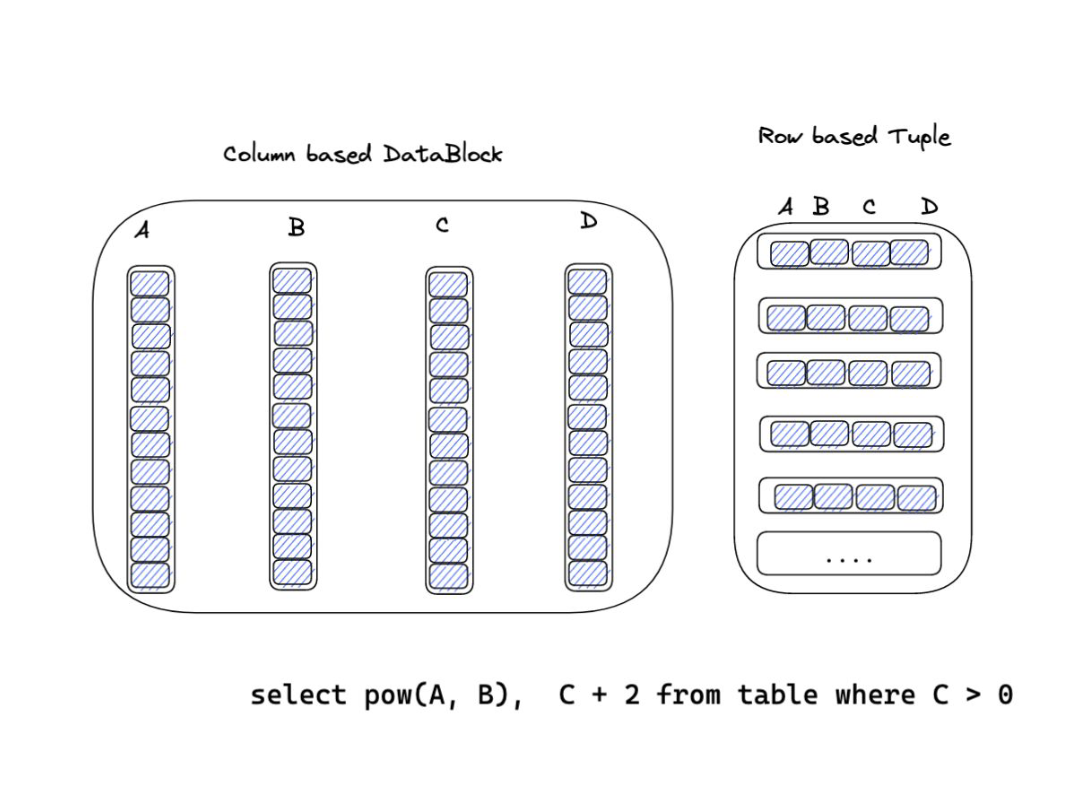
对于 OLAP 系统,往往处理大量数据,更需要关注数据的吞吐量和执行效率,采用列式存储具有天然的优势。
+Apache Arrow 是一套通用、跨语言、高性能的列式数据内存格式规范,能够充分利用现代硬件的向量化执行能力。
+通过引入 Apache Arrow 作为标准的数据交换格式,可以有效提高各种大数据分析系统和应用程序之间的互操作性:
+Apache Arrow 现在有多种不同语言的实现,包括 C++、Java、Rust 等。
+值得关注的基于 Apache Arrow 的 Rust 实现的项目包括 pola-rs/polars、apache/arrow-datafusion,当然,还有 Databend 。
+Databend 是面向海量数据设计的云数仓,面向分析型工作负载进行设计,采用列式存储,使用 Apache Arrow 作为内存格式规范,并在此基础上设计开发类型系统。minibend 在这一点上将会与 Databend 保持一致。
+Databend 当前实现使用的是 arrow2 而非 arrow-rs ,主要有以下几个原因:
+Databend 从 arrow2 0.1 和 parquet2 0.1 发布 开始 考虑向 arrow2 迁移 ,十天左右完成 [commons] arrow -> arrow2 并在部分查询上获得性能提高。尽管从当时而言,切换到还处于早期的 arrow2 有些激进,但长远来看是利大于弊的。
+Data Source(数据源)是数据处理系统的重要部分,但通常只能依赖经验来谨慎处理。
+顾名思义,数据源就是数据的来源,倘若没有数据源,数据处理系统就像无根浮萍,自然也谈不上用武之地。
+数据源可以以不同的形态出现,比如各种各样格式的文件:CSV、JSON、Parquet 等;当然也可以是数据库,之前有很多朋友问过比如 Databend 能不能查询 MySQL 里面的数据(将 MySQL 作为数据源);也可以是内存对象,一个不那么典型的例子是 Databend 里面实现了用于测试向量化性能的 number 表。
+与不同数据源交互的处理逻辑也有所不同,为了能够更好接入不同数据源,查询引擎需要定义一套统一的接口,并确保能够返回符合预期的数据。对于查询引擎而言,主要关心两类数据:一类是 schema ,用来描述数据的结构,这可以帮助查询引擎对查询计划和表达式进行验证,但并不是所有数据都具有统一的/有效的结构,比如 JSON ;另一类就是具体的数据了,但考虑到查询引擎只需要处理关心的特定数据,所以应该有能力对数据进行过滤,只提取需要的列。
+ApacheParquet 是一种开源的、面向列的数据文件格式,用于高效的数据存储和检索。它提供了高效的数据压缩和编码方案,增强了处理大量复杂数据的性能。Parquet 支持多种语言,包括 Java、 C + + 、 Python 等等。.
+Parquet 受到 Google Dremel 格式启发,作为大数据领域的存储格式,被 iceberg 、hive 等各种系统使用。
+上图展示了 Parquet 文件的结构,Parquet 的存储模型主要由行组(Row Group)、列块(Column Chuck)、页(Page)组成。
+Databend 的底层存储格式为 Parquet ,过去其他格式的数据需要通过 Streaming Load 或者 Copy Into 等方式转换到 Databend 支持的 Parquet 格式。而在近期的设计和实现中,Databend 开始逐步实现对位于本地/远端的文件进行查询的支持。
+minibend 将会考虑优先从查询本地现有数据文件开始进行支持。首先是支持 Parquet 作为数据源,但为了方便浏览数据和审计查询结果,或许对 CSV 格式的支持应该提上日程。
+Databend 中同样包含读取 Parquet 文件作为数据源的代码。关于读取 Parquet 文件作为表的第一版实现可以参考 new table function read_parquet to read parquet files as a table 。
+在这个基础上,受 clickhouse-local 启发,@eastfisher 为 Databend 实现 databend-local,支持在不启动 Databend 集群的情况下查询本地文件。
+请查阅视频和 PPT 中的对应部分,或者查看 PR #40 | minibend: impl parquet data source 中的代码。
+在今天的内容中,我们简单介绍了类型系统和数据源的一些相关内容:
+当然,在这一期的代码时间,我们初步建立了 minibend 的基础,并支持使用 Parquet 文件作为数据源。
+下一期,我们将会进入到类型系统相关的部分,并进一步扩展到逻辑计划和表达式。
+这一次推荐两个博客给大家:
+一个是 风空之岛 ,@mwish 的技术博客,有关于 Parquet 的一个更详细的系列介绍,并且还有论文阅读的部分。
+另一个是 数据库内核月报 ,来自阿里云 PolarDB 数据库内核团队。
+ + + + + + + + +minibend ,一个从零开始、使用 Rust 构建的查询引擎。这里是 minibend 系列技术主题分享的第一期,来自 @PsiACE 。
+
++前排指路视频和 PPT 地址
+视频(哔哩哔哩):https://www.bilibili.com/video/BV1Ne4y1x7Cn
+PPT:https://databend-internals.psiace.me/minibend/ppt/minibend-001-basic-intro.pdf
+
minibend 是一款从零开始、使用 Rust 构建的查询引擎。
+查询引擎是数据库系统的一个重要组件,需要具备以下几点能力:
+通常我们会使用 SQL 也就是结构化查询语言进行交互。
+minibend 同时也是 Databend Internals,或者说 Databend 内幕大揭秘 这个手册的实战部分。Databend 内幕大揭秘 将会透过 Databend 的设计与实现,为你揭开面向云架构的现代数据库的面纱。
+
特别是在团队已经孵化出 Databend 这个现代开源云数仓的前提下,为什么还需要这样一个项目?
+先回到 Databend 内幕大揭秘 的初衷,设立这个项目是为了吸引更多人参与到 Databend 的学习、开发和生态建设中,所以目标受众定位在:
+但是,Databend 的更新迭代速度、代码量都意味着对刚开始接触 Rust 并尝试参与研发的新朋友会面临一个比较高的门槛。
+从现存的教程上看,或多或少存在一些问题:
+所以开启一个新的项目作为连接新开发者和 Databend 之间的纽带就成为一种自然的选择。
+++P.S. minibend 致力于解决这些问题,但可能很难完全解决,但至少,先开始运作起来。
+
首先,minibend 会提供视频、文章和代码三种材料。文章和代码将会同步到 Databend 内幕大揭秘 的 Repo 中,而视频则会发布到 Databend 的 B 站官方帐号下。欢迎大家持续关注。
+++Databend 内幕大揭秘:https://databend-internals.psiace.me/
+Databend(哔哩哔哩):https://space.bilibili.com/275673537
+
更新频率大概是每个月一到两期。内容上会包含必要的相关知识导读、设计和实现相关的说明、并进行回顾和展望。当然,也会不定期精选一部分论文摘要供大家进一步研讨和学习。
+在这个部分,我们不会深入数据库的细节,只是从部分组件的视角上进行观察。
+存储解决的是两个问题,存在哪 以及 怎么存 。
+对于“怎么存”,不同背景的朋友可能会考虑到一些不同的细节,但大多数时候,可以想象到一个基本的模式是:数据以特定格式写入到某几类文件中,比如 Parquet 甚至 CSV 。
+但是“存在哪”呢?
+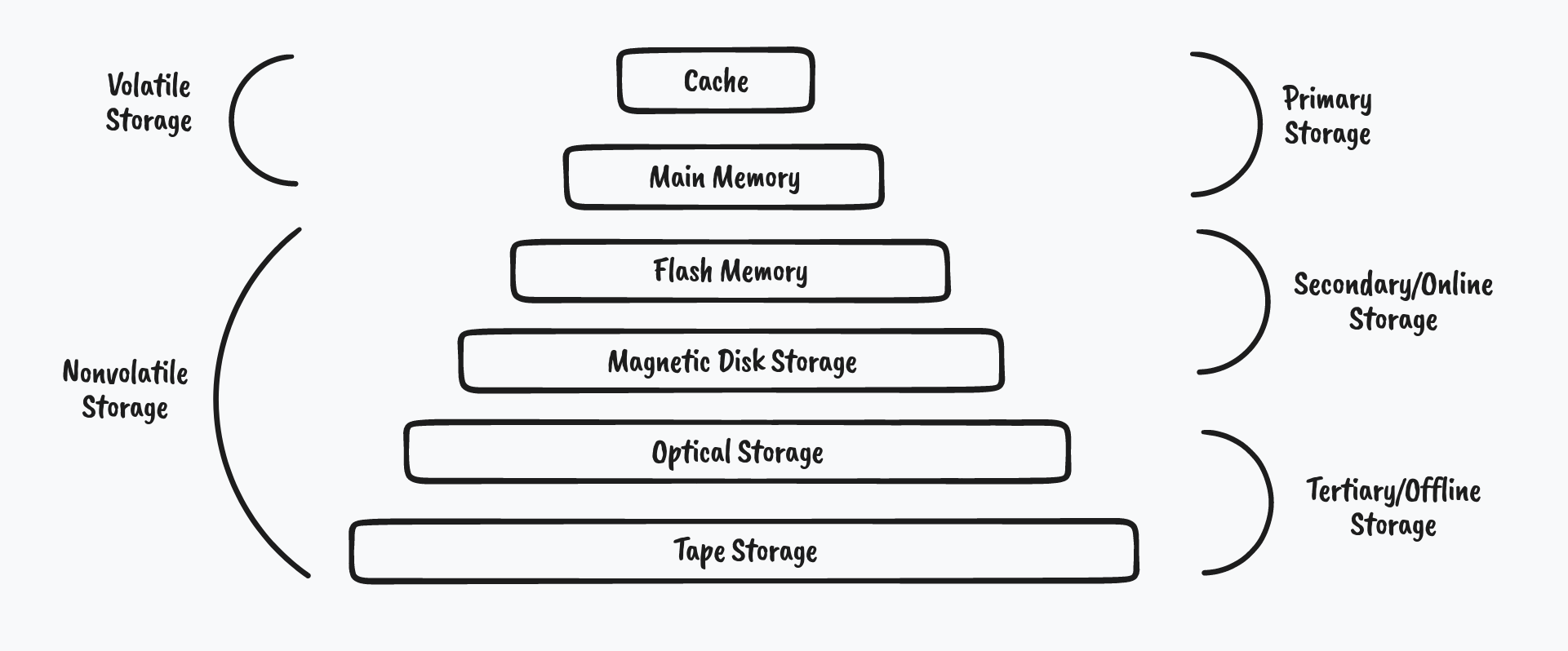
过去的一些存储方案更加关注上图所示的存储体系结构,将需要在线处理的数据存放在闪存和硬盘中,用于备份的数据放入光盘和磁带。
+云存储的兴起和网络带宽的不断提高带来了一些新的变化:云存储能够支持远程保存数据和文件,并通过网络连接进行访问。不仅可以节约拓展物理器件所带来的人力物力消耗,并能够提供更好的弹性以便于即时增减容量,还支持按需按量付费从而做到更好的成本管理与控制。
+Databend 早期的实现是包含一套分布式文件系统的,但到现在,存储的重心完全转移到云厂商提供(AWS S3, Azure Blob 等)或者自托管(MinIO 等)的云存储之上。
+尽管云存储越来越重要,但原有的经验和见解依然有效,我们仍然可以使用缓存和并行技术来改善性能,利用冗余来提高可靠性。
+引入索引的好处在于加快数据查询的速度,而缺点则在于构建和维护索引同样需要付出代价。
+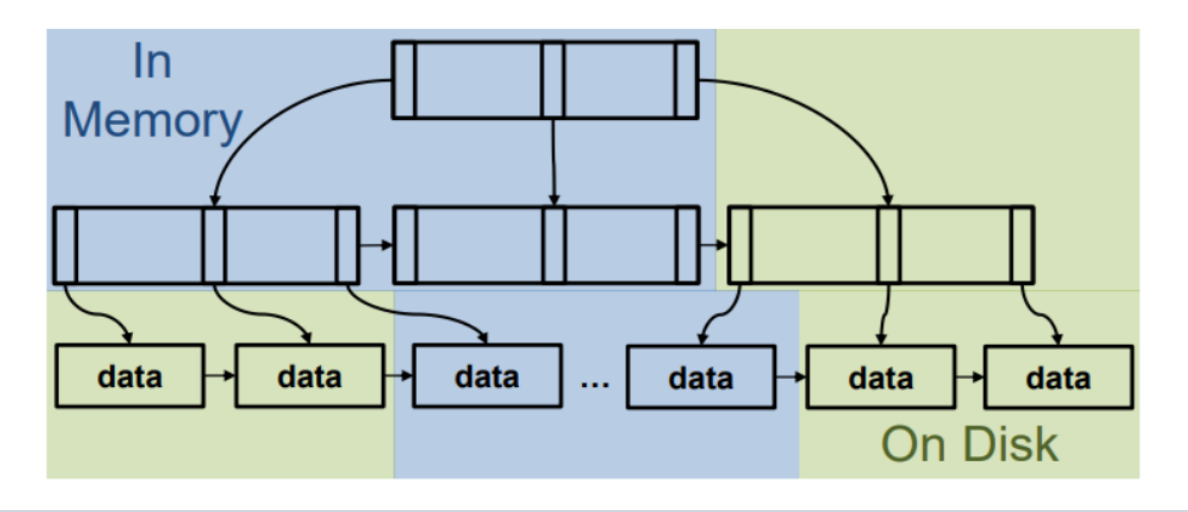
不同的索引可以针对不同的场景提供优化,B Tree 能够加速范围查询,而等值查询就可以使用 Hash 索引,BitMap(或者说更常用的 Bloom 索引)可以方便判断数据是否存在。
+Databend 的索引无需人为创建,由部署的实例自行维护。同时也采用了像 Xor 索引 这样的新技术来进一步加速查询并提高空间利用率。
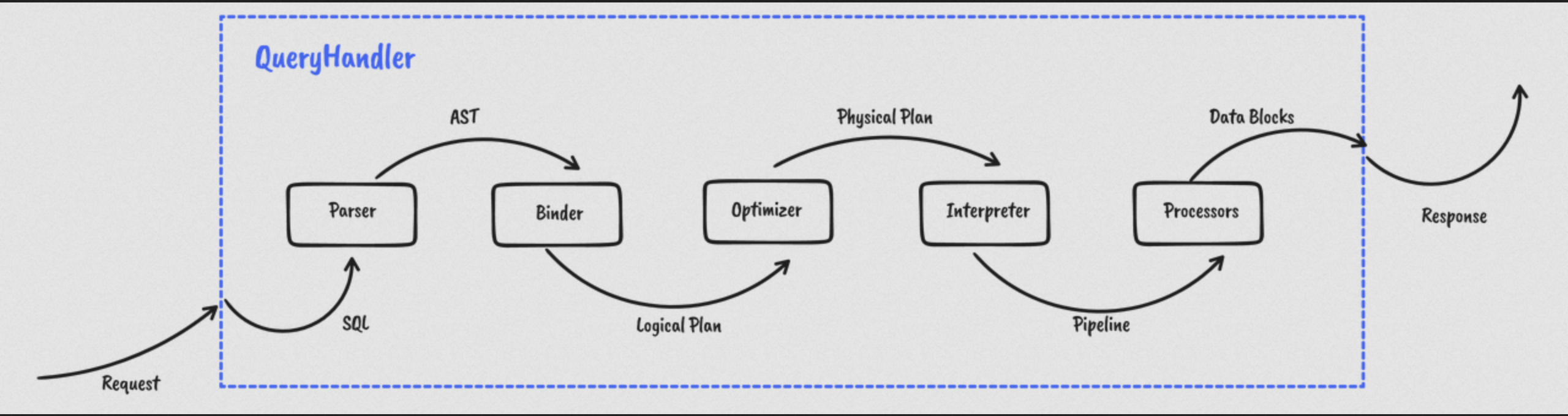
+尽管有各种各样的查询引擎,但具体到查询执行的环节大同小异,这里以 Databend 为例,简单讲一下过程。
+
那么近年来新兴数据库大多受到 Morsel-Driven Parallelism 这篇论文的启发,在运行时确定任务的并行度,按流水线的方式执行操作,并通过调度策略来尽量保证数据的本地化,在实现 load banlance 的同时最小化跨域数据访问。
+同时,引入列式存储和向量化执行的技术,可以避免不必要的缓存和 I/O 资源浪费,同时,节约处理数据时需要传递的数据量,为进一步优化提供更多空间。
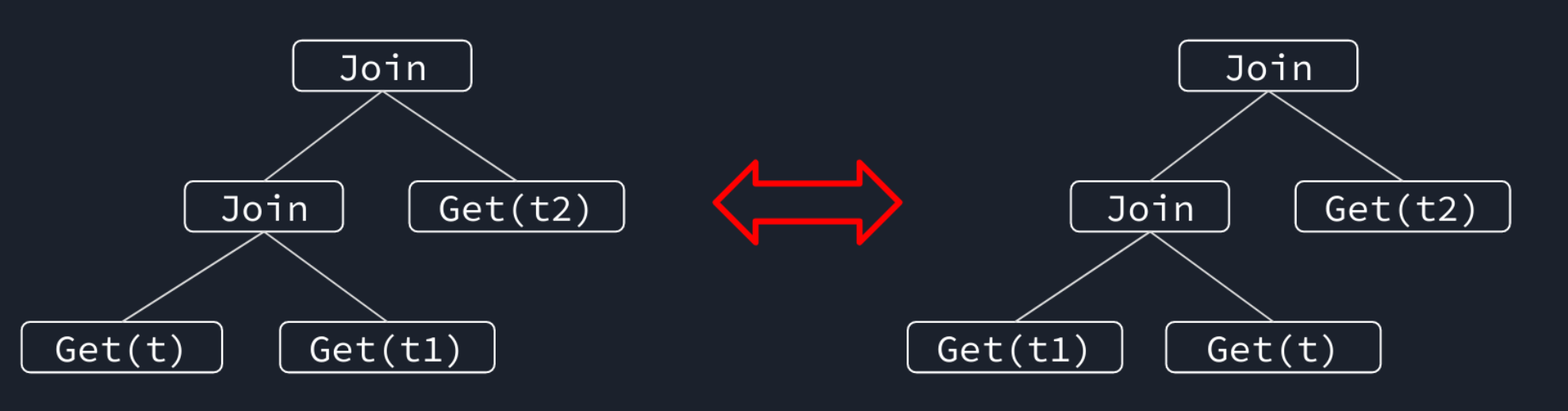
+查询执行的路径并非一成不变,不同的执行计划在不同场景下性能也存在差异,如何为查询选择合适的计划就是查询优化需要关注的内容。
+下面的图片展现的是一种典型的查询优化,对 JOIN 进行重排。
+
目前有两种主要的查询优化方案,一种是基于关系代数和算法的等价优化方案,一种是基于评估成本的优化方案。根据命名,不难看出优化的灵感来源和这两种方案在优化上的取舍。
+那么如何进行查询优化呢?查询优化通常包含以下四个步骤:
+Databend 引入了基于规则的 Cascades 优化器,通过自顶向下探索、模式匹配以及记忆化来提供更好的查询优化能力。
+大规模并行处理是大数据计算引擎的一个重要特性,可以提供高吞吐、低时延的计算能力。那么,当我们在讨论大规模并行处理时,究竟在讨论什么?
+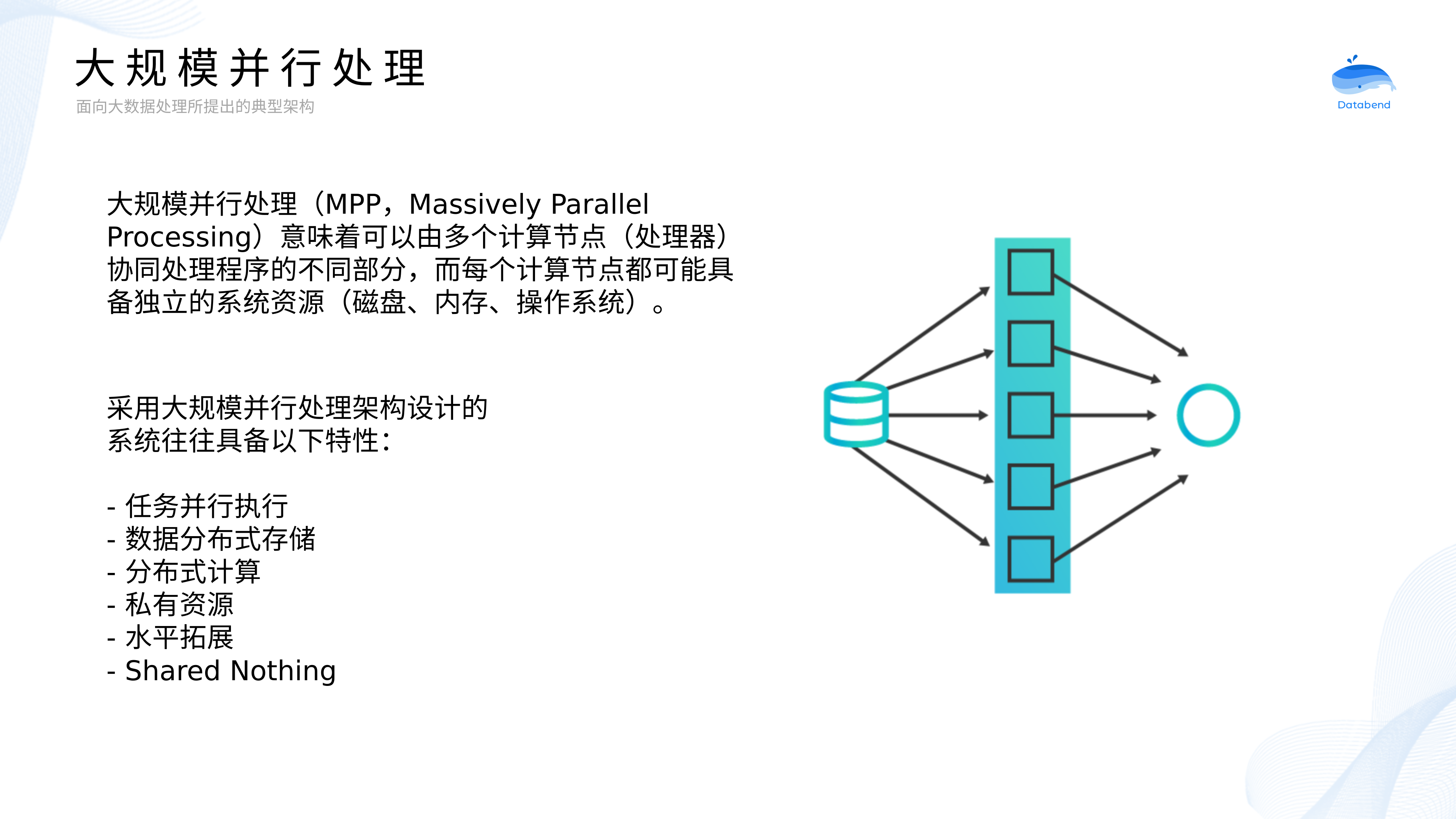
大规模并行处理(MPP,Massively Parallel Processing)意味着可以由多个计算节点(处理器)协同处理程序的不同部分,而每个计算节点都可能具备独立的系统资源(磁盘、内存、操作系统)。
+计算节点将工作拆分成易于管理、调度和执行的任务执行,通过添加额外的计算节点可以完成水平拓展。随着计算节点数目的增加,对数据的查询处理速度就越快,从而减少大数据集上处理复杂查询所需的时间。
+在近些年,MPP 和分布式设计往往会同时出现在同一套系统中。
+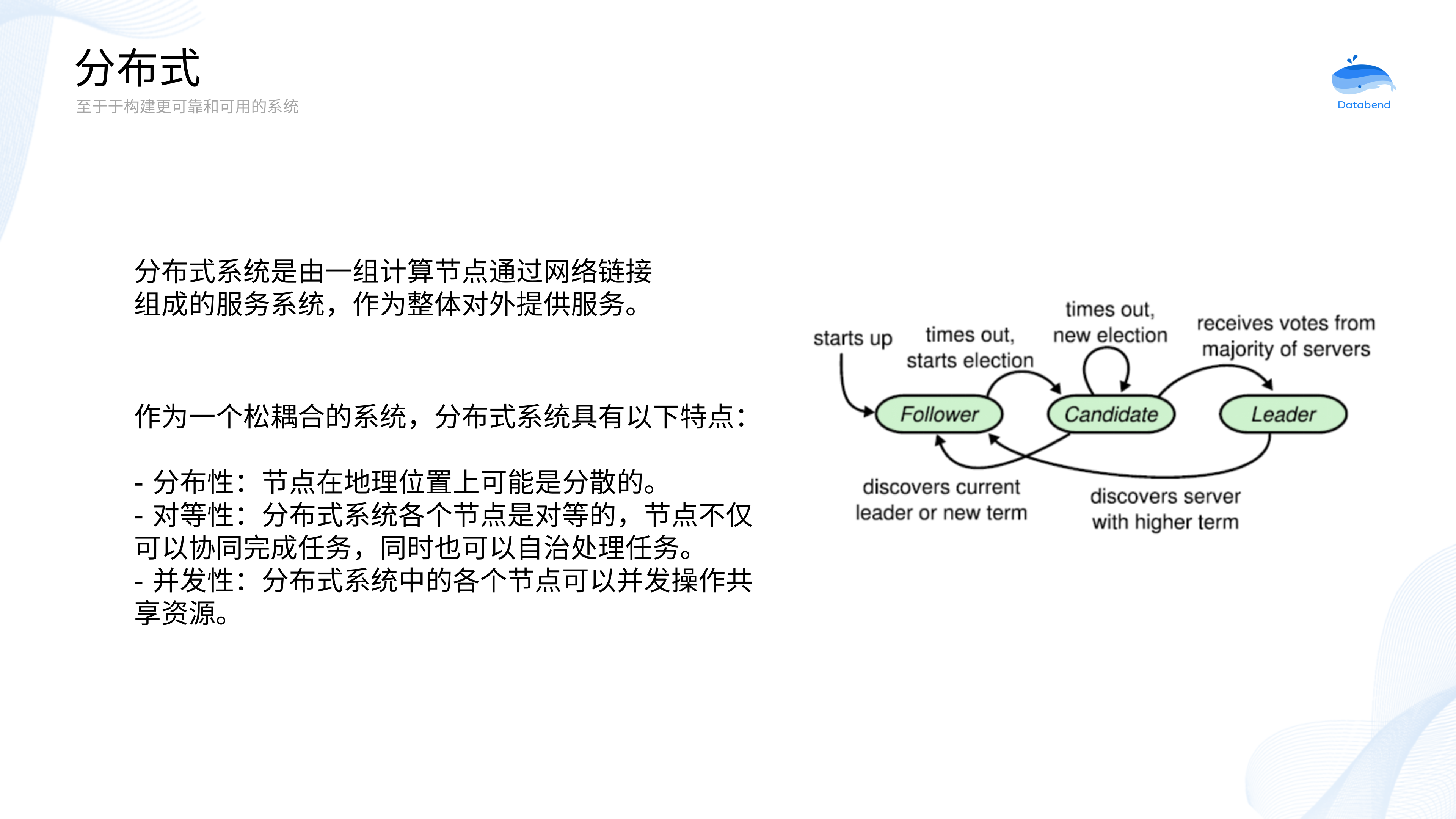
从某种视角上看,分布式系统与 MPP 系统有着惊人的相似。比如:通过网络连接、对外作为整体提供服务、计算节点拥有资源等。但是这两种架构仍然会有一些不同。
+刚刚介绍了数据库相关的一些基本概念,现在让我们将目光转向 Rust ,来一同了解这个正在走向流行的编程语言。
+
Rust 官方宣传语是:Rust 是一门赋予每个人构建可靠且高效软件能力的语言,现在距离它第一个版本发布也已经过去10年。
+Rust 没有运行时和垃圾回收,速度快且内存利用率高,几乎可以与 C 和 C++ 竞争。
+Rust 的类型系统和所有权模型为内存安全和线程安全提供保障,在编译期就能够消除各种各样的错误。
+特别值得一提的是,Rust 工具链内置很多实用工具,可以切实改善生产力:包管理器、构建工具、格式化程序、用于代码审计的 Clippy 等等。
+#[allow(dead_code)]
+// Functions
+// `i32` is the type for 32-bit signed integers
+fn add2(x: i32, y: i32) -> i32 {
+ // Implicit return (no semicolon)
+ x + y
+}
+上面函数是两个 32 位整数相加,返回值也是一个 32 位整数。值得注意的是,我们需要标注返回值类型,而函数体中的 x + y 是一种隐式返回,所以不需要添加 return 关键字,当然,也不需要在末尾添加分号。只添加末尾分号的话,则会将其视为普通语句执行,就没有返回值了(报错)。
// This is the main function
+fn main() {
+ // Statements here are executed when the compiled binary is called
+
+ // Print text to the console
+ println!("Hello World!");
+}
+经典的 Hello World 程序,大家应该会感觉到熟悉。main 函数也是 Rust 程序的入口点。通过调用 println! 这个宏,可以输出文本到终端。
// Struct
+struct Point {
+ x: i32,
+ y: i32,
+}
+
+// A struct with unnamed fields, called a ‘tuple struct’
+struct Point2(i32, i32);
+
+// Enum with fields
+enum OptionalI32 {
+ AnI32(i32),
+ Nothing,
+}
+
+// Generics //
+struct Foo<T> { bar: T }
+
+// Traits (known as interfaces or typeclasses in other languages) //
+trait Frobnicate<T> {
+ fn frobnicate(self) -> Option<T>;
+}
+
+impl<T> Frobnicate<T> for Foo<T> {
+ fn frobnicate(self) -> Option<T> {
+ Some(self.bar)
+ }
+}
+除了基本的字符串、整数、浮点数、布尔类型之外,Rust 还支持结构体和枚举类型,代码片段提供了一个基本的例子。为这些类型可以实现特定的方法,以支持各种各样的操作,通用的接口可以使用 trait 关键字进行定义。
let foo = OptionalI32::AnI32(1);
+match foo {
+ OptionalI32::AnI32(n) => println!("it’s an i32: {}", n),
+ OptionalI32::Nothing => println!("it’s nothing!"),
+}
+
+// Advanced pattern matching
+struct FooBar { x: i32, y: OptionalI32 }
+let bar = FooBar { x: 15, y: OptionalI32::AnI32(32) };
+
+match bar {
+ FooBar { x: 0, y: OptionalI32::AnI32(0) } =>
+ println!("The numbers are zero!"),
+ FooBar { x: n, y: OptionalI32::AnI32(m) } if n == m =>
+ println!("The numbers are the same"),
+ FooBar { x: n, y: OptionalI32::AnI32(m) } =>
+ println!("Different numbers: {} {}", n, m),
+ FooBar { x: _, y: OptionalI32::Nothing } =>
+ println!("The second number is Nothing!"),
+}
+模式是 Rust 中特殊的语法,它用来匹配类型中的结构,看起来有点像 switch,但要更加强大和简洁。无论类型是简单还是复杂,结合使用模式和 match 表达式以及其他结构可以提供更多对程序控制流的支配权。通过将一些值与模式相比较来使用它。如果模式匹配这些值,就可以对值的部分进行相应处理。
// for and ranges
+for i in 0u32..10 {
+ print!("{} ", i);
+}
+println!("");
+// prints `0 1 2 3 4 5 6 7 8 9 `
+
+// `if` as expression
+let value = if true {
+ "good"
+} else {
+ "bad"
+};
+
+// `while` loop
+while 1 == 1 {
+ println!("The universe is operating normally.");
+ // break statement gets out of the while loop.
+ // It avoids useless iterations.
+ break
+}
+
+// Infinite loop
+loop {
+ println!("Hello!");
+ // break statement gets out of the loop
+ break
+}
+上面是一些常见的控制流语法,for 循环和范围迭代看起来和其他语言很相似;而通过 let - if 语句,可以轻松将 if 当作表达式来使用;当然,Rust 同样支持 while 循环和无限 loop 循环。
// Owned pointer – only one thing can ‘own’ this pointer at a time
+// This means that when the `Box` leaves its scope, it can be automatically deallocated safely.
+let mut mine: Box<i32> = Box::new(3);
+*mine = 5; // dereference
+// Here, `now_its_mine` takes ownership of `mine`. In other words, `mine` is moved.
+let mut now_its_mine = mine;
+*now_its_mine += 2;
+
+println!("{}", now_its_mine); // 7
+// println!("{}", mine); // this would not compile because `now_its_mine` now owns the pointer
+Owned Pointer,一次只能有一个对象“拥有”此指针,这意味着当 Box 离开其作用域时,它可以安全地自动释放。
// Reference – an immutable pointer that refers to other data
+// When a reference is taken to a value, we say that the value has been ‘borrowed’.
+// While a value is borrowed immutably, it cannot be mutated or moved.
+// A borrow is active until the last use of the borrowing variable.
+let mut var = 4;
+var = 3;
+let ref_var: &i32 = &var;
+
+println!("{}", var); // Unlike `mine`, `var` can still be used
+println!("{}", *ref_var);
+// var = 5; // this would not compile because `var` is borrowed
+// *ref_var = 6; // this would not either, because `ref_var` is an immutable reference
+ref_var; // no-op, but counts as a use and keeps the borrow active
+var = 2; // ref_var is no longer used after the line above, so the borrow has ended
+Reference – 引用其他数据的不可变指针。当引用某个值时,我们称该值已被 “借用” 。当一个值被不可变借用时,它不能被修改或移动。借用直到在最后一次使用借用变量之前会一直处于活跃状态。
+// Mutable reference
+// While a value is mutably borrowed, it cannot be accessed at all.
+let mut var2 = 4;
+let ref_var2: &mut i32 = &mut var2;
+*ref_var2 += 2; // '*' is used to point to the mutably borrowed var2
+
+println!("{}", *ref_var2); // 6 , // var2 would not compile.
+// ref_var2 is of type &mut i32, so stores a reference to an i32, not the value.
+// var2 = 2; // this would not compile because `var2` is borrowed.
+ref_var2; // no-op, but counts as a use and keeps the borrow active until here
+可变引用,如果你有一个对该变量的可变引用,你就不能再创建对该变量的引用。
+上面的这些 Rust 片段节选自 Learn X in Y minutes ,只进行了一些粗浅的介绍。
+如果想要进一步学习,建议查阅以下资料:
+首先我们介绍了 minibend 这个系列课程,一方面,这会是一个从零开始、使用 Rust 构建的查询引擎;另一方面,它会参考 Databend 的设计,并致力于降低数据库内核开发的门槛。
+而在数据库相关基础知识的部分,云存储为现代数据库设计带来了一些新变化,而不同的索引又可以为不同的查询场景带来性能优化,接着是查询执行和查询优化的相关知识,以及对大规模并行处理和分布式技术的介绍。
+Rust 不完全指南里,从函数、类型、模式匹配、控制流、内存安全与指针进行了一个简单的介绍,为阅读 Rust 代码提供了一个简单的基础。
+下一期,我们将会介绍 Apache Arrow - 一种列式存储的内存格式规范,以及查询引擎中的类型系统,然后试着写一些关于数据源的代码。
+
本期课程推荐两本书给大家:
+一本是 The Rust Programming Language ,这是 rust 官方出品的 Rust 书籍,一般被称作 the book 。
+另一本是 How Query Engines Work ,Andy 同时也是 Datafusion 和 Ballista 的作者,不过这本书使用的是 kotlin 。
+ + + + + + + + +本篇文章是对 Databend 在 RustChinaConf 2022 上演讲的一个全文回顾。涉及「Databend 的架构和设计」以及「Databend 团队的 Rust 之旅」。+
那么,在进入正题之前,让我们先来回答这样一个问题:“什么是 Databend”?
+
官方的说法是:Databend 是一个使用 Rust 研发、开源、完全面向云架构的新式数仓。
+借用当下大数据分析领域最流行的两个数据库产品打个比方:Databend 就像是开源的 Snowflake 或者说云原生的 Clickhouse 。
+作为新式数仓,Databend 有哪些基本特性呢?
+
TIME TRIVAL,可以轻松回滚到任意时间节点。刚刚介绍了 Databend 的一些基本信息,接下来,让我们一起走进 Databend 的架构和设计。看看一个存算分离的云原生数仓该是什么样子。
+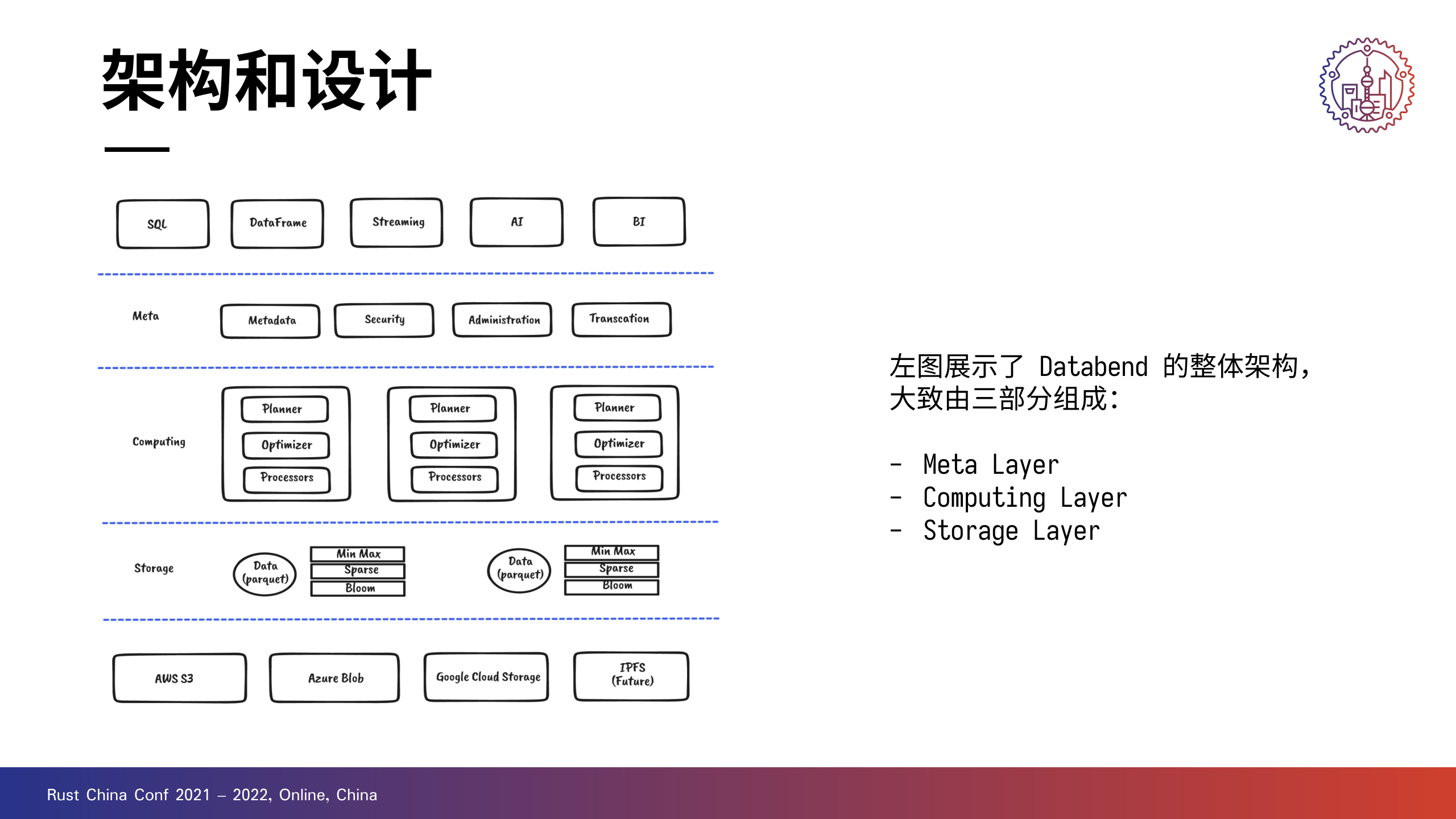
右边是 Databend 的一个架构图。
+最上一层对接 AI、BI 等应用,最下一层打通 S3、GCS、IPFS 等存储系统。中间三层则是 Databend 的主体部分。
+Databend 可以分成 Meta、Computing 和 Storage 三层,也就是元数据、计算和存储。
+说是存储层,其实叫做数据访问层更贴切一些。
+
Meta 是一个多租户、高可用的分布式 key-value 存储服务,具备事务能力。
+它会负责管理元数据,像索引和集群的一些信息;Meta 还具备租户管理的能力,包括权限管理以及配额使用统计。
+当然,安全相关的部分也由 Meta 承担,比如用户登录认证。
+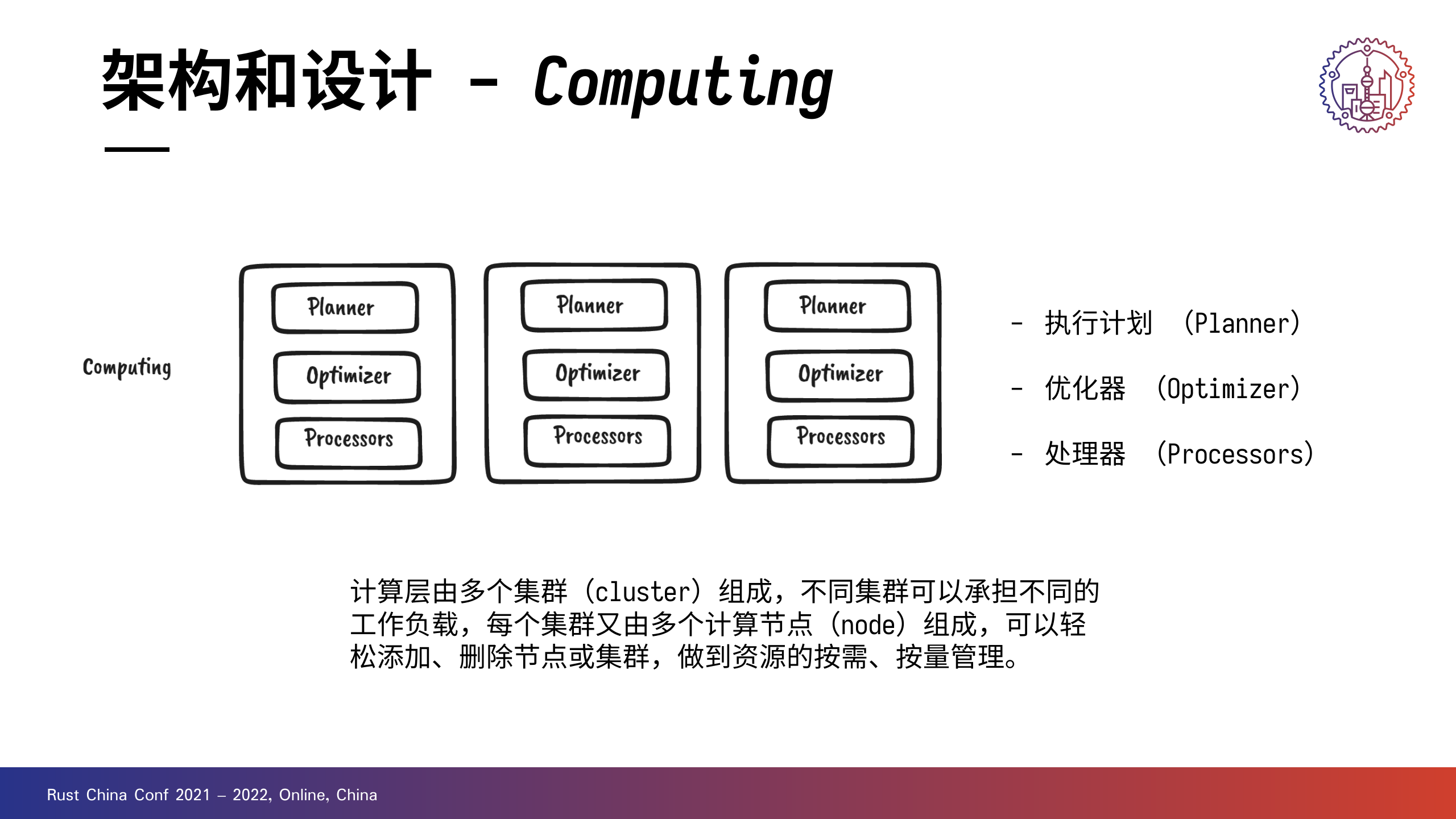
计算层可以由多个集群组成,不同集群可以承担不同的工作负载。每个集群又可以由多个计算节点(node)组成。
+计算层中的核心组件有三个:
+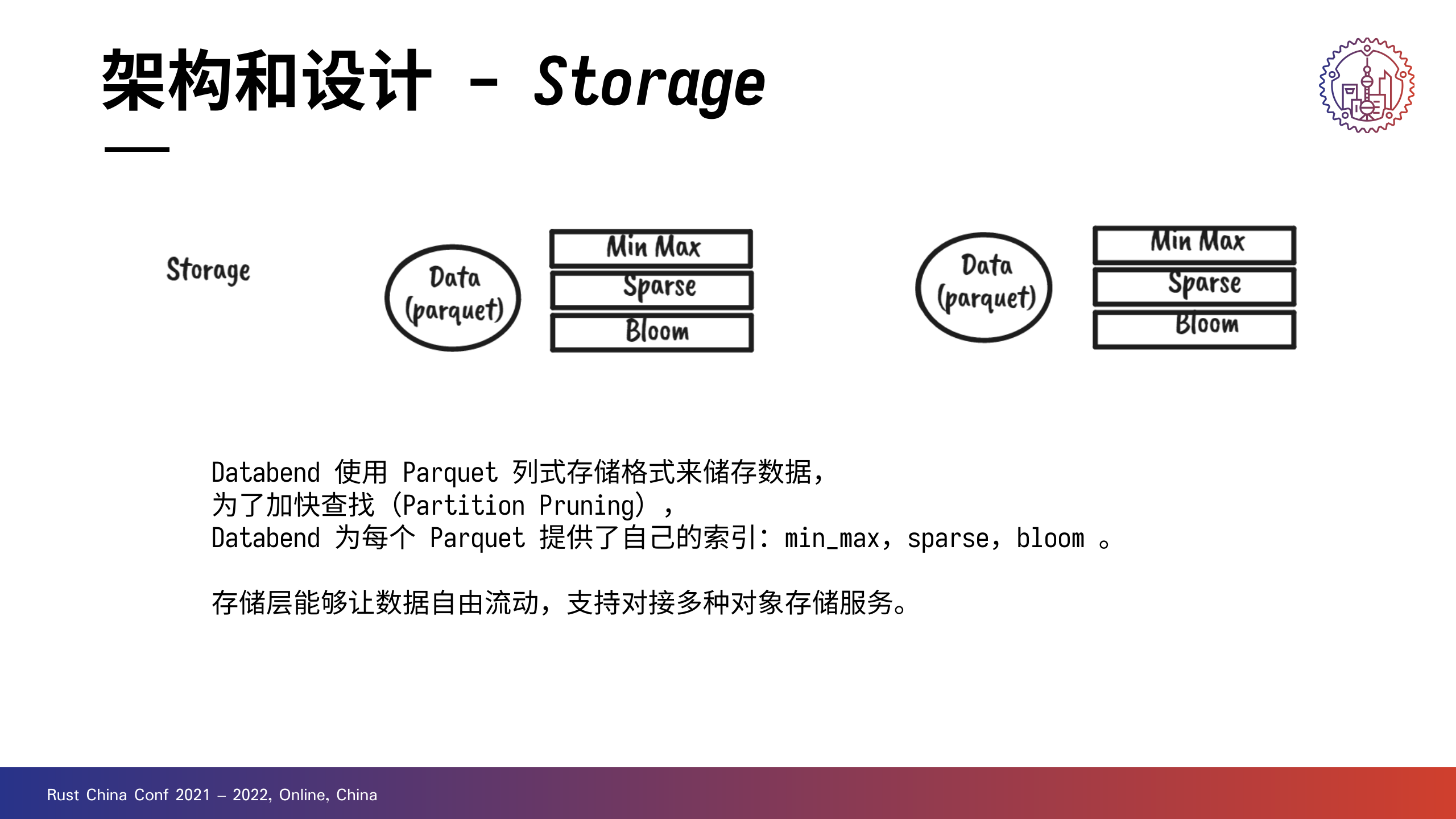
Databend 使用 Parquet 格式储存数据,为了加快查找(Partition Pruning),Databend 为每个 Parquet 提供了自己的索引:min_max,bloom 。这一部分工作是放在存储层完成的。
+前面其实有提到,存储层的另一个说法是数据访问层。
+一方面,它支持对接多种对象存储服务,像 AWS S3 和 Azure Blob,做到让数据自由流动。当然也支持在本地文件系统做测试,但是没有做专门的性能优化。
+另一方面,存储层也支持挂载多种 catalog,在社区小伙伴的帮助下,Databend 完成了 Hive 引擎的对接,支持进行一些简单的查询。
+“存算分离”、“云原生”对于新式数仓而言,只能算是基本特性。除了卯足劲大搞性能优化之外,还有没有其他值得关注的地方呢?让我们一起来看一下。
+好的产品是一定会强调用户体验的,Databend 作为一款云数仓产品,自然要关注查询体验。
+那么,在新的 parser 和 planner 中,Databend 引入了语义检查的环节,在查询编译过程中就可以拦截大部分错误。
+
右图展示的正是两类语义错误,一类是使用了不存在的 Column ,一类是 Column 具有歧义。
+其实新 planner 除了更加友好的查询体验之外,还为支持复杂查询打下了扎实的基础。那么 Databend 现在可以支持多种 Join 和关联子查询,感兴趣的小伙伴可以体验一下。
+在引入新 Planner 之后,计算层的架构得到进一步的划分,当一个查询请求进来以后,会经过以下处理:
+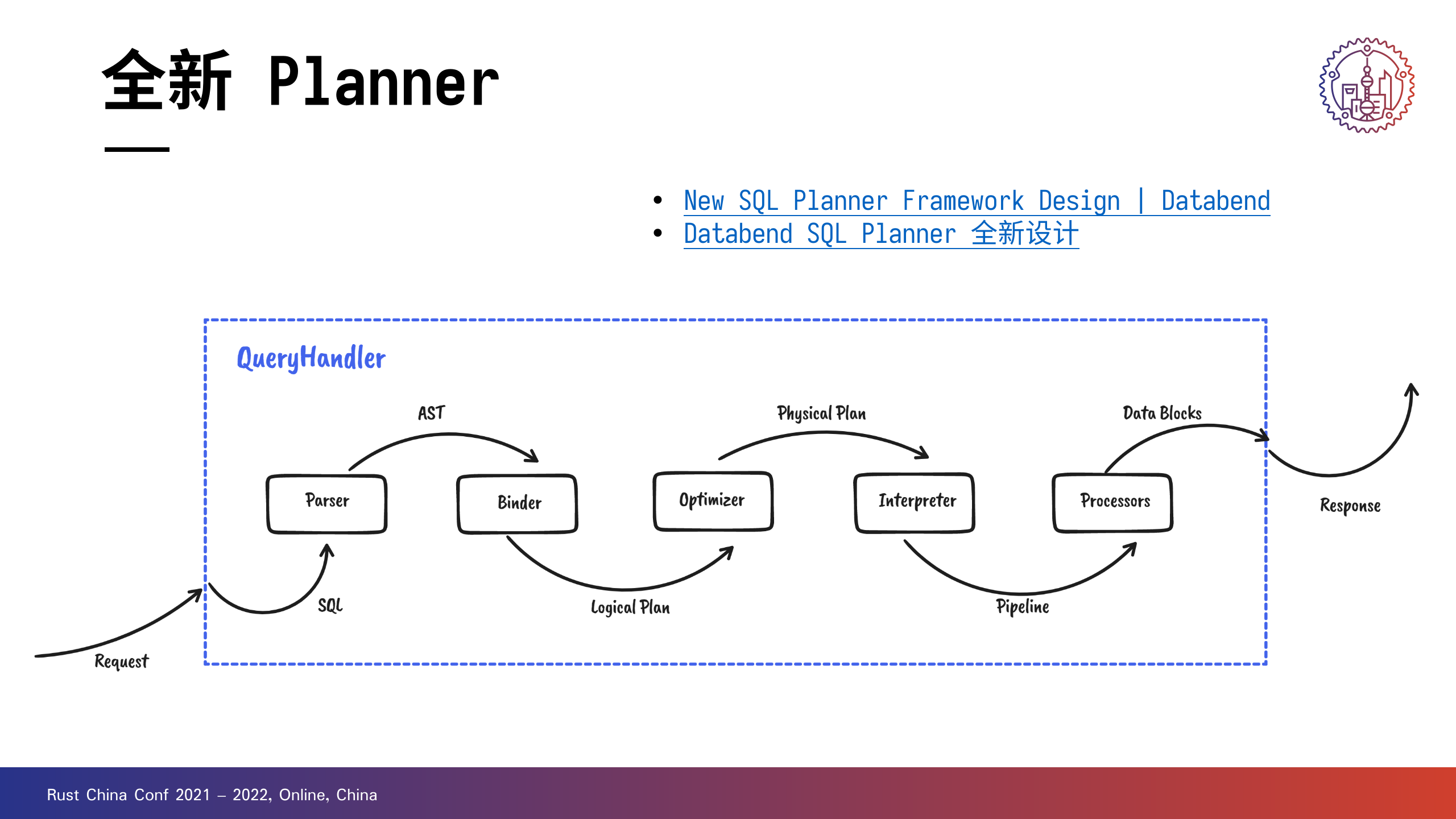
对新 plannere 感兴趣的朋友可以看一下下面列出的内容。
+ +Databend 最近正在研发一套全新的表达式框架,其中包含一套形式化的类型系统,算是使用 Rust 自定义类型系统的最佳范例。
+
通过引入形式化方法,可以提高设计的可靠性和健壮性。对应到新表达式框架中:
+一方面,引入类型检查,可以拦截 SQL 编译阶段的所有类型错误,运行时不再需要关注类型信息。
+另一方面,实现了类型安全的向下转型(downcast),得益于 Rust 的类型系统,只要函数能够正常编译就不需要担心类型转换的问题。
+当然,性能和开发体验也是新表达式框架非常关心的部分:
+通过 Enum 进行静态分发,可以减少运行时开销,降低开发难度。
+另外,在函数签名中大量使用泛型,减少手写的重载。
+图的右侧给出了一个例子:用几行代码即可定义一个快速、类型安全、自动向下转型并支持向量化的二元函数。
+如果对使用 Rust 自定义类型系统感兴趣,可以阅读下面列出的材料。我们也正在积极推进这套表达式框架的开发和迁移工作,欢迎体验。
+作为用 Rust 开发的大型项目,Databend 在一年半的迭代中也积累了一些经验,借这个机会和大家分享一下。
+Databend 选择 Rust ,其实有很多原因:极客精神、健壮性等。
+团队成员老 C 也分享了他的一个想法:
+参见:周刊(第7期):一个C系程序员的Rust初体验 - codedump的网络日志
+
这里给大家分享一下 Databend 的快速迭代方法论。
+
Databend 的单元测试组织形式有别于一般的 Rust 项目,像上图左侧展示的这样,针对性地禁用了 src 目录下的 doctest 和 test 。
+主要的优点就是节省构建测试需要的时间。
+一方面,减少遍历和检查的环节,并削减要构建的 test 目标;另一方面,如果不修改 src ,添加新单元测试时只需要编译对应的 test 目标。
+当然这样做也有缺点:不利于软件设计上的分层,需要引入编码规范并且更加依赖开发者的主动维护。
+上图右侧是 goldenfiles 的一个测试文件片段。Golden Files 测试是一种常用的测试手段,相当于是一类快照测试。我们计划大量使用它来替代手写断言。一方面变更测试文件无需重新编译,另一方面提供自动生成的办法可以减轻写测试的痛苦。
+测试相关的一些阅读材料见下:
+重构要兼顾性能和开发人员的心智负担,这里分享 Databend 代码演进的两个例子。
+eg.1
+
第一个例子是大家编写异步代码时常用的 async trait ,用起来很方便,就像左上角的例子,但是有一些小缺点:
+一是动态调度会带来开销,比较难做一些编译器的优化。 +二是内存分配也会带来开销,每次调用都需要在堆上新建一个对象。如果是经常调用的函数,就会对程序的性能造成比较大的影响。
+那么有没有解决办法呢?左下角的例子中使用泛型关联类型对它进行了改写,虽然避免了开销,但是实现起来还是相对复杂一些。
+右上角是使用 SAP 的同学作的 async-trait 分叉,只需要加一个 unboxed_simple 就可以做到同样的效果,省心省力。
eg.2
+
第二个例子是关于分发的,分发其实就是要确定调用接口时是调用哪个实例和它具体的类型。分发的方式不同,其成本也不同。
+左上角的例子是利用 trait object 动态分发,当然这会有一些开销。
+左下角使用 enum 进行静态分发,从语法上更便利。有数十倍的一个提升,但是 enum-dispatch 实现上比较硬核,基本上无法自动展开,需要自己手写规则。
+在新表达式框架中,使用 EnumAsInner 完成静态分发,代码更简洁,而且对 IDE 也更友好。
尽管 Rust 是一门健壮的语言,但程序的健壮性还需要开发者自己用心,这里分享两例完全可以避免的内存问题。
+eg.1
+
之前,上图中的代码片段没有加环境变量判断,导致程序会默认开启日志发送服务。
+但可能这个时候集群里没开对应的日志收集服务,没发的日志被 buffer 住,时间久了越攒越多,自然引发 OOM 。
+eg.2
+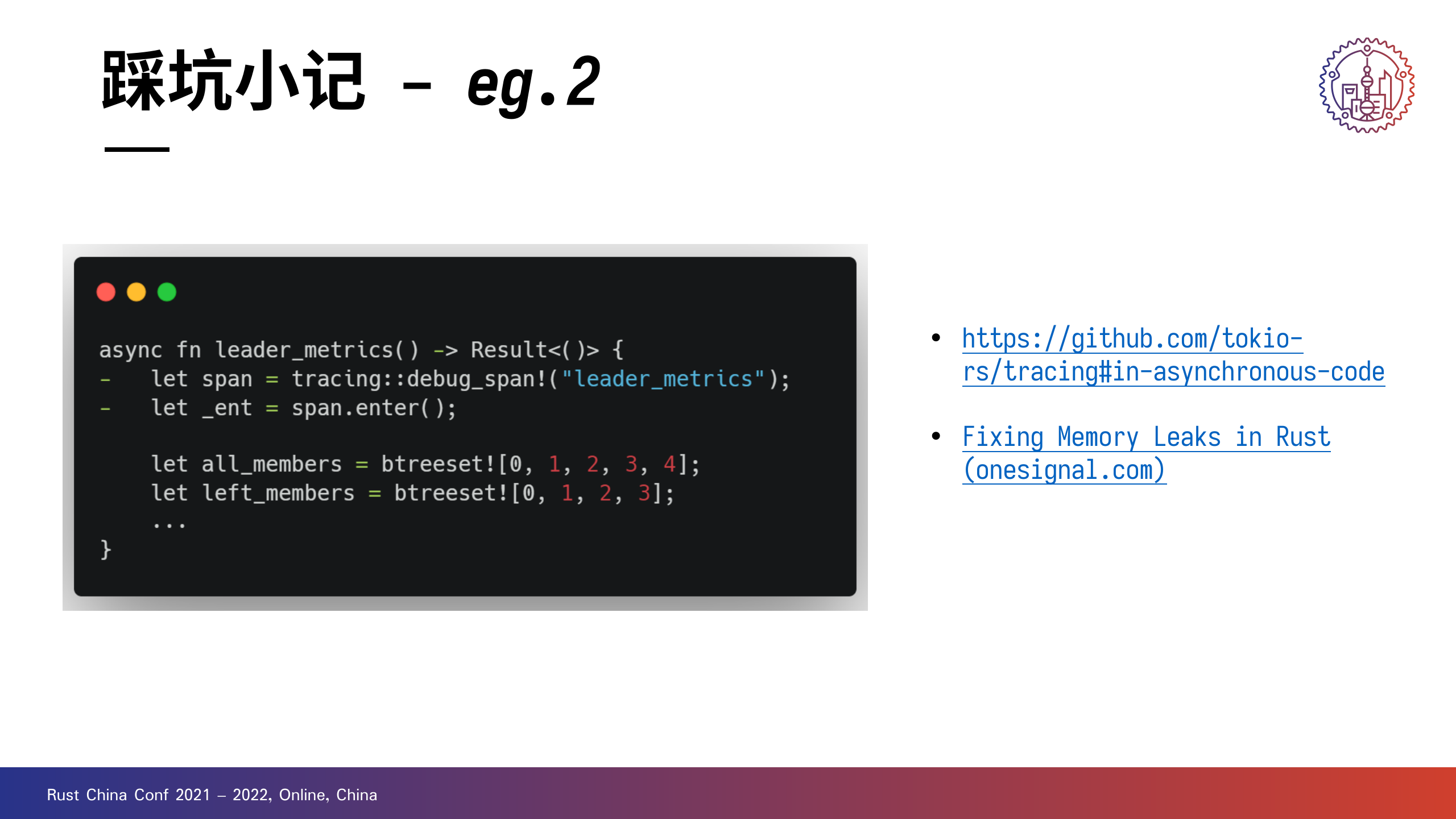
左图这个代码片段其实 tracing 的文档中已经给了提示。
+由于进入的 span 在异步执行结束后无法正确释放,会造成内存。onesignal 为此专门写了一篇文章,比较值得读。
+Databend 的成长离不开 Rust 社区和开源共同体,Databend 社区也在为共筑更好的 Rust 生态而努力。
+这里介绍三个 Databend 社区维护的开源项目。
+openraft
+https://github.com/datafuselabs/openraft
+openraft 是基于 tokio 运行时的异步共识算法实现,是披着 Raft 外壳的 Paxos,旨在成为构建下一代分布式系统的基石。
+目前已经应用在 SAP / Azure 的项目中。
+opendal
+https://github.com/datafuselabs/opendal
+opendal 的口号是:让所有人都可以无痛、高效地访问不同存储服务。
+近期的提案包括实现一个命令行工具,以操作不同服务中存储的数据,并支持数据迁移。
+opensrv
+https://github.com/datafuselabs/opensrv
+opensrv 为数据库项目提供高性能和高可度可靠的服务端协议兼容,建立在 tokio 运行时上的异步实现。目前在 CeresDB 中得到应用。
+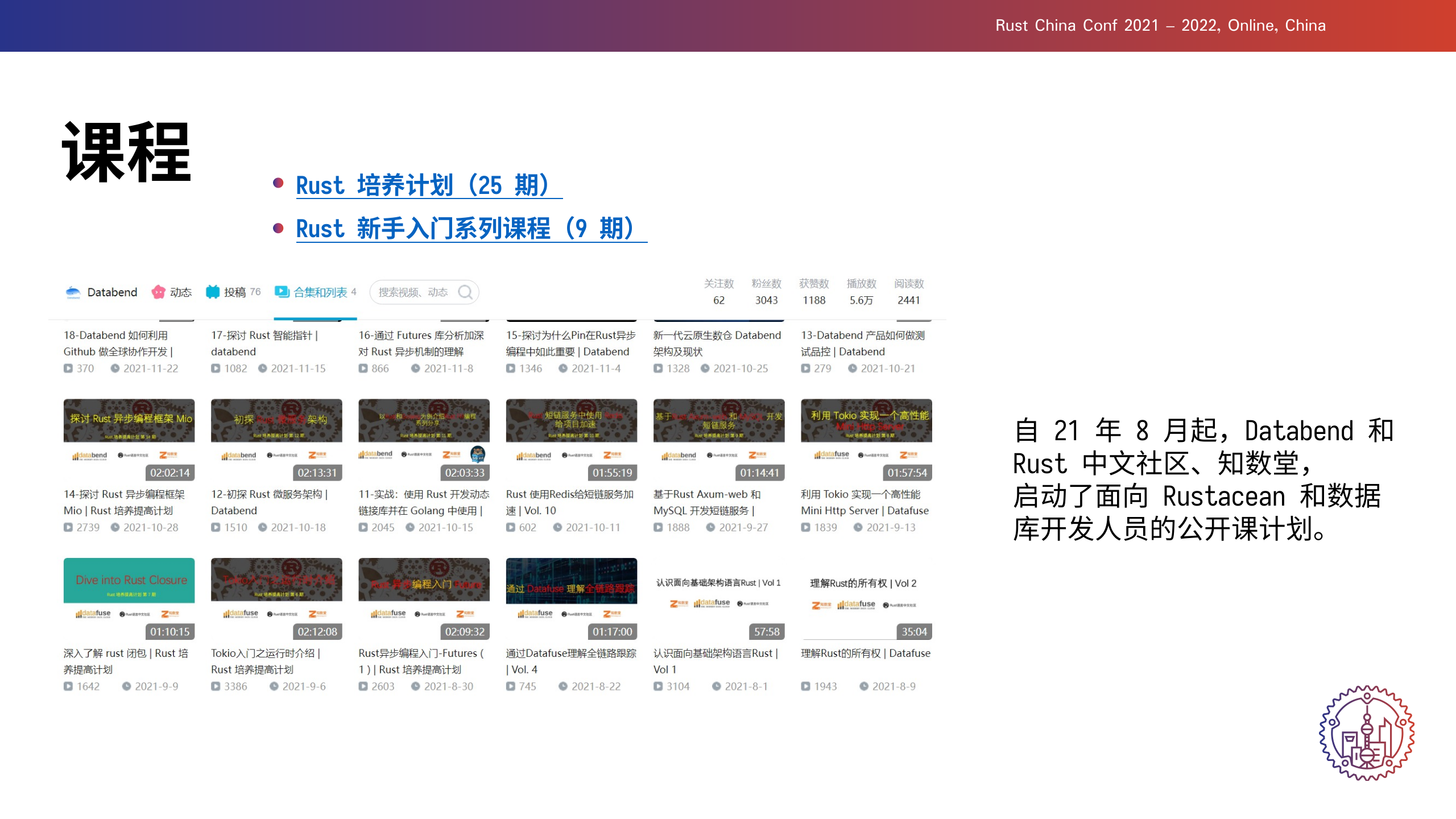
自 21 年 8 月起,Databend 和 Rust 中文社区、知数堂, +启动了面向 Rust 和数据库开发人员的公开课计划,前后一共输出 34 期课程。
+ +新一轮的公开课也在积极筹备,敬请期待。
+对待开源,Databend 一直秉承着上游优先的理念。也就是说开源协作理所当然地需要将变更反馈给社区。不光是做一个好的用户,也要做一个好的开发者。
+ +一个典型的例子是 arrow2 ,Databend 的核心依赖,我们应该是最早一批使用 arrow2 的项目。在 arrow2 的贡献者中有 9 位是 Databend Labs 成员,其中有三位是 top 15 贡献者。
+Databend 是一款云数仓,不仅仅是云原生数仓,更是云上数仓。
+
Databend Cloud 是 Databend 打造的一款易用、低成本、高性能的新一代大数据分析平台,让用户更加专注数据价值的挖掘。
+目前 Databend Cloud 正处于测试阶段,有需要的朋友可以访问 app.databend.com 注册帐号体验。
+ + + + + + + + +质量保障(Quality Assurance)用于确认产品和服务能够满足规定的质量需求。让我们一起来看一下 Databend 的质量保障实践。+
作为从 Day 1 就开源的现代云数仓,Databend 依托于 GitHub Actions 建立了一套相对完备的质量保障体系,以支撑快速迭代。
+Databend 的质量保障大概分为以下几个方面:
+流程篇
+基础篇
+测试篇
+好的流程有助于质量保障,从而持续推动 Databend 的进步。
+质量保障离不开对 Issue 的管理。Features / Bugs / Questions ,不同的分类决定了投递的形式和处理的方式。
+目前,Databend 格外关注 Bugs 类 Issue ,要求提供包括版本、报错、复现步骤并要求确认是否会提交相关的补丁。
+Databend 团队成员会检查 Issue 、沟通确认情况并进行评估。如确认存在需求,则会根据优先级和排期处理;而对于缺陷,则会及时修复并进行验证。
+周期性维护的目标是:在保证 Databend 稳定的前提下,有序推进工具链和依赖的更新。
+Databend 会在每月初进行一次集中维护:
+在无特殊需要的情况下,避免工具链和依赖版本的频繁变更,可以降低协作成本,帮助开发工作的稳定推进。
+当前 Databend 采用 nightly release 和 milestone release 结合的发布机制。每日都会发布的 nightly release 有助于日常情况的跟踪,而不定期的 milestone release 则方便进行阶段性的规划。
+Databend 的路线图由年度规划和版本计划组成,年度规划将会列出当年关注的一些主要目标,而版本计划则会根据当前的开发情况和 issue 组成进行调整。
+随着版本和路线图的不断演进,对 Databend 的质量也会有更高的要求,比如稳定性、跨版本兼容性等。
+除了测试之外,推进质量保障的一些常规手段。
+代码审计是保障 Databend 代码质量和稳定构建的第一道关口,在这一过程中,主要关注以下两个方面:
+代码审计不光是提高质量的一种手段,同时也能降低 reviewer 的负担。
+作为跨平台的 Cloud Warehouse ,确保在各个平台上的顺利编译也是质量保障的重要环节。
+Databend 的跨平台编译主要是针对 Linux(GNU) 和 MacOS 这两个平台,且完成对 x86 和 aarch64 两种体系结构的支持。额外地,在 release 阶段,也会构建针对 Linux(MUSL) 的静态编译版本。
对于日常提交,需要保证能够顺利在这些平台上完成构建。
+性能监控是质量保障中必不可少的一环,目前 Databend 主要关注:
+所有数据都会收集到 datafuselabs/databend-perf 这一 repo 中。访问 https://perf.databend.rs 即可查看可视化结果。
+测试是确保开发迭代和质量控制的重要内容。
+单元测试主要考虑基本组成单元(如:函数、过程)的正确性。
+Databend 目前共有接近 800 条单元测试,对重点函数做到了应测尽测。通过 Mock 部分全局状态,帮助开发者更加容易的编写测试用例。
+所有单元测试按 crate 进行组织,分布在对应的 tests/it 目录下,并按对应模块进行组织。这种编排方式可以减轻测试构建压力,在修改/添加新的测试时,无需重复编译对应的 lib 。
每个功能都是由若干函数/过程组成的,功能测试正是为评估功能的正确性而设立。功能测试会以 standalone 和 cluster 两种模式进行,以确保 Databend 的分布式执行功能,。
+当前 Databend 的功能测试主要由 sqllogictest 测试和 stateful 测试两个部分组成,这两类测试都可以在 tests 目录下找到。
sqllogictest 即 SQL 逻辑测试,是为了解决之前的 stateless 的一些旧有问题而专门设计实现的测试方案。RFC | New SQL Logic Test Framework 中介绍了其基本背景和方案概要。
Databend stateful 功能测试目前采用 Clickhouse 的方法,将测试所需执行的 SQL 集放入一个文件,预期结果集放入另一个文件。在测试时会调用 SQL 集生成对应的测试结果集,并与预期结果集进行对比。
上面简要介绍了 Databend 日常开发中涉及的质量保障内容,但质量保障体系仍然处于持续演进的过程中,这里列出了一些值得关注的内容:
+本文介绍了天空计算的概念和背景,以及 Databend 的跨云数据存储和访问。欢迎部署 Databend 或者访问 Databend Cloud ,即刻探索天空计算的无尽魅力。+

云计算时代的开端可以追溯到 2006 年,当时 AWS 开始提供 S3 和 EC2 服务。2013 年,云原生概念刚刚被提出,甚至还没有一个完整的愿景。时间来到 2015 年 CNCF 成立,接下来的五年中,这一概念变得越来越流行,并且成为技术人绕不开的话题。
+++根据 CNCF 对云原生的定义:云原生技术使组织能够在公共、私有和混合云这类现代、动态的环境中构建和运行可扩展的应用程序。典型示例包括:容器、服务网格、微服务、不变基础设施和声明式 API 。
+

然而,无论是公有云还是私有云、无论是云计算还是云服务,在天空中都已经存在太多不同类型的“云”。每个“云”都拥有自己独特的 API 和生态系统,并且彼此之间缺乏互操作性,能够兼容的地方也是寥寥无几。云已经成为事实上的孤岛。这个孤岛不仅仅是指公有云和私有云之间的隔阂,还包括了不同公有云之间、不同私有云之间、以及公有云和私有云之间的隔阂。这种孤岛现象不仅给用户带来了很多麻烦,也限制了云计算的发展。
+2021 年 RISELab 发表了题为 The Sky Above The Clouds 的论文,讨论关于天空计算的未来。天空计算将云原生的思想进一步扩展,从而囊括公有云、私有云和边缘设备。其目标是实现一种统一的 API 和生态体系,使得不同云之间可以无缝地协作和交互。这样一来,用户就可以在不同的云之间自由地迁移应用程序和数据,而不必担心兼容性和迁移成本的问题。同时,天空计算还可以提供更高效、更安全、更可靠的计算服务,从而满足用户对于云计算的不断增长的需求。总体上讲,天空计算致力于允许应用跨多个云厂商运行,实现多云之间的互操作性。
+
(上图引自论文,展示不同类型的多云与天空的区别)
+Databend 能够满足用户在不同的云之间自由地访问数据并进行查询,而不必担心兼容性和迁移成本的问题。同时,Databend 还可以提供更高效、更安全、更可靠的计算服务,从而满足用户对于云计算的不断增长的需求。从这个角度来看,Databend 已经初步形成了一套天空计算的解决方案。那么,对 Databend 而言,跨云的关键到底落在哪里呢?
+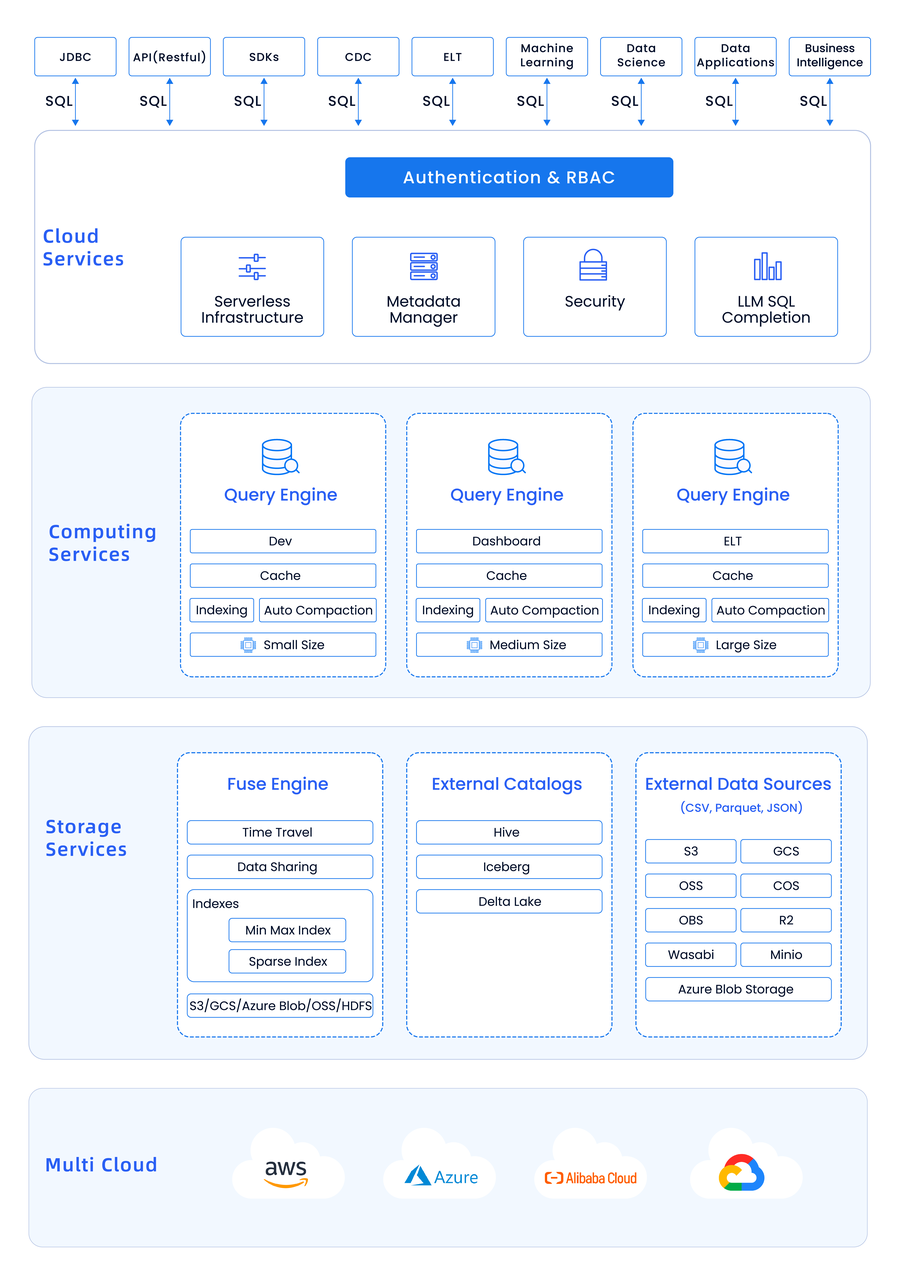
(上图所示为 Databend Cloud 架构示意图)
+Databend 采用存算分离的架构,并完全面向云对象存储进行设计决策。得益于存储与计算分离、存储与状态分离,Databend 可以实现对资源的精细化控制,轻松部署与扩展 Query 和 Meta 节点 ,并支持多种不同的计算场景和存储场景,而无需考虑跨云数据管理与移动的问题。
+Query 节点和 Meta 节点本身都是轻量化的服务,并且对于部署环境没有严格的依赖。但数据的存储和访问管理就不一样,我们需要考虑不同云服务之间的 API 兼容性、以及如何与云服务本身的安全机制交互从而提供更安全的访问控制机制。对于 Databend 而言,跨云,或者说实现天空计算的关键,就落在数据的管理与访问之上。
+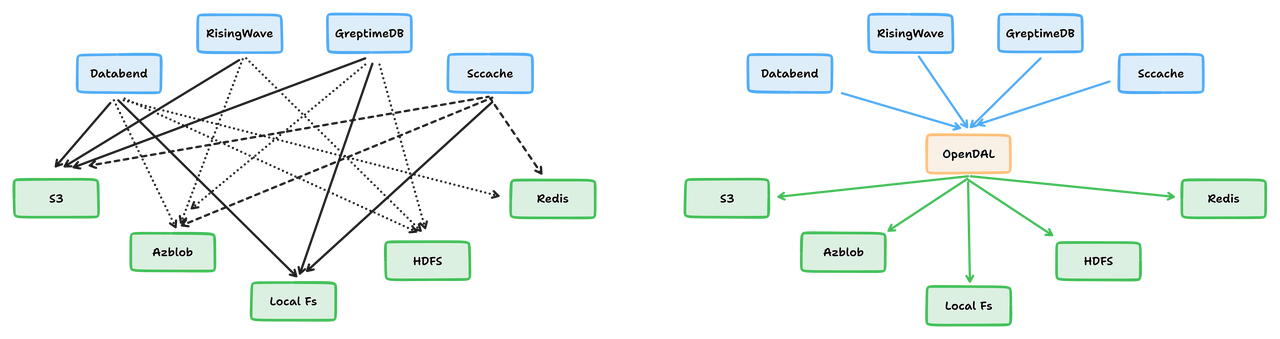
(OpenDAL 可以将数据访问问题从 M*N 转化为 M+N)
+为了解决这一问题,Databend 抽象出一套统一的数据访问层(OpenDAL,现在是 Apache 软件基金会旗下的孵化项目),从而屏蔽了不同云服务之间的 API 兼容性问题。在接下来的部分,我们将会从不同的视角来观察 Databend 的无痛数据访问体验,体验真正完全云原生的天空计算的魅力。
+Databend 存储后端的细节隐藏在简单的配置之下,通过修改配置文件就可以轻松地在十数种存储服务之间切换。例如,如果你想使用 AWS S3,只需要指定类型为 s3 即可,Databend 会自动尝试使用 IAM 来进行认证。如果你想使用其他与 S3 兼容的对象存储服务,也可以通过 endpoint_url 等设置来调整。
[storage]
+type = "s3"
+
+[storage.s3]
+bucket = "databend"
+当然,仅支持 S3 兼容的对象存储服务还不够。Databend 通过 OpenDAL 实现了 Google Cloud Storage、Azure Blob、Aliyun OSS、Huawei OBS 和 HDFS 等服务的原生存储后端支持。 +这意味着 Databend 可以充分利用各种供应商提供的 API,为用户带来更优秀的体验。例如,Aliyun OSS 的原生支持使得 Databend 可以通过 Aliyun RAM 对用户进行认证和授权,无需设置静态密钥,从而大大提高安全性并降低运维负担。
+
(上图选自阿里云官网,访问控制场景与能力)
+此外,原生支持还可以避免出现非预期行为,并与服务供应商提供更紧密的集成。虽然各大厂商都提供了 S3 兼容 API,但它们之间存在微妙差异,在出现非预期行为时可能会导致服务性能下降或读写数据功能异常。Google Cloud Storage 提供了 S3 兼容的 XML API,但却没有支持批量删除对象的功能。这导致用户在调用该接口时遇到意外错误。而 Google Cloud Storage 的原生支持使 Databend 不必担心 GCS 对 S3 的兼容实现问题对用户业务造成影响。
+总之,Databend 通过为各个服务实现原生支持来为用户提供高效可靠的数据分析服务。
+前面讲过了存储后端的跨云支持,现在让我们将目光聚焦到数据的管理。更具体来说,数据在 Databend 工作流中的流入与流出。
+要讲数据管理,就不得不讨论数据从哪里来。过去可能还需要考虑是否需要迁移存储服务,但现在,你可以从数十种 Databend 支持或兼容的存储服务中加载数据,一切都显得那么自然。
+COPY INTO 语句是窥探 Databend 跨云能力的一个窗口,下面的示例展示了如何从 Azure Blob 加载数据到 Databend 之中。
COPY INTO mytable
+ FROM 'azblob://mybucket/data.csv'
+ CONNECTION = (
+ ENDPOINT_URL = 'https://<account_name>.blob.core.windows.net'
+ ACCOUNT_NAME = '<account_name>'
+ ACCOUNT_KEY = '<account_key>'
+ )
+ FILE_FORMAT = (type = CSV);
+当然,不止是 Azure Blob ,Databend 支持的其他云对象存储服务、IPFS 以及可以经由 HTTPS 访问的文件都可以作为 External location ,通过 COPY INTO 语句加载进来。
++Databend 的
+COPY INTO语句还支持进行基本的转换服务,可以减轻 ETL 工作的负担。
刚刚提到 External location ,事实上,要加载到 Databend 中的数据文件还可以在 Stage 中暂存。Databend 同样支持 Internal stage 和 Named external stage 。
+数据文件可以经由 PUT_INTO_STAGE API 上传到 Internal Stage,由 Databend 交付当前配置的存储后端进行统一管理。而 Named external stage 则可以用于挂载其他 Databend 支持的多种存储服务之中的 bucket 。
下面的例子展示了如何在 Databend 中创建一个名为 whdfs 的 Stage ,通过 WebHDFS 协议将 HDFS 中 data-files 目录下的数据文件导入 Databend 。
+bendsql> CREATE STAGE IF NOT EXISTS whdfs URL='webhdfs://127.0.0.1:9870/data-files/' CONNECTION=(HTTPS='false');
+Query OK, 0 rows affected (0.01 sec)
+
+bendsql> COPY INTO books FROM @whdfs FILES=('books.csv') file_format=(type=CSV field_delimiter=',' record_delimiter='\n' skip_header=0);
+Query OK, 2 rows affected (1.83 sec)
+++如果你并不想直接导入数据,也可以尝试
+SELECT FROM STAGE,快速分析位于暂存区中的数据文件。
放在对象存储中的数据加载得到了解决,还有一个值得思考的问题是,如果数据原本由其他数据分析系统所管理,该怎么办?
+Databend 提供多源数据目录(Multiple Catalog)的支持,允许挂载 Hive 、Iceberg 等外部数据目录。
+下面的示例展示如何利用配置文件挂载 Hive 数据目录。
+[catalogs.hive]
+type = "hive"
+# hive metastore address, such as 127.0.0.1:9083
+address = "<hive-metastore-address>"
+除了挂载,查询也是小菜一碟 select * from hive.$db.$table limit 10; 。
当然,这一切也可以通过 CREATE CATALOG 语句轻松搞定,下面的例子展示了如何挂载 Iceberg 数据目录。
CREATE CATALOG iceberg_ctl
+ TYPE=ICEBERG
+ CONNECTION=(
+ URL="s3://my_bucket/path/to/db"
+ AWS_KEY_ID="<access-key>"
+ AWS_SECRET_KEY="<secret_key>"
+ SESSION_TOKEN="<session_token>"
+ );
+++Multiple Catalog 相关的能力还在积极开发迭代中,感兴趣的话可以保持关注。
+
数据导出是数据管理中的另外一个重要话题,简单来讲,就是转储查询结果以供进一步的分析和处理。
+这一能力同样由 COPY INTO 语法提供支持,当然,同样支持数十种存储服务和多种文件输出格式。下面的示例展示了如何将查询结果以 CSV 格式文件的形式导出到指定 Stage 中。
-- Unload the data from a query into a CSV file on the stage
+COPY INTO @s2 FROM (SELECT name, age, id FROM test_table LIMIT 100) FILE_FORMAT = (TYPE = CSV);
+这一语法同样支持导出到 External location ,真正做到数据的自由流动。
+++Databend 还支持
+PRESIGN,用来为 Stage 中的文件生成预签名的 URL ,用户可以通过 Web 浏览器或 API 请求自由访问该文件。
刚才提到的 Databend 数据管理环节跨云主要是指 Databend 与外部服务之间的交互。此外,Databend 实例之间也可以经由多种云存储服务来支持数据共享。
+为了更好地满足多云环境下的数据库查询需求,Databend 设计并实现了一套 RESTful API 来支持数据共享。
+
(上图所示为数据共享的工作流)
+通过在配置文件中添加 share_endpoint_address 相关配置,用户可以利用预先部署好的 open-sharing 服务,经由熟悉的云存储服务共享 Databend 管理的数据库或表。
CREATE SHARE myshare;
+GRANT USAGE ON DATABASE db1 TO SHARE myshare;
+GRANT SELECT ON TABLE db1.table1 TO SHARE myshare;
+ALTER SHARE myshare ADD TENANTS = vendor;
+此时,表 db1.table1 将对接受方租户 vendor 可见,并能够进行必要的查询。
CREATE DATABASE db2 FROM SHARE myshare;
+SELECT * FROM db2.table1;
+上面的几个视角,只是展示 Databend 在天空计算道路上的一个小小侧影。
+数据合规、隐私保护等内容同样是我们所关心的重要议题。
+Databend 的愿景是成为未来跨云分析的基石,让数据分析变得更加简单、快速、便捷和智能。
+本文介绍了天空计算的概念和背景,以及 Databend 的跨云数据存储和访问。
+天空计算是一种将公有云、私有云和边缘设备统一起来的方法,目标是提供一种无缝的 API 和生态体系,使得用户可以在不同的云之间自由地迁移应用程序和数据。
+Databend 是一个开源的、完全面向云架构的新式数仓,它采用存算分离的架构,并抽象出一套统一的数据访问层(OpenDAL),从而屏蔽了不同云服务之间的 API 兼容性问题。Databend 可以满足用户在不同的云之间自由地访问数据并进行查询,而不必担心兼容性和迁移成本的问题。同时,Databend 还可以提供更高效、更安全、更可靠的计算服务,从而满足用户对于云计算的不断增长的需求。
+欢迎部署 Databend 或者访问 Databend Cloud ,即刻探索天空计算的无尽魅力。
+ + + + + + + + +对于 Databend 这样复杂的数据库服务端程序,往往需要支持大量的可配置选项,以帮助运维人员根据实际使用需要管理和调优系统。
+Databend 目前支持三种配置方式:命令行、环境变量和配置文件,优先级依次递减。
+对于 databend-query ,不管是什么形式的配置,其配置选项几乎可以看作是代码的扁平化树形映射,即基本符合代码中「配置域」+「配置项」的逻辑。
serfig 将代码嵌套展开,使用 _ 做为分隔符。-;另一方面,部分命令行选项的名称中没有绑定配置域。为了更好理解这里的映射关系,我们可以深入到具体一项配置,下面将围绕 admin_api_address 这个配置项展开。
在环境变量上,需要使用 QUERY_ADMIN_API_ADDRESS ,QUERY 表征这个配置所处的域,而 ADMIN_API_ADDRESS 是具体的配置项。
在配置文件中,通常是使用 toml 来进行配置。 [query] 表征配置所处的域,admin_api_address 为具体的配置项。
[query]
+...
+# Databend Query http address.
+# For admin RESET API.
+admin_api_address = "0.0.0.0:8081"
+...
+命令行中需要使用 --admin-api-address 进行配置,这一项没有绑定「配置域」。如果是配置 --storage-s3-access-key-id ,那么「storage」+ 「s3」构成配置域,「access-key-id」是具体的配置项。
在了解如何对 admin_api_address 进行配置后,让我们进入到配置相关的代码,进一步查看映射关系的代码形式(位于 src/query/config/src/config.rs)。
pub struct Config {
+ ...
+
+ // Query engine config.
+ #[clap(flatten)]
+ pub query: QueryConfig,
+
+ ...
+}
+
+/// Query config group.
+#[derive(Clone, Debug, PartialEq, Eq, Serialize, Deserialize, Args)]
+#[serde(default, deny_unknown_fields)]
+pub struct QueryConfig {
+ ...
+
+ #[clap(long, default_value = "127.0.0.1:8080")]
+ pub admin_api_address: String,
+
+ ...
+}
+因为代码中使用了嵌套的层级结构,最上层是 Config,而 admin_api_address 是 pub query: QueryConfig 中的一个配置项,经过 serfig 处理后,需要使用 QUERY 或者 [query] 表征其所处的域,配置项就还是 admin_api_address 。
而命令行中具体的配置项名称和默认值会受到 #[clap(long = "<long-name>", default_value = "<value>")] 控制),clap 会接管配置:
admin_api_address 就变成了 --admin-api-address。--storage-s3-access-key-id 而言,其实际的代码层级是 Config -> StorageConfig -> S3StorageConfig -> access_key_id,字段之上有标注 #[clap(long = "storage-s3-access-key-id", default_value_t)] ,所以需要使用 --storage-s3-access-key-id 进行配置。databend-meta 的配置文件和命令行逻辑与 databend-query 是基本一致的。但是环境变量是通过 serfig 内置的 serde-env 自行定义的映射关系(但同样可以尝试按「配置域」+「配置项」进行理解)。
同样具体到单独的某项配置来看一下,这里以 log_dir 为例。
在环境变量上,需要使用 METASRV_LOG_DIR ,METASRV 表征这个配置所处的域,而 LOG_DIR 是具体的配置项。
而在配置文件中,这一配置项作用于全局,只需要:
+log_dir = "./.databend/logs1"
+在命令行中当然也直接 --log-dir 进行配置。
让我们通过代码来解构其映射,代码位于 src/meta/service/src/configs/outer_v0.rs。
#[derive(Clone, Debug, Serialize, Deserialize, PartialEq, Eq, Parser)]
+#[clap(about, version = &**METASRV_COMMIT_VERSION, author)]
+#[serde(default)]
+pub struct Config {
+ ...
+ /// Log file dir
+ #[clap(long = "log-dir", default_value = "./.databend/logs")]
+ pub log_dir: String,
+ ...
+}
+配置文件和命令行参数相关的配置项是由 Config 结构体管理的,逻辑与 databend-query 一致,就不再赘述。
而环境变量的配置项是由 ConfigViaEnv 结构体进行处理的,如下:
/// #[serde(flatten)] doesn't work correctly for env.
+/// We should work around it by flatten them manually.
+/// We are seeking for better solutions.
+#[derive(Clone, Debug, Serialize, Deserialize, PartialEq, Eq)]
+#[serde(default)]
+pub struct ConfigViaEnv {
+ ...
+ pub metasrv_log_dir: String,
+ ...
+}
+与 Config 之间的映射关系位于 impl From<Config> for ConfigViaEnv 和 impl Into<Config> for ConfigViaEnv 这两个部分。对于 metasrv_log_dir 而言,就是映射到前面的 log_dir 字段。
作者:AriesDevil | Databend Labs 成员,数据库研发工程师
+Databend Query Server 的启动入口在 databend/src/binaries/query/main.rs 下,在初始化配置之后,它会创建一个 GlobalServices 和 server 关闭时负责处理 shutdown 逻辑的 shutdown_handle 。
GlobalServices::init(conf.clone()).await?;
+let mut shutdown_handle = ShutdownHandle::create()?;
+GlobalServices 负责启动 databend-query 的所有全局服务,这些服务都遵循单一责任原则。
pub struct GlobalServices {
+ global_runtime: UnsafeCell<Option<Arc<Runtime>>>,
+ // 负责处理 query log
+ query_logger: UnsafeCell<Option<Arc<QueryLogger>>>,
+ // 负责 databend query 集群发现
+ cluster_discovery: UnsafeCell<Option<Arc<ClusterDiscovery>>>,
+ // 负责与 storage 层交互来读写数据
+ storage_operator: UnsafeCell<Option<Operator>>,
+ async_insert_manager: UnsafeCell<Option<Arc<AsyncInsertManager>>>,
+ cache_manager: UnsafeCell<Option<Arc<CacheManager>>>,
+ catalog_manager: UnsafeCell<Option<Arc<CatalogManager>>>,
+ http_query_manager: UnsafeCell<Option<Arc<HttpQueryManager>>>,
+ data_exchange_manager: UnsafeCell<Option<Arc<DataExchangeManager>>>,
+ session_manager: UnsafeCell<Option<Arc<SessionManager>>>,
+ users_manager: UnsafeCell<Option<Arc<UserApiProvider>>>,
+ users_role_manager: UnsafeCell<Option<Arc<RoleCacheManager>>>,
+}
+GlobalServices 中的全局服务都实现了单例 trait,这些全局管理器后续会有对应的源码分析文章介绍,本文介绍与 Session 处理相关的逻辑。
+pub trait SingletonImpl<T>: Send + Sync {
+ fn get(&self) -> T;
+
+ fn init(&self, value: T) -> Result<()>;
+}
+
+pub type Singleton<T> = Arc<dyn SingletonImpl<T>>;
+接下来会根据网络协议初始化 handlers,并把它们注册到 shutdown_handler 的 services 中,任何实现 Server trait 的类型都可以被添加到 services 中。
#[async_trait::async_trait]
+pub trait Server: Send {
+ async fn shutdown(&mut self, graceful: bool);
+ async fn start(&mut self, listening: SocketAddr) -> Result<SocketAddr>;
+}
+目前 Databend 支持三种协议提交查询请求:MySql, ClickHouse HTTP, Raw HTTP 。
+// MySQL handler.
+{
+ let hostname = conf.query.mysql_handler_host.clone();
+ let listening = format!("{}:{}", hostname, conf.query.mysql_handler_port);
+ let mut handler = MySQLHandler::create(session_manager.clone());
+ let listening = handler.start(listening.parse()?).await?;
+ // 注册服务到 shutdown_handle 来处理 server shutdown 时候的关闭逻辑,下同
+ shutdown_handle.add_service(handler);
+}
+
+// ClickHouse HTTP handler.
+{
+ let hostname = conf.query.clickhouse_http_handler_host.clone();
+ let listening = format!("{}:{}", hostname, conf.query.clickhouse_http_handler_port);
+
+ let mut srv = HttpHandler::create(session_manager.clone(), HttpHandlerKind::Clickhouse);
+ let listening = srv.start(listening.parse()?).await?;
+ shutdown_handle.add_service(srv);
+}
+
+// Databend HTTP handler.
+{
+ let hostname = conf.query.http_handler_host.clone();
+ let listening = format!("{}:{}", hostname, conf.query.http_handler_port);
+
+ let mut srv = HttpHandler::create(session_manager.clone(), HttpHandlerKind::Query);
+ let listening = srv.start(listening.parse()?).await?;
+ shutdown_handle.add_service(srv);
+}
+之后会创建一些其它服务:
+// Metric API service.
+{
+ let address = conf.query.metric_api_address.clone();
+ let mut srv = MetricService::create(session_manager.clone());
+ let listening = srv.start(address.parse()?).await?;
+ shutdown_handle.add_service(srv);
+ info!("Listening for Metric API: {}/metrics", listening);
+}
+
+// Admin HTTP API service.
+{
+ let address = conf.query.admin_api_address.clone();
+ let mut srv = HttpService::create(session_manager.clone());
+ let listening = srv.start(address.parse()?).await?;
+ shutdown_handle.add_service(srv);
+ info!("Listening for Admin HTTP API: {}", listening);
+}
+
+// RPC API service.
+{
+ let address = conf.query.flight_api_address.clone();
+ let mut srv = RpcService::create(session_manager.clone());
+ let listening = srv.start(address.parse()?).await?;
+ shutdown_handle.add_service(srv);
+ info!("Listening for RPC API (interserver): {}", listening);
+}
+最后会将这个 query 节点注册到 meta server 中。
+// Cluster register.
+{
+ let cluster_discovery = session_manager.get_cluster_discovery();
+ let register_to_metastore = cluster_discovery.register_to_metastore(&conf);
+ register_to_metastore.await?;
+}
+session 主要分为 4 个部分:
session_manager :全局唯一,负责管理 client session 。session :每当有新的 client 连接到 server 之后会创建一个新的 session 并且注册到 session_manager 。query_ctx :每一条查询语句会有一个 query_ctx,用来存储当前查询的一些上下文信息 。query_ctx_shared :查询语句中的子查询共享的上下文信息 。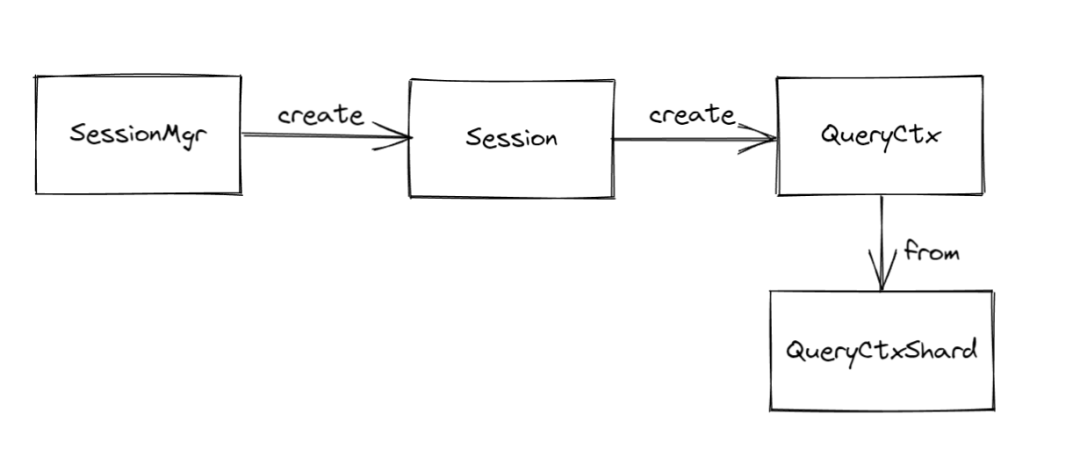
下面逐一来分析。
+代码位置:query/src/sessions/session_mgr.rs 。
pub struct SessionManager {
+ pub(in crate::sessions) conf: Config,
+ pub(in crate::sessions) max_sessions: usize,
+ pub(in crate::sessions) active_sessions: Arc<RwLock<HashMap<String, Arc<Session>>>>,
+ pub status: Arc<RwLock<SessionManagerStatus>>,
+
+ // When session type is MySQL, insert into this map, key is id, val is MySQL connection id.
+ pub(crate) mysql_conn_map: Arc<RwLock<HashMap<Option<u32>, String>>>,
+ pub(in crate::sessions) mysql_basic_conn_id: AtomicU32,
+}
+SessionManager 主要用来创建和销毁 session,对应方法如下:
// 根据 client 协议类型来创建 session
+pub async fn create_session(self: &Arc<Self>, typ: SessionType) -> Result<SessionRef>
+
+// 根据 session id 来销毁 session
+pub fn destroy_session(self: &Arc<Self>, session_id: &String)
+代码位置:query/src/sessions/session.rs 。
session 主要存储 client-server 的上下文信息,代码命名已经很清晰了,这里就不再过多赘述。
+pub struct Session {
+ pub(in crate::sessions) id: String,
+ pub(in crate::sessions) typ: RwLock<SessionType>,
+ pub(in crate::sessions) session_ctx: Arc<SessionContext>,
+ status: Arc<RwLock<SessionStatus>>,
+ pub(in crate::sessions) mysql_connection_id: Option<u32>,
+}
+
+pub struct SessionContext {
+ conf: Config,
+ abort: AtomicBool,
+ current_catalog: RwLock<String>,
+ current_database: RwLock<String>,
+ current_tenant: RwLock<String>,
+ current_user: RwLock<Option<UserInfo>>,
+ auth_role: RwLock<Option<String>>,
+ client_host: RwLock<Option<SocketAddr>>,
+ io_shutdown_tx: RwLock<Option<Sender<Sender<()>>>>,
+ query_context_shared: RwLock<Option<Arc<QueryContextShared>>>,
+}
+
+pub struct SessionStatus {
+ pub session_started_at: Instant,
+ pub last_query_finished_at: Option<Instant>,
+}
+Session 的另一个大的功能是负责创建和获取 QueryContext,每次接收到新的 query 请求都会创建一个 QueryContext 并绑定在对应的 query 语句上。
+代码位置:query/src/sessions/query_ctx.rs 。
QueryContext 主要是维护查询的上下文信息,它通过 QueryContext::create_from_shared (query_ctx_shared) 创建。
#[derive(Clone)]
+pub struct QueryContext {
+ version: String,
+ statistics: Arc<RwLock<Statistics>>,
+ partition_queue: Arc<RwLock<VecDeque<PartInfoPtr>>>,
+ shared: Arc<QueryContextShared>,
+ precommit_blocks: Arc<RwLock<Vec<DataBlock>>>,
+ fragment_id: Arc<AtomicUsize>,
+}
+其中 partition_queue 主要存储查询对应的 PartInfo,包括 part 的地址、版本信息、涉及数据的行数,part 使用的压缩算法、以及涉及到 column 的 meta 信息。在 pipeline build 时候会去设置 partition 。pipeline 后续会有专门的文章介绍。
precommit_blocks 负责暂存插入操作的时已经写入到存储, 但是尚未提交的元数据,DataBlock 主要包含 Column 的元信息引用和 arrow schema 的信息。
代码位置:query/src/sessions/query_ctx_shared.rs 。
对于包含子查询的查询,需要共享很多上下文信息,这就是 QueryContextShared 存在的理由。
/// 数据需要在查询上下文中被共享,这个很重要,比如:
+/// USE database_1;
+/// SELECT
+/// (SELECT scalar FROM table_name_1) AS scalar_1,
+/// (SELECT scalar FROM table_name_2) AS scalar_2,
+/// (SELECT scalar FROM table_name_3) AS scalar_3
+/// FROM table_name_4;
+/// 对于上面子查询, 会共享 runtime, session, progress, init_query_id
+pub struct QueryContextShared {
+ /// scan_progress for scan metrics of datablocks (uncompressed)
+ pub(in crate::sessions) scan_progress: Arc<Progress>,
+ /// write_progress for write/commit metrics of datablocks (uncompressed)
+ pub(in crate::sessions) write_progress: Arc<Progress>,
+ /// result_progress for metrics of result datablocks (uncompressed)
+ pub(in crate::sessions) result_progress: Arc<Progress>,
+ pub(in crate::sessions) error: Arc<Mutex<Option<ErrorCode>>>,
+ pub(in crate::sessions) session: Arc<Session>,
+ pub(in crate::sessions) runtime: Arc<RwLock<Option<Arc<Runtime>>>>,
+ pub(in crate::sessions) init_query_id: Arc<RwLock<String>>,
+ ...
+}
+它提供了 query 上下文所需要的一切基本信息。
+之前提到了 Databend 支持多种 handler,下面就以 mysql 为例,看一下 handler 的处理流程以及如何与 session 产生交互。
+首先 MySQLHandler 会包含一个 SessionManager 的引用。
pub struct MySQLHandler {
+ abort_handle: AbortHandle,
+ abort_registration: Option<AbortRegistration>,
+ join_handle: Option<JoinHandle<()>>,
+}
+MySQLHandler 在启动后,会 spawn 一个 tokio task 来持续监听 tcp stream,并且创建一个 session 再启动一个 task 去执行之后的查询请求。
fn accept_socket(session_mgr: Arc<SessionManager>, executor: Arc<Runtime>, socket: TcpStream) {
+ executor.spawn(async move {
+ // 创建 session
+ match session_mgr.create_session(SessionType::MySQL).await {
+ Err(error) => Self::reject_session(socket, error).await,
+ Ok(session) => {
+ info!("MySQL connection coming: {:?}", socket.peer_addr());
+ // 执行查询
+ if let Err(error) = MySQLConnection::run_on_stream(session, socket) {
+ error!("Unexpected error occurred during query: {:?}", error);
+ };
+ }
+ }
+ });
+}
+在 MySQLConnection::run_on_stream 中,session 会先 attach 到对应的 client host 并且注册一个 shutdown 闭包来处理关闭连接关闭时需要执行的清理,关键代码如下:
// mysql_session.rs
+pub fn run_on_stream(session: SessionRef, stream: TcpStream) -> Result<()> {
+ let blocking_stream = Self::convert_stream(stream)?;
+ MySQLConnection::attach_session(&session, &blocking_stream)?;
+
+ ...
+}
+
+fn attach_session(session: &SessionRef, blocking_stream: &std::net::TcpStream) -> Result<()> {
+ let host = blocking_stream.peer_addr().ok();
+ let blocking_stream_ref = blocking_stream.try_clone()?;
+ session.attach(host, move || {
+ // 注册 shutdown 逻辑
+ if let Err(error) = blocking_stream_ref.shutdown(Shutdown::Both) {
+ error!("Cannot shutdown MySQL session io {}", error);
+ }
+ });
+
+ Ok(())
+}
+
+// session.rs
+pub fn attach<F>(self: &Arc<Self>, host: Option<SocketAddr>, io_shutdown: F)
+where F: FnOnce() + Send + 'static {
+ let (tx, rx) = oneshot::channel();
+ self.session_ctx.set_client_host(host);
+ self.session_ctx.set_io_shutdown_tx(Some(tx));
+
+ common_base::base::tokio::spawn(async move {
+ // 在 session quit 时候触发清理
+ if let Ok(tx) = rx.await {
+ (io_shutdown)();
+ tx.send(()).ok();
+ }
+ });
+}
+之后会启动一个 MySQL InteractiveWorker 来处理后续的查询。
+let join_handle = query_executor.spawn(async move {
+ let client_addr = non_blocking_stream.peer_addr().unwrap().to_string();
+ let interactive_worker = InteractiveWorker::create(session, client_addr);
+ let opts = IntermediaryOptions {
+ process_use_statement_on_query: true,
+ };
+ let (r, w) = non_blocking_stream.into_split();
+ let w = BufWriter::with_capacity(DEFAULT_RESULT_SET_WRITE_BUFFER_SIZE, w);
+ AsyncMysqlIntermediary::run_with_options(interactive_worker, r, w, &opts).await
+});
+let _ = futures::executor::block_on(join_handle);
+该 InteractiveWorker 会实现 AsyncMysqlShim trait 的方法,比如:on_execute 、on_query 等。查询到来时会回调这些方法来执行查询。
这里以 on_query 为例,关键代码如下:
async fn on_query<'a>(
+ &'a mut self,
+ query: &'a str,
+ writer: QueryResultWriter<'a, W>,
+) -> Result<()> {
+ ...
+
+ // response writer
+ let mut writer = DFQueryResultWriter::create(writer);
+
+ let instant = Instant::now();
+ // 执行查询
+ let blocks = self.base.do_query(query).await;
+
+ // 回写结果
+ let format = self.base.session.get_format_settings()?;
+ let mut write_result = writer.write(blocks, &format);
+
+ ...
+
+ // metrics 信息
+ histogram!(
+ super::mysql_metrics::METRIC_MYSQL_PROCESSOR_REQUEST_DURATION,
+ instant.elapsed()
+ );
+
+ write_result
+}
+在 do_query 中会创建 QueryContext 并开始解析 sql 流程来完成后续的整个 sql 查询。关键代码如下:
// 创建 QueryContext
+let context = self.session.create_query_context().await?;
+// 关联到查询语句
+context.attach_query_str(query);
+
+let settings = context.get_settings();
+
+// parse sql
+let stmts_hints = DfParser::parse_sql(query, context.get_current_session().get_type());
+...
+
+// 创建并生成查询计划
+let mut planner = Planner::new(context.clone());
+let interpreter = planner.plan_sql(query).await.and_then(|v| {
+ has_result_set = has_result_set_by_plan(&v.0);
+ InterpreterFactoryV2::get(context.clone(), &v.0)
+})
+
+// 执行查询,返回结果
+Self::exec_query(interpreter.clone(), &context).await?;
+let schema = interpreter.schema();
+Ok(QueryResult::create(
+ blocks,
+ extra_info,
+ has_result_set,
+ schema,
+))
+以上就是从 Databend 启动服务到接受 SQL 请求并开始处理的流程。最近我们因为一些原因(ClickHouse TCP 协议偏向 ClickHouse 的底层,协议没有公开的文档说明,同时里面历史包袱比较重,排查问题浪费大量精力)去掉了 ClickHouse Native TCP Client,具体请参见: https://github.com/datafuselabs/databend/pull/7012
+如果你阅读完代码有好的提议,欢迎来这里讨论,另外如果发现相关的问题,可以提交到 issue 来帮助我们提高 Databend 的稳定性。Databend 社区欢迎一切善意的意见和建议 :)
+ + + + + + + + +作者:sundy-li | Databend Labs 成员,折腾过 Clickhouse
+Databend 在 2021 年开源后,陆续受到了很多社区同学的关注。Databend 使用了 Rust 编程语言。为了吸引更多的开发者,特别是没有 Rust 开发经验的新同志,我们设计了 Rust 相关课程,同时建立了多个 Rust 兴趣小组。
+Databend 在 issue 中还引入了“Good First issue”的 label 来引导社区新同学参与第一次贡献,目共有超过一百多位 contributors,算是一个不错的成果。
+但 Databend 也在过去的一年中经历了数次迭代,代码日渐复杂。目前代码主干分支有 26 w 行 rust 代码,46 个 crate,对于新接触 Databend 的技术爱好者来说,贡献门槛越来越高。即使是熟悉 rust 的同学,clone 代码后,面对着茫茫码海,竟不知如何读起。在多个社区群中,也有朋友数次提到什么时候能有一个 Databend 源码阅读系列文章,帮助大家更快熟悉 Databend 代码。
+因此,我们接下来会开展“Databend 源码阅读”系列文章,主要受众是社区技术开发者,希望通过源码阅读,来加强和社区的技术交流,引发更多思维碰撞。
+很多同学都问过我们一个问题:为什么你们要用 Rust 从零构建一个数据库?其实这个问题可以分为两个子问题:
+我们早期的成员大多是 ClickHouse、tidb 、tokudb 等知名数据库的贡献者,从技术栈来说更熟悉的是 C++ 和 Go。虎哥(@bohutang)在疫情期间也使用 Go 实现了一个小的数据库原型 vectorsql,有同学表示 vectorsql 的架构非常优雅,值得学习借鉴。
+
语言本没有孰劣之分,要从面向的场景来聊聊。目前大多的 DMBS 使用的是 C++/Java,新型的 NewSQL 更多使用的是 Go。在以往的开发经验来看,C/C++ 已经是高性能的代名词,开发者更容易写出高运行效率的代码,但 C++ 的开发效率实在不忍直视,工具链不是很完善,开发者很难一次性写出内存安全,并发安全的代码。而 Go 可能是另外一个极端,大道至简,工具链完善,开发效率非常高,不足之处在于泛型的进度太慢了,在 DB 系统上内存不能很灵活的控制,且难于达到前者的运行性能,尤其使用 SIMD 指令还需要和汇编代码交互等。我们需要的是兼具 开发效率(内存安全,并发安全,工具链完善)& 运行效率 的语言,当时看来,Rust 可能是我们唯一的选择了,历经尝试后,我们也发现,Rust 不仅能满足我们的需求,而且很酷!
+总体来说,路线无非就以下两条:
+基于知名的开源数据库做二次开发优化
+这条路线可能更多人会选择,因为有一个好的数据库底座,无需再做一些重复性的工作,在上面做二次开发的话能省不少力气,团队专注做优化改进重构,能更早推动版本,落地商业化。缺点是 fork 后的版本难于再次回馈到社区,相当于另外一套独立的系统,如 PG 下的各个子流派。
+从零构建一套新的数据库系统
+这条路线走起来比较艰难,因为数据库系统实在太庞大了,一个子方向都足够专业人士深入研究十几年。这个方向虽然没能直接站在已有的底座上,但会让设计者更加灵活可控,无需关注太多历史的包袱。Databend 在设计之初面向的是云原生数仓的场景,和传统的数据库系统有很大的区别,如果基于传统数据库系统来做,改造代码的成本和从零做的成本可能差不多,因此我们选择的是这条路来从零打造一个全新的云数仓。
+画虎画皮难画骨,我们先从 Databend 的“骨”聊起。
+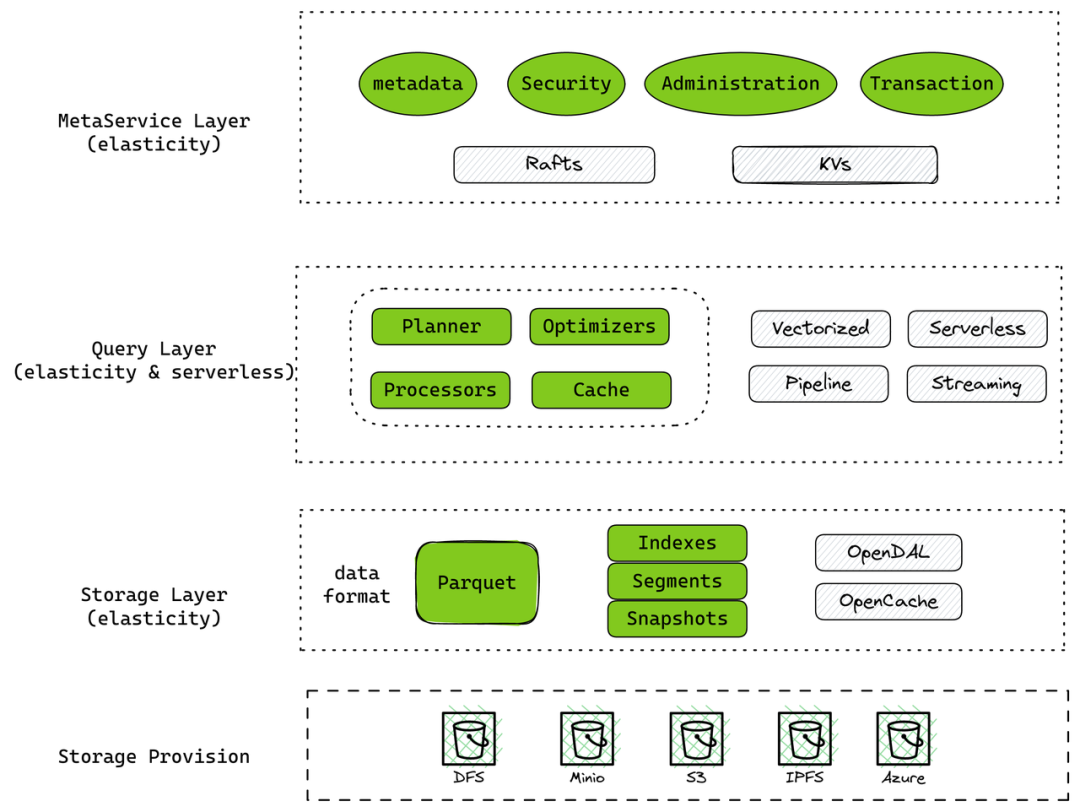
虽然我们是使用 Rust 从零开始实现的,但不是完全闭门造轮子,一些优秀的开源组件或者生态也有在其中集成。如:我们兼容了 Ansi-SQL 标准,提供了 MySQL/ClickHouse 等主流协议的支持,拥抱了万物互联的 Arrow 生态,存储格式基于大数据主流的 Parquet 格式等。我们不仅会积极地回馈了贡献给上游,如 Arrow2/Tokio 等开源库,一些通用的组件我们也抽成独立的项目开源在Github(openraft, opendal, opencache, opensrv 等)。
+Databend 定义为云原生的弹性数据库,在设计之初我们不仅要做到计算存储分离,每一层的极致的弹性都是设计主要考量点。Databend 主要分为三层:MetaService Layer,Query Layer,Storage Layer,这三层都是可以弹性扩展的,意味着用户可以为自己的业务选择最适合的集群规模,并且随着业务发展来伸缩集群。
+下面我们将从这三层来介绍下 Databend 的主要代码模块。
+MetaService 主要用于存储读取持久化的元数据信息,比如 Catalogs/Users 等。
+| 包名 | 作用 |
|---|---|
| meta/service | MetaService 服务,作为独立进程部署,可部署多个组成集群,底层使用 Raft 做分布式共识,Query 以 Grpc 和 MetaService 交互。 |
| meta/types | 定义了各类需要保存在 MetaService 的结构体,由于这些结构体最终需要持久化,所以涉及到数据序列化的问题,当前使用 Protobuf 格式来进行序列化和反序列化操作,这些类型相关的 Rust 结构体与 Protobuf 的相互序列化规则代码定义在 meta/proto-conv 子目录中。 |
| meta/sled-store | 当前 MetaService 使用 sled 来保存持久化数据,这个子目录封装了 sled 相关的操作接口。 |
| meta/raft-store | openraft 用户层需要实现 raft store 的存储接口用于保存数据,这个子目录就是 MetaService 实现的 openraft 的存储层,底层依赖于 sled 存储,同时这里还实现了 openraft 用户层需要自定义的状态机。 |
| meta/api | 对 query 暴露的基于 KVApi 实现的用户层 api 接口。 |
| meta/grpc | 基于 grpc 封装的 client,MetaService 的客户端使用这里封装好的 client 与 MetaService 进行通信交互。 |
| raft | https://github.com/datafuselabs/openraft,从 async-raft 项目中衍生改进的全异步 Raft 库。 |
Query 节点主要用于计算,多个 query 节点可以组成 MPP 集群,理论上性能会随着 query 节点数水平扩展。SQL 在 query 中会经历以下几个转换过程:
+
从 SQL 字符串经过 Parser 解析成 AST 语法树,然后经过 Binder 绑定 catalog 等信息转成逻辑计划,再经过一系列优化器处理转成物理计划,最后遍历物理计划构建对应的执行逻辑。 +query 涉及的模块有:
+| 包名 | 作用 |
|---|---|
| query/service | Query 服务,整个函数的入口在 bin/databend-query.rs 其中包含一些子模块,这里介绍下比较重要的子模块 |
| api :对外暴露给外部的 HTTP/RPC 接口 | |
| catalogs:catalogs 管理,目前支持默认的 catalog(存储在 metaservice)以及 hive catalog (存储在 hive meta store) | |
| clusters:query 集群信息 | |
| databases:query 支持的 database engine 相关 | |
| evaluator:表达式计算工具类 | |
| interpreters:SQL 执行器,SQL 构建出 Plan 后,通过对应执行器去做物理执行 | |
| pipelines:实现了物理算子的调度框架 | |
| servers:对外暴露的服务,有 clickhouse/mysql/http 等 | |
| sessions:session 管理相关 | |
| sql:包含新的 planner 设计,新的 binder 逻辑,新的 optimizers 设计 | |
| table_functions:表函数相关,如 numbers | |
| query/ast | 基于 nom_rule 实现的新版 sql parser |
| query/datavalues | 各类 Column 的定义,表示数据在内存上的布局, 后续会逐步迁移到 query/expressions |
| query/datablocks | Datablock 表示 Vec<Column> 集合,里面封装了一些常用方法, 后续会逐步迁移到 query/expressions |
| query/functions | 标量函数以及聚合函数等实现注册,后续会替换为 query/functions-v2 |
| query/formats | 负责数据对外各类格式的 序列化反序列化,如 CSV/TSV/Json 格式等 |
| query/storages | 表引擎相关,最常用为 fuse engine |
| common/hashtable | 实现了一个线性探测的 hashtable,主要用于 group by 聚合函数以及 join 等场景 |
| opensrv | https://github.com/datafuselabs/opensrv |
Storage 主要涉及表的 Snapshots,Segments 以及索引信息等管理,以及和底层 IO 的交互。Storage 目前一大亮点是基于 Snapshot 隔离 实现了类似 Iceberge 方式的 Increment view, 我们可以对表在任意历史状态下进行 time travel 访问。
+源码阅读系列刚刚开始撰写,后续预计将按照介绍各个模块的方式进行逐步讲解,输出主要以文章为主,一些比较重要且有趣的模块设计可能会以视频直播的方式和大家一起交流。
+目前只是一个初步的规划,在这个过程中会接受大家的建议做一些时间内容调整。无论如何,我们都期待通过这个系列的活动,让更多志同道合的人参与到 Databend 的开发中来,一起学习交流成长。
+ + + + + + + + +作者:Dousir9 | Databend Contributor
+本篇文章将以一条 SQL select t.id from t group by t.id 为例,分析 Pipeline 的执行,表结构及该 SQL 的 pipeline 如下所示,我们将从底部的 SyncReadParquetDataSource 向上进行分析。
mysql> desc t;
++-------+------+------+---------+-------+
+| Field | Type | Null | Default | Extra |
++-------+------+------+---------+-------+
+| id | INT | NO | 0 | |
+| val | INT | NO | 0 | |
++-------+------+------+---------+-------+
+
+mysql> explain pipeline select t.id from t group by t.id;
++--------------------------------------------------------+
+| explain |
++--------------------------------------------------------+
+| CompoundBlockOperator(Project) × 1 processor |
+| TransformFinalGroupBy × 1 processor |
+| TransformSpillReader × 1 processor |
+| TransformPartitionBucket × 1 processor |
+| TransformGroupBySpillWriter × 1 processor |
+| TransformPartialGroupBy × 1 processor |
+| DeserializeDataTransform × 1 processor |
+| SyncReadParquetDataSource × 1 processor |
++--------------------------------------------------------+
+首先我们需要明白 PipelineExecutor 是怎么运作的
// src/query/service/src/pipelines/executor/pipeline_executor.rs
+impl PipelineExecutor {
+ // ...
+
+ /// # Safety
+ ///
+ /// Method is thread unsafe and require thread safe call
+ pub unsafe fn execute_single_thread(&self, thread_num: usize) -> Result<()> {
+ let workers_condvar = self.workers_condvar.clone();
+ let mut context = ExecutorWorkerContext::create(
+ thread_num,
+ workers_condvar,
+ self.settings.query_id.clone(),
+ );
+
+ while !self.global_tasks_queue.is_finished() {
+ // When there are not enough tasks, the thread will be blocked, so we need loop check.
+ while !self.global_tasks_queue.is_finished() && !context.has_task() {
+ self.global_tasks_queue.steal_task_to_context(&mut context);
+ }
+
+ while !self.global_tasks_queue.is_finished() && context.has_task() {
+ if let Some(executed_pid) = context.execute_task()? {
+ // Not scheduled graph if pipeline is finished.
+ if !self.global_tasks_queue.is_finished() {
+ // We immediately schedule the processor again.
+ let schedule_queue = self.graph.schedule_queue(executed_pid)?;
+ schedule_queue.schedule(&self.global_tasks_queue, &mut context, self);
+ }
+ }
+ }
+ }
+
+ Ok(())
+ }
+ // ...
+}
+在调用 from_pipelines 构建 PipelineExecutor 时,我们会遍历每个 Pipeline 的 get_max_threads 来获得当前这个 PipelineExecutor 所需的线程数 threads_num。然后在 execute_threads 函数中,我们会创建 threads_num 个线程,每个线程都有当前这个 PipelineExecutor 的一份拷贝,随后每个线程会调用 execute_single_thread 开始执行任务。
(1)首先获得一份条件变量 workers_condvar 的拷贝并用它来创建一个 ExecutorWorkerContext,它存有 query_id,worker_num:worker 编号,task:当前要执行的任务,workers_condvar。
(2)当 global_tasks_queue 没有结束时,就会一直循环,如果 context 中没有 task,则会调用 steal_task_to_context 来获取任务,如果没有获取到则阻塞等待被唤醒。
(3)当获取到任务时,会首先调用 execute_task 来执行任务,对于 ExecutorTask::Sync 类型的任务来说,会调用 execute_sync_task 进而调用 Processor 的 process 函数,然后返回 processor.id() 用来后续推动 pipeline 的执行;而当 task 的类型为 ExecutorTask::AsyncCompleted 时,表示一个异步任务执行完了,这时我们返回 task.id 用来后续推动 pipeline 的执行。
// src/query/service/src/pipelines/executor/executor_worker_context.rs
+impl ExecutorWorkerContext {
+ pub unsafe fn execute_task(&mut self) -> Result<Option<NodeIndex>> {
+ match std::mem::replace(&mut self.task, ExecutorTask::None) {
+ ExecutorTask::None => Err(ErrorCode::Internal("Execute none task.")),
+ ExecutorTask::Sync(processor) => self.execute_sync_task(processor),
+ ExecutorTask::AsyncCompleted(task) => match task.res {
+ Ok(_) => Ok(Some(task.id)),
+ Err(cause) => Err(cause),
+ },
+ }
+ }
+}
+(4)在调用 execute_task 后我们得到了一个 executed_pid,这时候我们需要拿这个 executor_pid 来做一些 schedule 工作,继续推动 pipeline 的执行,首先调用 schedule_queue。
// src/query/service/src/pipelines/executor/executor_graph.rs
+impl ExecutingGraph {
+ // ...
+
+ /// # Safety
+ ///
+ /// Method is thread unsafe and require thread safe call
+ pub unsafe fn schedule_queue(
+ locker: &StateLockGuard,
+ index: NodeIndex,
+ schedule_queue: &mut ScheduleQueue,
+ ) -> Result<()> {
+ let mut need_schedule_nodes = VecDeque::new();
+ let mut need_schedule_edges = VecDeque::new();
+
+ need_schedule_nodes.push_back(index);
+ while !need_schedule_nodes.is_empty() || !need_schedule_edges.is_empty() {
+ // To avoid lock too many times, we will try to cache lock.
+ let mut state_guard_cache = None;
+
+ if need_schedule_nodes.is_empty() {
+ let edge = need_schedule_edges.pop_front().unwrap();
+ let target_index = DirectedEdge::get_target(&edge, &locker.graph)?;
+
+ let node = &locker.graph[target_index];
+ let node_state = node.state.lock().unwrap();
+
+ if matches!(*node_state, State::Idle) {
+ state_guard_cache = Some(node_state);
+ need_schedule_nodes.push_back(target_index);
+ }
+ }
+
+ if let Some(schedule_index) = need_schedule_nodes.pop_front() {
+ let node = &locker.graph[schedule_index];
+
+ if state_guard_cache.is_none() {
+ state_guard_cache = Some(node.state.lock().unwrap());
+ }
+ let event = node.processor.event()?;
+ if tracing::enabled!(tracing::Level::TRACE) {
+ tracing::trace!(
+ "node id: {:?}, name: {:?}, event: {:?}",
+ node.processor.id(),
+ node.processor.name(),
+ event
+ );
+ }
+ let processor_state = match event {
+ Event::Finished => State::Finished,
+ Event::NeedData | Event::NeedConsume => State::Idle,
+ Event::Sync => {
+ schedule_queue.push_sync(node.processor.clone());
+ State::Processing
+ }
+ Event::Async => {
+ schedule_queue.push_async(node.processor.clone());
+ State::Processing
+ }
+ };
+
+ node.trigger(&mut need_schedule_edges);
+ *state_guard_cache.unwrap() = processor_state;
+ }
+ }
+
+ Ok(())
+ }
+}
+在介绍 schedule_queue 函数之前有几个概念,trait Processor 有 event,process,async_process 这些函数,event 的作用是根据当前这个 Processor 的信息,来推动这个 Processor:包括改变 Processor 中的变量,改变 input port 和 output port,event 会返回一个 Event 状态来指示下一步的工作:
Event::Finished:表示 Processor 的工作结束了,将 Processor 的状态设置为 State::FinishedEvent::NeedData | Event::NeedConsume:表示 Processor 的 input 需要数据或者 output 的数据需要被消费,将 Processor 的状态设置为 tate::Idle,表示需要进行 schedule。Event::Sync:表示 Processor 需要调用 process 进行处理,将 Processor push 到 schedule_queue 的 sync_queue 中,并将 Processor 状态设置为 State::Processing。Event::Async:表示 Processor 需要调用 async_process 进行处理,将 Processor push 到 schedule_queue 的 async_queue 中,并将 Processor 状态设置为 State::Processing。schedule_queue 的工作过程:
+need_schedule_nodes: VecDeque<NodeIndex> 和 need_schedule_edges: VecDeque<DirectedEdge> 分别用来存放需要进行 schedule 的 NodeIndex 和 DirectedEdge,然后将 executor_pid push need_schedule_nodes 中。need_schedule_nodes 是否为空,如果它为空,那 need_schedule_edges 一定不为空,此时我们从 need_schedule_edges 中 pop 出一条 DirectedEdge edge,然后获得这条 edge 的 target node(注意这个 target node 不是 edge 的指向,DirectedEdge 有两种类型:Source 和 Target,当 Processor 的 input 改变时,会在 triger 的 update_list 中 push 一条 DirectedEdge::Target(self_.index),而如果是 Processor 的 output 改变,则 push 一条 DirectedEdge::Source(self_.index)),如果 target node 的状态为 State::Idle,表示它在上一次调用 event 时返回的 Event 状态为 Event::NeedData 或 Event::NeedConsume,即它上次 event 时 input 需要数据或 output 数据需要被消费,而它现在的状态可能是 input 的数据已经来了或者 output 的数据被消费了,因此我们需要将其 push 到 need_schedule_nodes 中来再次调用 event 看看是否可以推动这个 Processor。need_schedule_nodes pop 出一个 NodeIndex,并从 ExecutingGraph 中得到这个 Node,然后调用它的 Processor 的 event,然后根据返回的 Event 状态来进行下一步工作(如开头描述)。DirectedEdge 都 push 到 need_schedule_edges 中。need_schedule_nodes 或 need_schedule_edges 不为空则开始下一次 schedule。schedule_queue 返回。(5)调用 schedule_queue.schedule 处理 schedule_queue 中的 tasks
// src/query/service/src/pipelines/executor/executor_graph.rs
+impl ScheduleQueue {
+ // ...
+ pub fn schedule(
+ mut self,
+ global: &Arc<ExecutorTasksQueue>,
+ context: &mut ExecutorWorkerContext,
+ executor: &PipelineExecutor,
+ ) {
+ debug_assert!(!context.has_task());
+
+ while let Some(processor) = self.async_queue.pop_front() {
+ Self::schedule_async_task(
+ processor,
+ context.query_id.clone(),
+ executor,
+ context.get_worker_num(),
+ context.get_workers_condvar().clone(),
+ global.clone(),
+ )
+ }
+
+ if !self.sync_queue.is_empty() {
+ self.schedule_sync(global, context);
+ }
+
+ if !self.sync_queue.is_empty() {
+ self.schedule_tail(global, context);
+ }
+ }
+ // ...
+}
+async_queue 中的 Processor,我们将其 push 到 async_runtime 中,当 Processor 调用 async_process 完成异步任务完成后,会将 CompletedAsyncTask push 到 global_tasks_queue 中。sync_queue 中的 Processor,我们首先调用 schedule_sync 取出一个 Processor 并把包装为一个 ExecutorTask::Sync(processor) 任务交给当前线程继续执行。然后将剩下的 Processor 都包装为 Processor push 到 global_tasks_queue 中,让其他线程取出 task 并行执行。// src/query/pipeline/source/src/sync_source.rs
+#[async_trait::async_trait]
+impl<T: 'static + SyncSource> Processor for SyncSourcer<T> {
+ fn name(&self) -> String {
+ T::NAME.to_string()
+ }
+
+ fn as_any(&mut self) -> &mut dyn Any {
+ self
+ }
+
+ fn event(&mut self) -> Result<Event> {
+ if self.is_finish {
+ self.output.finish();
+ return Ok(Event::Finished);
+ }
+
+ if self.output.is_finished() {
+ return Ok(Event::Finished);
+ }
+
+ if !self.output.can_push() {
+ return Ok(Event::NeedConsume);
+ }
+
+ match self.generated_data.take() {
+ None => Ok(Event::Sync),
+ Some(data_block) => {
+ self.output.push_data(Ok(data_block));
+ Ok(Event::NeedConsume)
+ }
+ }
+ }
+
+ fn process(&mut self) -> Result<()> {
+ match self.inner.generate()? {
+ None => self.is_finish = true,
+ Some(data_block) => {
+ let progress_values = ProgressValues {
+ rows: data_block.num_rows(),
+ bytes: data_block.memory_size(),
+ };
+ self.scan_progress.incr(&progress_values);
+ self.generated_data = Some(data_block)
+ }
+ };
+
+ Ok(())
+ }
+}
+// src/query/storages/fuse/src/operations/read/parquet_data_source_reader.rs
+impl SyncSource for ReadParquetDataSource<true> {
+ const NAME: &'static str = "SyncReadParquetDataSource";
+
+ fn generate(&mut self) -> Result<Option<DataBlock>> {
+ match self.partitions.steal_one(self.id) {
+ None => Ok(None),
+ Some(part) => Ok(Some(DataBlock::empty_with_meta(DataSourceMeta::create(
+ vec![part.clone()],
+ vec![self.block_reader.sync_read_columns_data_by_merge_io(
+ &ReadSettings::from_ctx(&self.partitions.ctx)?,
+ part,
+ )?],
+ )))),
+ }
+ }
+}
+首先调用 inner (例如 ReadParquetDataSource,它实现了 trait SyncSource) 的 generate 获得一个空的 DataBlock,这个 DataBlock 数据为空,但是 meta 不为空,存有 part 和 data。将这个 data_block 赋值给 self.generated_data,
在下一次调用 event 的时候将 self.generated_data 通过 self.output.push_data(Ok(data_block)) 发送出去,并返回 Event::NeedConsume 这个状态。如果 !self.output.can_push() 为 true 的话,说明现在有 data_block 在 output 中,返回 Event::NeedConsume 状态。
// src/query/storages/fuse/src/operations/read/parquet_data_source_deserializer.rs
+#[async_trait::async_trait]
+impl Processor for DeserializeDataTransform {
+ fn name(&self) -> String {
+ String::from("DeserializeDataTransform")
+ }
+
+ fn as_any(&mut self) -> &mut dyn Any {
+ self
+ }
+
+ fn event(&mut self) -> Result<Event> {
+ if self.output.is_finished() {
+ self.input.finish();
+ self.uncompressed_buffer.clear();
+ return Ok(Event::Finished);
+ }
+
+ if !self.output.can_push() {
+ self.input.set_not_need_data();
+ return Ok(Event::NeedConsume);
+ }
+
+ if let Some(data_block) = self.output_data.take() {
+ self.output.push_data(Ok(data_block));
+ return Ok(Event::NeedConsume);
+ }
+
+ if !self.chunks.is_empty() {
+ if !self.input.has_data() {
+ self.input.set_need_data();
+ }
+
+ return Ok(Event::Sync);
+ }
+
+ if self.input.has_data() {
+ let mut data_block = self.input.pull_data().unwrap()?;
+ if let Some(source_meta) = data_block.take_meta() {
+ if let Some(source_meta) = DataSourceMeta::downcast_from(source_meta) {
+ self.parts = source_meta.part;
+ self.chunks = source_meta.data;
+ return Ok(Event::Sync);
+ }
+ }
+
+ unreachable!();
+ }
+
+ if self.input.is_finished() {
+ self.output.finish();
+ self.uncompressed_buffer.clear();
+ return Ok(Event::Finished);
+ }
+
+ self.input.set_need_data();
+ Ok(Event::NeedData)
+ }
+
+ fn process(&mut self) -> Result<()> {
+ let part = self.parts.pop();
+ let chunks = self.chunks.pop();
+ if let Some((part, read_res)) = part.zip(chunks) {
+ let start = Instant::now();
+
+ let columns_chunks = read_res.columns_chunks()?;
+ let part = FusePartInfo::from_part(&part)?;
+
+ let data_block = self.block_reader.deserialize_parquet_chunks_with_buffer(
+ &part.location,
+ part.nums_rows,
+ &part.compression,
+ &part.columns_meta,
+ columns_chunks,
+ Some(self.uncompressed_buffer.clone()),
+ )?;
+
+ // Perf.
+ {
+ metrics_inc_remote_io_deserialize_milliseconds(start.elapsed().as_millis() as u64);
+ }
+
+ let progress_values = ProgressValues {
+ rows: data_block.num_rows(),
+ bytes: data_block.memory_size(),
+ };
+ self.scan_progress.incr(&progress_values);
+
+ self.output_data = Some(data_block);
+ }
+
+ Ok(())
+ }
+}
+(1)如果 self.output.is_finished() 为 true,则调用 self.input.finish() 并返回 Event::Finished。
(2)如果 !self.output.can_push() 的话,表示上一次 push 出去的数据还没被消费,对 input 调用 set_not_need_data 表示不需要数据,返回 Event::NeedConsume。
(3)process 处理好的数据会放到 self.output_data 中,因此如果
+self.output_data.take() 有数据的话,则调用 self.output.push_data(Ok(data_block)) 将它发送出去,并返回 Event::NeedConsume。
(4)如果 self.input.has_data() 为 true,即 input 有数据,则调用 self.input.pull_data().unwrap()? 将 data_block pull 过来,然后获取其中的 BlockMetaInfo 并将其 downcast 成 DataSourceMeta,然后给 self.parts 和 self.chunks 赋值,返回 Event::Sync 状态。
(5)在(4)之前如果 !self.chunks.is_empty() 为 true,这时候我们正在处理之前的 data_block,因此要返回 Event::Sync 这个状态。此外因为这时候我们已经把上一个 data_block pull 过来了,input 可能为空,如果 input 没有数据的话,我们需要将 input set_need_data,为下一次 pull 做准备。
(6)如果 self.input.is_finished() 为 ture,则调用 self.output.finish() 并返回 Event::Finished。
(7)当前 Processor 既没有结束,也没有数据,因此对 input self.input.set_need_data(),返回 Event::NeedData。
每次调用 process 会处理一块 parquet_chunks,将其反序列化为数据不为空的 DataBlock,然后将其转交给 self.output_data 等待下一次 event 发送出去。
// src/query/pipeline/transforms/src/processors/transforms/transform_accmulating.rs
+#[async_trait::async_trait]
+impl<T: AccumulatingTransform + 'static> Processor for AccumulatingTransformer<T> {
+ fn name(&self) -> String {
+ String::from(T::NAME)
+ }
+
+ fn as_any(&mut self) -> &mut dyn Any {
+ self
+ }
+
+ fn event(&mut self) -> Result<Event> {
+ if self.output.is_finished() {
+ if !self.called_on_finish {
+ return Ok(Event::Sync);
+ }
+
+ self.input.finish();
+ return Ok(Event::Finished);
+ }
+
+ if !self.output.can_push() {
+ self.input.set_not_need_data();
+ return Ok(Event::NeedConsume);
+ }
+
+ if let Some(data_block) = self.output_data.pop_front() {
+ self.output.push_data(Ok(data_block));
+ return Ok(Event::NeedConsume);
+ }
+
+ if self.input_data.is_some() {
+ return Ok(Event::Sync);
+ }
+
+ if self.input.has_data() {
+ self.input_data = Some(self.input.pull_data().unwrap()?);
+ return Ok(Event::Sync);
+ }
+
+ if self.input.is_finished() {
+ return match !self.called_on_finish {
+ true => Ok(Event::Sync),
+ false => {
+ self.output.finish();
+ Ok(Event::Finished)
+ }
+ };
+ }
+
+ self.input.set_need_data();
+ Ok(Event::NeedData)
+ }
+
+ fn process(&mut self) -> Result<()> {
+ if let Some(data_block) = self.input_data.take() {
+ self.output_data.extend(self.inner.transform(data_block)?);
+ return Ok(());
+ }
+
+ if !self.called_on_finish {
+ self.called_on_finish = true;
+ self.output_data.extend(self.inner.on_finish(true)?);
+ }
+
+ Ok(())
+ }
+}
+整体上与 DeserializeDataTransform 的 event 类似,不同的地方在于:
(1)self.output_data 的类型为 VecDeque<DataBlock>,而不是 DataBlock,可以发送数据时,从调用 self.output_data.pop_front() 从队头取出一个 DataBlock 并 push 出去。
(2)在 self.output.is_finished() 或 self.input.is_finished() 为 true 时,首先判断 called_on_finish 是否为 true,如果不为 true 的话,表示还没有调用 inner 的 on_finish,这时候返回 Event::Sync 而不是 Event::Finished。
(1)如果 input_data 中有数据,则获取 input_data 中的 DataBlock 并用它调用 inner (例如 TransformPartialGroupBy,它实现了 trait AccumulatingTransform)的 transform(data_block)? 来获取需要 spill 的 data_blocks,这些 data_block 的 columns 是空的,但是 meta 不为空,meta 的类型为 AggregateMeta::Spilling;如果当前的 hash table 不大,则返回的结果是 vec![],transform 的分析在下面。
(2)如果 input_data 中没有数据且 called_on_finish 为 false,则调用 inner 的 on_finish 来获取 DataBlock,同样,这些 DataBlock 的 columns 是空的,但是 meta 不为空,meta 的类型为 AggregateMeta::HashTable,on_finish 的分析在下面。
// src/query/service/src/pipelines/processors/transforms/aggregator/transform_group_by_partial.rs
+impl<Method: HashMethodBounds> AccumulatingTransform for TransformPartialGroupBy<Method> {
+ const NAME: &'static str = "TransformPartialGroupBy";
+
+ fn transform(&mut self, block: DataBlock) -> Result<Vec<DataBlock>> {
+ let block = block.convert_to_full();
+ let group_columns = self
+ .group_columns
+ .iter()
+ .map(|&index| block.get_by_offset(index))
+ .collect::<Vec<_>>();
+
+ let group_columns = group_columns
+ .iter()
+ .map(|c| (c.value.as_column().unwrap().clone(), c.data_type.clone()))
+ .collect::<Vec<_>>();
+
+ unsafe {
+ let rows_num = block.num_rows();
+ let state = self.method.build_keys_state(&group_columns, rows_num)?;
+
+ match &mut self.hash_table {
+ HashTable::MovedOut => unreachable!(),
+ HashTable::HashTable(cell) => {
+ for key in self.method.build_keys_iter(&state)? {
+ let _ = cell.hashtable.insert_and_entry(key);
+ }
+ }
+ HashTable::PartitionedHashTable(cell) => {
+ for key in self.method.build_keys_iter(&state)? {
+ let _ = cell.hashtable.insert_and_entry(key);
+ }
+ }
+ };
+
+ #[allow(clippy::collapsible_if)]
+ if Method::SUPPORT_PARTITIONED {
+ if matches!(&self.hash_table, HashTable::HashTable(cell)
+ if cell.len() >= self.settings.convert_threshold ||
+ cell.allocated_bytes() >= self.settings.spilling_bytes_threshold_per_proc
+ ) {
+ if let HashTable::HashTable(cell) = std::mem::take(&mut self.hash_table) {
+ self.hash_table = HashTable::PartitionedHashTable(
+ PartitionedHashMethod::convert_hashtable(&self.method, cell)?,
+ );
+ }
+ }
+
+ if matches!(&self.hash_table, HashTable::PartitionedHashTable(cell) if cell.allocated_bytes() > self.settings.spilling_bytes_threshold_per_proc)
+ {
+ if let HashTable::PartitionedHashTable(v) = std::mem::take(&mut self.hash_table)
+ {
+ let _dropper = v._dropper.clone();
+ let cells = PartitionedHashTableDropper::split_cell(v);
+ let mut blocks = Vec::with_capacity(cells.len());
+ for (bucket, cell) in cells.into_iter().enumerate() {
+ if cell.hashtable.len() != 0 {
+ blocks.push(DataBlock::empty_with_meta(
+ AggregateMeta::<Method, ()>::create_spilling(
+ bucket as isize,
+ cell,
+ ),
+ ));
+ }
+ }
+
+ let method = PartitionedHashMethod::<Method>::create(self.method.clone());
+ let new_hashtable = method.create_hash_table()?;
+ self.hash_table = HashTable::PartitionedHashTable(HashTableCell::create(
+ new_hashtable,
+ _dropper.unwrap(),
+ ));
+ return Ok(blocks);
+ }
+
+ unreachable!()
+ }
+ }
+ }
+
+ Ok(vec![])
+ }
+}
+(1)首先调用 block.convert_to_full() 将 DataBlock 填充满:对于每个 BlockEntry,如果是 Value::Scalar 类型,则将其重复 self.num_rows 次转变为 Value::Column,如果原本就是 Value::Column 类型的话就简单 clone 一下。
(2)从 datablock 中获取用于 group by 的列 group_columns: Vec<&BlockEntry>,然后再转变为 Vec<(Column, DataType)>。
(3)调用 self.method.build_keys_state(&group_columns, rows_num) 将 group_columns group_columns 变为 KeyState:变为 unsigned 类型,
(4)调用 build_keys_iter 来获取 group by key 的 iter,并将每个 key 插入到 hash table 中。
(5)如果 hash table 的长度大于 convert_threshold 或者分配的字节数大于 spilling_bytes_threshold_per_proc,则将其装换为 PartitionedHashTable。
(6)如果一个 PartitionedHashTable 的长度大于 convert_threshold 或者分配的字节数大于 spilling_bytes_threshold_per_proc,这时候需要 spill 到存储上:将当前 hash table 转变为 blocks: Vec<DataBlock>,这些 DataBlock 的 columns 为空,meta 不为空,类型为:AggregateMeta::Spilling,然后创建一个新的 hash table,并将 blocks 返回。
(7)如果当前 hash table 不是很大,则返回 vec![]。
src/query/expression/src/kernels/group_by_hash.rs
(1)如果 group_by 只有一个字段的且这个字段是整数类型的话,则将这一列 cast 为 unsigned 类型,包装在 KeysState 中返回。
(2)否则调用 build_keys_vec 来构建 key,并将 key cast 成整数类型包装在 KeysState 中返回。
// src/query/service/src/pipelines/processors/transforms/aggregator/transform_group_by_partial.rs
+impl<Method: HashMethodBounds> AccumulatingTransform for TransformPartialGroupBy<Method> {
+ // ...
+ fn on_finish(&mut self, _output: bool) -> Result<Vec<DataBlock>> {
+ Ok(match std::mem::take(&mut self.hash_table) {
+ HashTable::MovedOut => unreachable!(),
+ HashTable::HashTable(cell) => match cell.hashtable.len() == 0 {
+ true => vec![],
+ false => vec![DataBlock::empty_with_meta(
+ AggregateMeta::<Method, ()>::create_hashtable(-1, cell),
+ )],
+ },
+ HashTable::PartitionedHashTable(v) => {
+ let cells = PartitionedHashTableDropper::split_cell(v);
+ let mut blocks = Vec::with_capacity(cells.len());
+ for (bucket, cell) in cells.into_iter().enumerate() {
+ if cell.hashtable.len() != 0 {
+ blocks.push(DataBlock::empty_with_meta(
+ AggregateMeta::<Method, ()>::create_hashtable(bucket as isize, cell),
+ ));
+ }
+ }
+
+ blocks
+ }
+ })
+ }
+}
+将 HashTable 或者 PartitionedHashTable 转变为 DataBlock 返回,这些 DataBlock 的 columns 字段为空,meta 字段类型为 AggregateMeta::HashTable。
如果 hash table 是 HashTable::HashTable 类型,则返回的 bucket id 为 -1,如果是 HashTable::PartitionedHashTable,则先调用 split_cell 将其 split 成 cells,然后再返回,bucket id 为 0 ~ cells.len() - 1。
// src/query/service/src/pipelines/processors/transforms/aggregator/serde/transform_group_by_spill_writer.rs
+#[async_trait::async_trait]
+impl<Method: HashMethodBounds> Processor for TransformGroupBySpillWriter<Method> {
+ fn name(&self) -> String {
+ String::from("TransformGroupBySpillWriter")
+ }
+
+ fn as_any(&mut self) -> &mut dyn Any {
+ self
+ }
+
+ fn event(&mut self) -> Result<Event> {
+ if self.output.is_finished() {
+ self.input.finish();
+ return Ok(Event::Finished);
+ }
+
+ if !self.output.can_push() {
+ self.input.set_not_need_data();
+ return Ok(Event::NeedConsume);
+ }
+
+ if let Some(spilled_meta) = self.spilled_meta.take() {
+ self.output
+ .push_data(Ok(DataBlock::empty_with_meta(spilled_meta)));
+ return Ok(Event::NeedConsume);
+ }
+
+ if self.writing_data_block.is_some() {
+ self.input.set_not_need_data();
+ return Ok(Event::Async);
+ }
+
+ if self.spilling_meta.is_some() {
+ self.input.set_not_need_data();
+ return Ok(Event::Sync);
+ }
+
+ if self.input.has_data() {
+ let mut data_block = self.input.pull_data().unwrap()?;
+
+ if let Some(block_meta) = data_block
+ .get_meta()
+ .and_then(AggregateMeta::<Method, ()>::downcast_ref_from)
+ {
+ if matches!(block_meta, AggregateMeta::Spilling(_)) {
+ self.input.set_not_need_data();
+ let block_meta = data_block.take_meta().unwrap();
+ self.spilling_meta = AggregateMeta::<Method, ()>::downcast_from(block_meta);
+ return Ok(Event::Sync);
+ }
+ }
+
+ self.output.push_data(Ok(data_block));
+ return Ok(Event::NeedConsume);
+ }
+
+ if self.input.is_finished() {
+ self.output.finish();
+ return Ok(Event::Finished);
+ }
+
+ self.input.set_need_data();
+ Ok(Event::NeedData)
+ }
+
+ fn process(&mut self) -> Result<()> {
+ if let Some(spilling_meta) = self.spilling_meta.take() {
+ if let AggregateMeta::Spilling(payload) = spilling_meta {
+ let bucket = payload.bucket;
+ let data_block = serialize_group_by(&self.method, payload)?;
+ let columns = get_columns(data_block);
+
+ let mut total_size = 0;
+ let mut columns_data = Vec::with_capacity(columns.len());
+ for column in columns.into_iter() {
+ let column = column.value.as_column().unwrap();
+ let column_data = serialize_column(column);
+ total_size += column_data.len();
+ columns_data.push(column_data);
+ }
+
+ self.writing_data_block = Some((bucket, total_size, columns_data));
+ return Ok(());
+ }
+
+ return Err(ErrorCode::Internal(""));
+ }
+
+ Ok(())
+ }
+
+ async fn async_process(&mut self) -> Result<()> {
+ if let Some((bucket, total_size, data)) = self.writing_data_block.take() {
+ let instant = Instant::now();
+ let unique_name = GlobalUniqName::unique();
+ let location = format!("{}/{}", self.location_prefix, unique_name);
+ let object = self.operator.object(&location);
+
+ // temp code: waiting https://github.com/datafuselabs/opendal/pull/1431
+ let mut write_data = Vec::with_capacity(total_size);
+ let mut columns_layout = Vec::with_capacity(data.len());
+
+ for data in data.into_iter() {
+ columns_layout.push(data.len());
+ write_data.extend(data);
+ }
+
+ object.write(write_data).await?;
+ info!(
+ "Write aggregate spill {} successfully, elapsed: {:?}",
+ &location,
+ instant.elapsed()
+ );
+
+ self.spilled_meta = Some(AggregateMeta::<Method, ()>::create_spilled(
+ bucket,
+ location,
+ columns_layout,
+ ));
+ }
+
+ Ok(())
+ }
+}
+
+fn get_columns(data_block: DataBlock) -> Vec<BlockEntry> {
+ data_block.columns().to_vec()
+}
+与前面几个 event 类似,不同的地方在于:
(1)当 self.input.has_data() 为 true 时,我们将从 DataBlock 中取出 meta,然后 downcast 成 AggregateMeta,检查其类型:(1)如果发现类型是 AggregateMeta::Spilling,则我们需要将其 spill 到存储上,于是我们将 downcast 后的结果赋值给 self.spilling_meta,等待在 process 中处理,返回 Event::Sync;(2)其他类型则直接调用 self.output.push_data(Ok(data_block)) push 出去,然后返回 Event::NeedConsume。
(2)如果发现 self.spilled_meta 有数据,表示这个数据已经被 spill 了,则将这个 meta 包装成一个空的 DataBlock 并 push 出去,返回 Event::NeedConsume。
process 是对 self.spilling_meta 进行处理,将其转变为 self.writing_data_block,随后交给 async_process spill 到存储上:
(1)首先检查 self.spilling_meta 中是否有数据,并获得 spilling_meta 中的 hash table。
(2)将 hash table 序列化为 DataBlock,并取出其中的列 columns: Vec<BlockEntry>,然后将每一列序列化为字节 column_data 并 push 到 columns_data 中。
(3)最后对 self.writing_data_block 进行赋值:self.writing_data_block = Some((bucket, total_size, columns_data));,等待在 async_process 中被 spill 到存储中。
将 self.writing_data_block spill 到存储中,然后将 spilled 后数据的 bucket,location 和 columns_layout 信息包装成一个 AggregateMeta::Spilled 类型的 meta 赋值给 self.spilled_meta,等待下一次调用 event 发送出去。
src/query/service/src/pipelines/processors/transforms/aggregator/transform_partition_bucket.rs
首先介绍一下 TransformPartitionBucket,它的 input 可以有多个,但是 output 只有一个,它的作用是将多个 bucket id 相同的 DataBlock 组成一个 AggregateMeta::Partitioned 发送出去。
impl<Method: HashMethodBounds, V: Copy + Send + Sync + 'static>
+ TransformPartitionBucket<Method, V>
+{
+ // ...
+ fn initialize_all_inputs(&mut self) -> Result<bool> {
+ self.initialized_all_inputs = true;
+
+ for index in 0..self.inputs.len() {
+ if self.inputs[index].port.is_finished() {
+ continue;
+ }
+
+ // We pull the first unsplitted data block
+ if self.inputs[index].bucket > SINGLE_LEVEL_BUCKET_NUM {
+ continue;
+ }
+
+ if !self.inputs[index].port.has_data() {
+ self.inputs[index].port.set_need_data();
+ self.initialized_all_inputs = false;
+ continue;
+ }
+
+ let data_block = self.inputs[index].port.pull_data().unwrap()?;
+ self.inputs[index].bucket = self.add_bucket(data_block);
+
+ if self.inputs[index].bucket <= SINGLE_LEVEL_BUCKET_NUM {
+ self.inputs[index].port.set_need_data();
+ self.initialized_all_inputs = false;
+ }
+ }
+
+ Ok(self.initialized_all_inputs)
+ }
+ // ...
+}
+首先我们先看一下 initialize_all_inputs 这个函数,每次调用 event 的时候,我们都会首先:
// We pull the first unsplitted data block
+if !self.initialized_all_inputs && !self.initialize_all_inputs()? {
+ return Ok(Event::NeedData);
+}
+它的作用是将 unsplitted data block,即 bucket id 为 -1 的 block 全 pull 过来,我们先回顾一下 TransformPartitionBucket 的上游的上游,即 AccumulatingTransformer,在 AccumulatingTransformer 中,我们如果 hash table 过大,我们会将其 spill 到存储上,而如果没有 spill 的话,会在 on_finish 的时候返回 bucket id 为 -1 的 DataBlock,而一旦有 spill,则不会有 bucket id 为 -1 的 DataBlock 被 push 到下游,上面这段代码利用了这一特点保证了 bucket id 为 -1 的 DataBlock 全都 pull 过来后,才会向下,执行,否则会一直返回 Event::NeedData。
(1)如果 self.output.is_finished() 为 true,调用每个 input 的 finish 并清空 buckets_blocks。
(2)利用 !self.buckets_blocks.is_empty() && !self.unsplitted_blocks.is_empty() 将所有的 unsplitted data block 全都 pull 过来后才会向下执行。
(3)如果 !self.buckets_blocks.is_empty() && !self.unsplitted_blocks.is_empty() 为 true,表示在 pull unsplitted data 的时候把 bucket id 不为 -1 的也 pull 过来了,这时候返回 Event::Sync,进而在下次调用 process 的时候将 bucket id 为 -1 的 DataBlock partition 为多个 bucket id 不为 -1 的 DataBlock。
(4)如果 !self.buckets_blocks.is_empty() && !self.unsplitted_blocks.is_empty() 为 false,表示 pull 过来的都是 bucket id 为 -1 的 DataBlock 或者 bucket id 为 -1 的 DataBlock 已经被 partition 为 bucket id 不为 -1 的 DataBlock 了。这时候我们首先调用 try_push_data_block 来 push bucket id 为 -1 的 DataBlock,bucket id 不为 -1 由于代码中 self.pushing_bucket < self.working_bucket 的限制还不能被 push。
(5)然后就是一个 loop 循环,具体做的事情就是 bucket id 从 0 开始,等 bucket id 为 0 的都 pull 过来了,再 pull bucket id 为 1 的,以此类推,一旦某个所有的 input 都 finish 了或者某个 input 的数据没准备好,则 break;
+(6)如果之前那次 push 有数据被 push 了或本次 push 返回 true,则返回 Event::NeedConsume。
(7)从 buckets_blocks 中 pop first,调用 convert_blocks 将多个 bucket id 相同的 DataBlock 组成一个 AggregateMeta::Partitioned 发送出去。(在 try_push_two_level 中, self.pushing_bucket 是递增不会退的,因此可能 bucket id 小的 DataBlock 不会在 try_push_two_level 中被 push 出去,而会在这里被 push 出去。
impl<Method: HashMethodBounds, V: Copy + Send + Sync + 'static>
+ TransformPartitionBucket<Method, V>
+{
+ // ...
+ fn add_bucket(&mut self, data_block: DataBlock) -> isize {
+ if let Some(block_meta) = data_block.get_meta() {
+ if let Some(block_meta) = AggregateMeta::<Method, V>::downcast_ref_from(block_meta) {
+ let (bucket, res) = match block_meta {
+ AggregateMeta::Spilling(_) => unreachable!(),
+ AggregateMeta::Partitioned { .. } => unreachable!(),
+ AggregateMeta::Spilled(payload) => (payload.bucket, SINGLE_LEVEL_BUCKET_NUM),
+ AggregateMeta::Serialized(payload) => (payload.bucket, payload.bucket),
+ AggregateMeta::HashTable(payload) => (payload.bucket, payload.bucket),
+ };
+
+ if bucket > SINGLE_LEVEL_BUCKET_NUM {
+ match self.buckets_blocks.entry(bucket) {
+ Entry::Vacant(v) => {
+ v.insert(vec![data_block]);
+ }
+ Entry::Occupied(mut v) => {
+ v.get_mut().push(data_block);
+ }
+ };
+
+ return res;
+ }
+ }
+ }
+
+ self.unsplitted_blocks.push(data_block);
+ SINGLE_LEVEL_BUCKET_NUM
+ }
+ // ...
+}
+将一个 DataBlock 加到 unsplitted_blocks 或者 buckets_blocks 中,可以看到,bucket id 为 -1 的 DataBlock 都会被 push 到 unsplitted_blocks 中。
impl<Method: HashMethodBounds, V: Copy + Send + Sync + 'static>
+ TransformPartitionBucket<Method, V>
+{
+ fn process(&mut self) -> Result<()> {
+ let block_meta = self
+ .unsplitted_blocks
+ .pop()
+ .and_then(|mut block| block.take_meta())
+ .and_then(AggregateMeta::<Method, V>::downcast_from);
+
+ match block_meta {
+ None => Err(ErrorCode::Internal(
+ "Internal error, TransformPartitionBucket only recv AggregateMeta.",
+ )),
+ Some(agg_block_meta) => {
+ let data_blocks = match agg_block_meta {
+ AggregateMeta::Spilled(_) => unreachable!(),
+ AggregateMeta::Spilling(_) => unreachable!(),
+ AggregateMeta::Partitioned { .. } => unreachable!(),
+ AggregateMeta::Serialized(payload) => self.partition_block(payload)?,
+ AggregateMeta::HashTable(payload) => self.partition_hashtable(payload)?,
+ };
+
+ for (bucket, block) in data_blocks.into_iter().enumerate() {
+ if let Some(data_block) = block {
+ match self.buckets_blocks.entry(bucket as isize) {
+ Entry::Vacant(v) => {
+ v.insert(vec![data_block]);
+ }
+ Entry::Occupied(mut v) => {
+ v.get_mut().push(data_block);
+ }
+ };
+ }
+ }
+
+ Ok(())
+ }
+ }
+ }
+}
+可以看到 process 是对 bucket id 为 -1 的 DataBlock 调用 partition_block 或 partition_hashtable 进行 partition 从而得到 data_blocks,然后将 data_blocks 插入到 buckets_blocks 中。
src/query/service/src/pipelines/processors/transforms/aggregator/serde/transform_spill_reader.rs
如果 DataBlock 不是 Spilled 类型,则直接 push 到下游,否则需要进行一些列处理:
TransformSpillReader 的处理是围绕着三个成员变量展开的:reading_meta,deserializing_meta 和 deserialized_meta:
reading_meta:上游传来的 AggregateMeta::Spilled 类型的 DataBlock,将它转交给 self.reading_meta 然后返回 Event::Async,在后面会调用 async_process 对其进行异步读取。deserializing_meta:异步线程会调用 async_process 对 reading_meta 进行处理:按照 reading_meta 中的信息读取存储,并将读到的内容存到的 self.deserializing_meta 中。在后续调用 event 时如果发现 self.deserializing_meta.is_some() 为 true,则返回 Event::Sync 来让线程调用 process 进行反序列化。deserialized_meta:将 deserializing_meta 中的数据进行反序列化,对于 AggregateMeta::Spilled 类型的 meta,我们将其分序列化为 AggregateMeta::Serialized。而对于 AggregateMeta::Partitioned 类型的 meta,我们将其中每个 meta 都反序列化为 AggregateMeta::Serialized,然后组成一个 AggregateMeta::Partitioned。最终我们将反序列化后的结果转交给 deserialized_meta,让它在下次 event 时被 push 出去。// src/query/pipeline/transforms/src/processors/transforms/transform.rs
+#[async_trait::async_trait]
+impl<B: BlockMetaInfo, T: BlockMetaTransform<B>> Processor for BlockMetaTransformer<B, T> {
+ fn name(&self) -> String {
+ String::from(T::NAME)
+ }
+
+ fn as_any(&mut self) -> &mut dyn Any {
+ self
+ }
+
+ fn event(&mut self) -> Result<Event> {
+ if !self.called_on_start {
+ return Ok(Event::Sync);
+ }
+
+ match self.output.is_finished() {
+ true => self.finish_input(),
+ false if !self.output.can_push() => self.not_need_data(),
+ false => match self.output_data.take() {
+ None if self.input_data.is_some() => Ok(Event::Sync),
+ None => self.pull_data(),
+ Some(data) => {
+ self.output.push_data(Ok(data));
+ Ok(Event::NeedConsume)
+ }
+ },
+ }
+ }
+
+ fn process(&mut self) -> Result<()> {
+ if !self.called_on_start {
+ self.called_on_start = true;
+ self.transform.on_start()?;
+ return Ok(());
+ }
+
+ if let Some(mut data_block) = self.input_data.take() {
+ debug_assert!(data_block.is_empty());
+ if let Some(block_meta) = data_block.take_meta() {
+ if let Some(block_meta) = B::downcast_from(block_meta) {
+ let data_block = self.transform.transform(block_meta)?;
+ self.output_data = Some(data_block);
+ }
+ }
+
+ return Ok(());
+ }
+
+ if !self.called_on_finish {
+ self.called_on_finish = true;
+ self.transform.on_finish()?;
+ }
+
+ Ok(())
+ }
+}
+如果 input_data 有数据的话,将 block_meta downcast 成实现 trait BlockMetaInfo 的某种 meta,例如 AggregateMeta,然后调用 self.transform.transform(block_meta)? 将 meta 转换 column 不为空的 DataBlock,然后将其转交给 self.output_data 等待下一次 event 时被 push 出去。
调用链:Processor 会包装一个 Transformer,Transformer 里面有一个 transform 成员,这个成员就是 BlockOperator 类型,调用 Processor 的 process 会调用 Transformer 的 self.transform.transform 进而调用 BlockOperator 的 execute 函数将 DataBlock transform 成另外的格式(例如 projection)
BlockOperator 有四种类型:
+// src/query/sql/src/evaluator/block_operator.rs
+/// `BlockOperator` takes a `DataBlock` as input and produces a `DataBlock` as output.
+#[derive(Clone)]
+pub enum BlockOperator {
+ /// Batch mode of map which merges map operators into one.
+ Map { exprs: Vec<Expr> },
+
+ /// Filter the input `DataBlock` with the predicate `eval`.
+ Filter { expr: Expr },
+
+ /// Reorganize the input `DataBlock` with `projection`.
+ Project { projection: Vec<FieldIndex> },
+
+ /// Unnest certain fields of the input `DataBlock`.
+ Unnest { fields: Vec<usize> },
+}
+execute 函数如下:
+impl BlockOperator {
+ pub fn execute(&self, func_ctx: &FunctionContext, mut input: DataBlock) -> Result<DataBlock> {
+ match self {
+ BlockOperator::Map { exprs } => {
+ for expr in exprs {
+ let evaluator = Evaluator::new(&input, *func_ctx, &BUILTIN_FUNCTIONS);
+ let result = evaluator.run(expr)?;
+ let col = BlockEntry {
+ data_type: expr.data_type().clone(),
+ value: result,
+ };
+ input.add_column(col);
+ }
+ Ok(input)
+ }
+
+ BlockOperator::Filter { expr } => {
+ assert_eq!(expr.data_type(), &DataType::Boolean);
+
+ let evaluator = Evaluator::new(&input, *func_ctx, &BUILTIN_FUNCTIONS);
+ let filter = evaluator.run(expr)?.try_downcast::<BooleanType>().unwrap();
+ input.filter_boolean_value(&filter)
+ }
+
+ BlockOperator::Project { projection } => {
+ let mut result = DataBlock::new(vec![], input.num_rows());
+ for index in projection {
+ result.add_column(input.get_by_offset(*index).clone());
+ }
+ Ok(result)
+ }
+
+ BlockOperator::Unnest { fields } => {
+ let num_rows = input.num_rows();
+ let mut unnest_columns = Vec::with_capacity(fields.len());
+ for field in fields {
+ let col = input.get_by_offset(*field);
+ let array_col = match &col.value {
+ Value::Scalar(Scalar::Array(col)) => {
+ Box::new(ArrayColumnBuilder::<AnyType>::repeat(col, num_rows).build())
+ }
+ Value::Column(Column::Array(col)) => col.clone(),
+ _ => {
+ return Err(ErrorCode::Internal(
+ "Unnest can only be applied to array types.",
+ ));
+ }
+ };
+ unnest_columns.push((*field, array_col));
+ }
+ Self::fit_unnest(input, unnest_columns)
+ }
+ }
+ }
+}
+至此,一条 SQL 的 pipeline 就执行完毕了。
+ + + + + + + + +作者:JackTan25 | Databend Contributor
+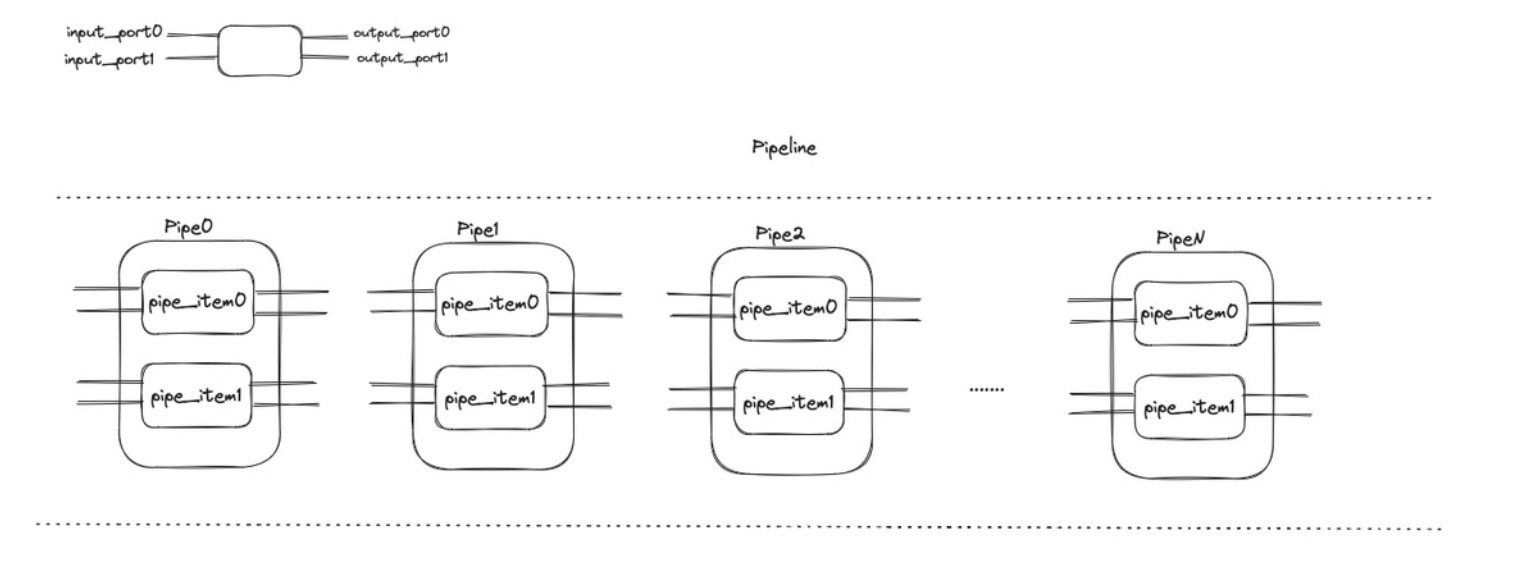
上图便是 databend 的一条 pipeline 结构,通常对于每一个 PipeItem,这里只会有一个 input_port 和 output_port,一个 Pipe 当中的 PipeItem 的数量则通常代表着并行度.每一个 PipeItem 里面对应着一个算子(不过在有些情况下并不一定一个 pipeItem 就只有一对 input_port 和 output_port,所以上图画的更加广泛一些),算子的推进由调度模型来触发
+将 pipeline 初始化为 graph:这里细致展示下生成的过程
+databend 采取的是采取的是 StableGraph 这个结构,我们最开始是得到了下面第一张图这样的 Pipeline,我们最后生成的是下面第二张图的 graph.
+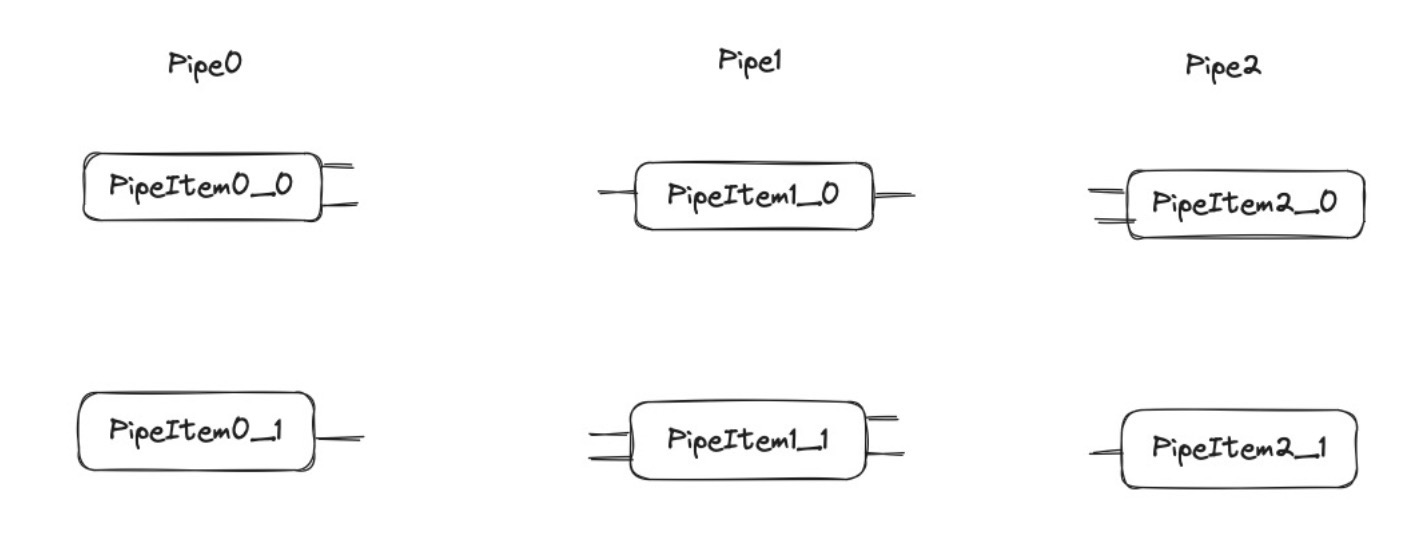 +
+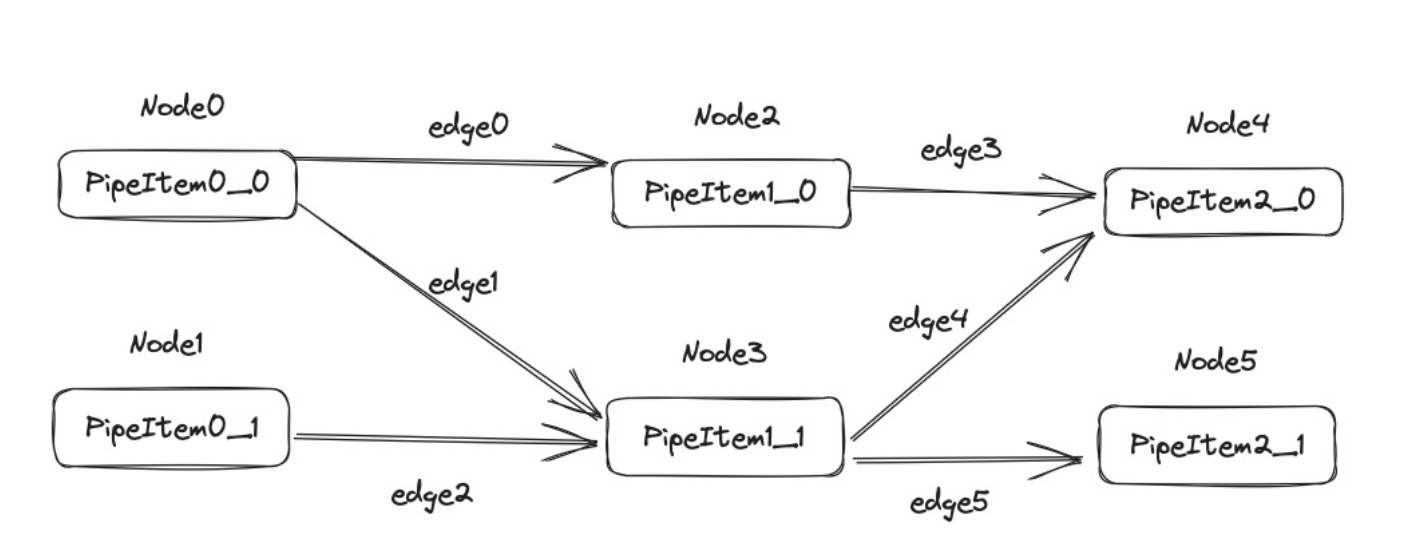
上面第二张图的的连接只是一个物理上的单纯图的连接,但是 node 内部 pipe_item 对应的 port 没有对接起来.我们还需要关心的是具体如何把对应的 port 给连接起来的.在构建图的时候每一个 PipeItem 包装为一个 node,包装的过程是以 Pipe 为顺序的.这样我们就为上面每一个 PipeItem 都加上了一个 Node 编号,后面我们需要按照为对应的 input_port 和 output_port 去加上 edge,我们的连接是一个平行的连接.
+我们将构建过程当中需要使用到的结构做一个介绍:
+// 一个Node对应一个PipeItem
+struct Node {
+ // node的状态记录,其实应该理解为是记录
+ // pipeline执行过程当中一个最小执行
+ // 单元PipeItem的状态,一共有如下三种状态:
+ // Idle,Processing,Finished,
+ state: std::sync::Mutex<State>,
+
+ updated_list: Arc<UpdateList>,
+ // 一下是pipeItem的内容
+ inputs_port: Vec<Arc<InputPort>>,
+ outputs_port: Vec<Arc<OutputPort>>,
+ processor: ProcessorPtr,
+}
+
+pub struct UpdateList {
+ inner: UnsafeCell<UpdateListMutable>,
+}
+pub struct UpdateListMutable {
+ // update_input与update_output调用时更新,用于
+ // 调度模型的任务调度
+ updated_edges: Vec<DirectedEdge>,
+ // 对于Node而言,其上的每一个input_port和output_port都会对应
+ // 一个trigger,我们从edge0,edge1,...,edgen(编号就是上图示例)
+ // 这样每次给source_node为其对应的output_port添加一个trigger
+ // 为target_node的input_port添加一个trigger
+ updated_triggers: Vec<Arc<UnsafeCell<UpdateTrigger>>>,
+}
+
+// 用于判断调度前驱node还是后驱node
+pub enum DirectedEdge {
+ Source(EdgeIndex),
+ Target(EdgeIndex),
+}
+
+// trigger的作用就是用来后面调度模型推进pipeline向下
+// 执行调度任务使用的
+pub struct UpdateTrigger {
+ // 记录该trigger对应的是哪一个边
+ index: EdgeIndex,
+ // 记录其属于哪一个UpdateListMutable
+ update_list: *mut UpdateListMutable,
+ // 初始化为0
+ version: usize,
+ // 初始化为0
+ prev_version: usize,
+}
+// 上面的例子最后我们得到的graph初始化后应该是下面这样
+
// 而对于input_port和output_port的数据的传递,则是两者之间共享一个SharedData
+pub struct SharedStatus {
+ // SharedData按照8字节对齐,所以其地址
+ // 最后三位永远为0,在这里我们会利用这三
+ // 位来标记当前port的状态,一共有三种
+ // NEED_DATA,HAS_DATA,IS_FINISHED
+ data: AtomicPtr<SharedData>,
+}
+初始化调度是将我们的 graph 的所有出度为 0 的 Node 作为第一次任务调度节点,对应我们的例子就是 Node4,Node5 每一次调度都是抽取出 graph 当中的同步任务和异步任务,下图是 pipeline 的调度模型,用于抽取出当前 graph 当中可执行的同步 processor 和异步 processor,调度模型的输入是最上面的 graph,而输出则是 sync_processor_queue 和 async_processor_queue,无论是在初始化时还是在后面继续执行的过程都是利用的下面的调度模型来进行调度.调度模型的执行终点是 need_schedule_nodes 和 need_schedule_edges 均为空
+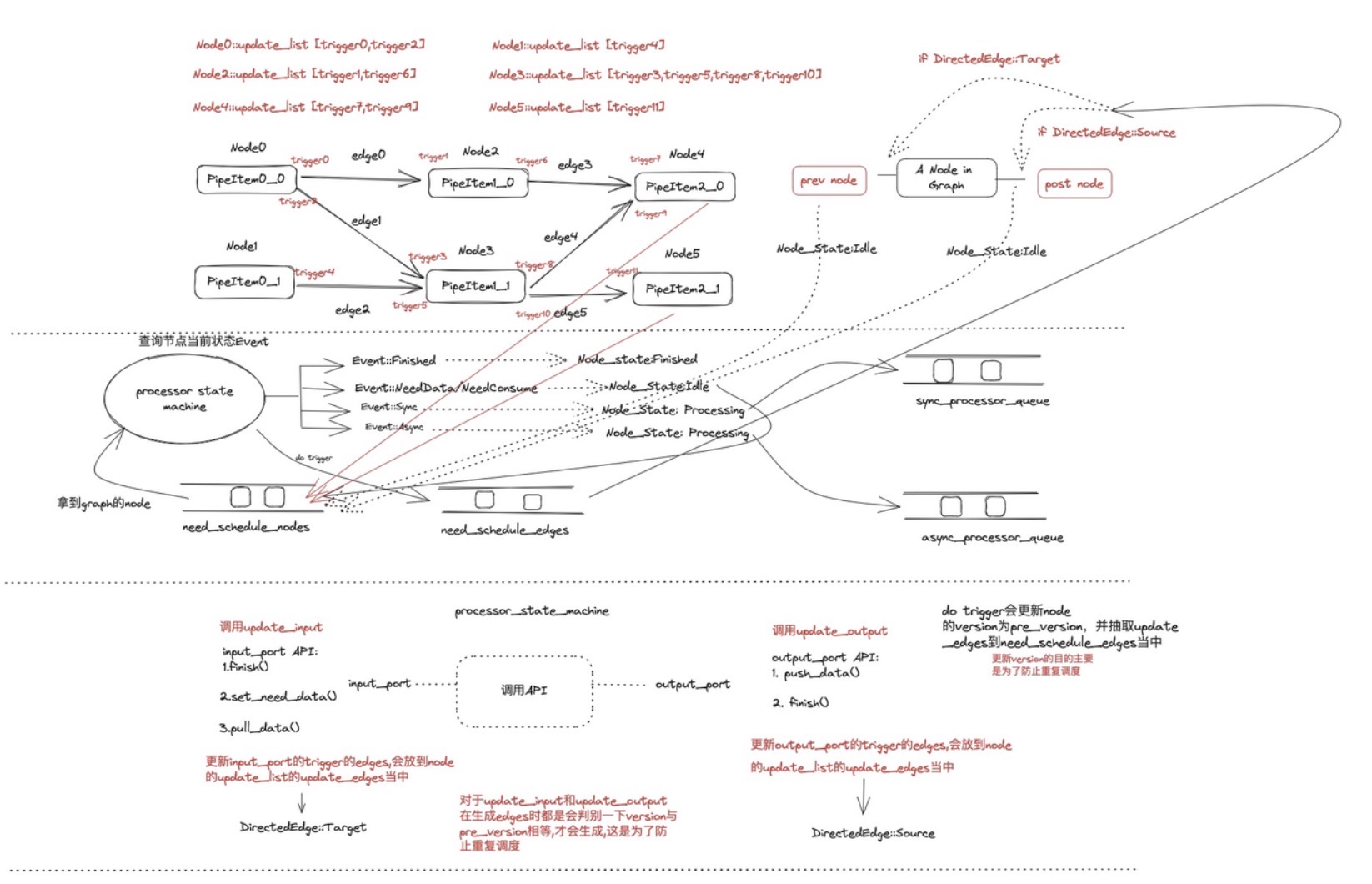
执行模型对应相关结构如下:
+struct ExecutorTasks {
+ // 记录当前还剩余的task的数量
+ tasks_size: usize,
+ workers_waiting_status: WorkersWaitingStatus,
+ // 记录同步任务,其大小等于系统当前允许的thread数量
+ workers_sync_tasks: Vec<VecDeque<ProcessorPtr>>,
+ // 记录已完成的异步任务,其大小等于系统当前允许的thread数量
+ workers_completed_async_tasks: Vec<VecDeque<CompletedAsyncTask>>,
+}
+
+// 用于记录等待线程和活跃线程
+pub struct WorkersWaitingStatus {
+ stack: Vec<usize>,
+ stack_size: usize,
+ worker_pos_in_stack: Vec<usize>,
+}
+
+pub struct WorkersCondvar {
+ // 记录还未执行完的异步任务
+ waiting_async_task: AtomicUsize,
+ // 用于唤醒机制
+ workers_condvar: Vec<WorkerCondvar>,
+}
+
+pub struct ProcessorAsyncTask {
+ // worker_id代表的是当前异步任务对应的线程id
+ worker_id: usize,
+ // 在graph当中的节点位置
+ processor_id: NodeIndex,
+ // 全局的任务队列
+ queue: Arc<ExecutorTasksQueue>,
+ // 用于work-steal的调度唤醒策略
+ workers_condvar: Arc<WorkersCondvar>,
+ // 一个包装future,见下图的具体包装
+ inner: BoxFuture<'static, Result<()>>,
+}
+
+pub struct ExecutorTasksQueue {
+ // 记录当前执行任务队列是否完成
+ finished: Arc<AtomicBool>,
+ // 通知异步任务结束
+ finished_notify: Arc<Notify>,
+ workers_tasks: Mutex<ExecutorTasks>,
+}
+
+// 唤醒机制
+struct WorkerCondvar {
+ mutex: Mutex<bool>,
+ condvar: Condvar,
+}
+执行模型的流程图如下:
+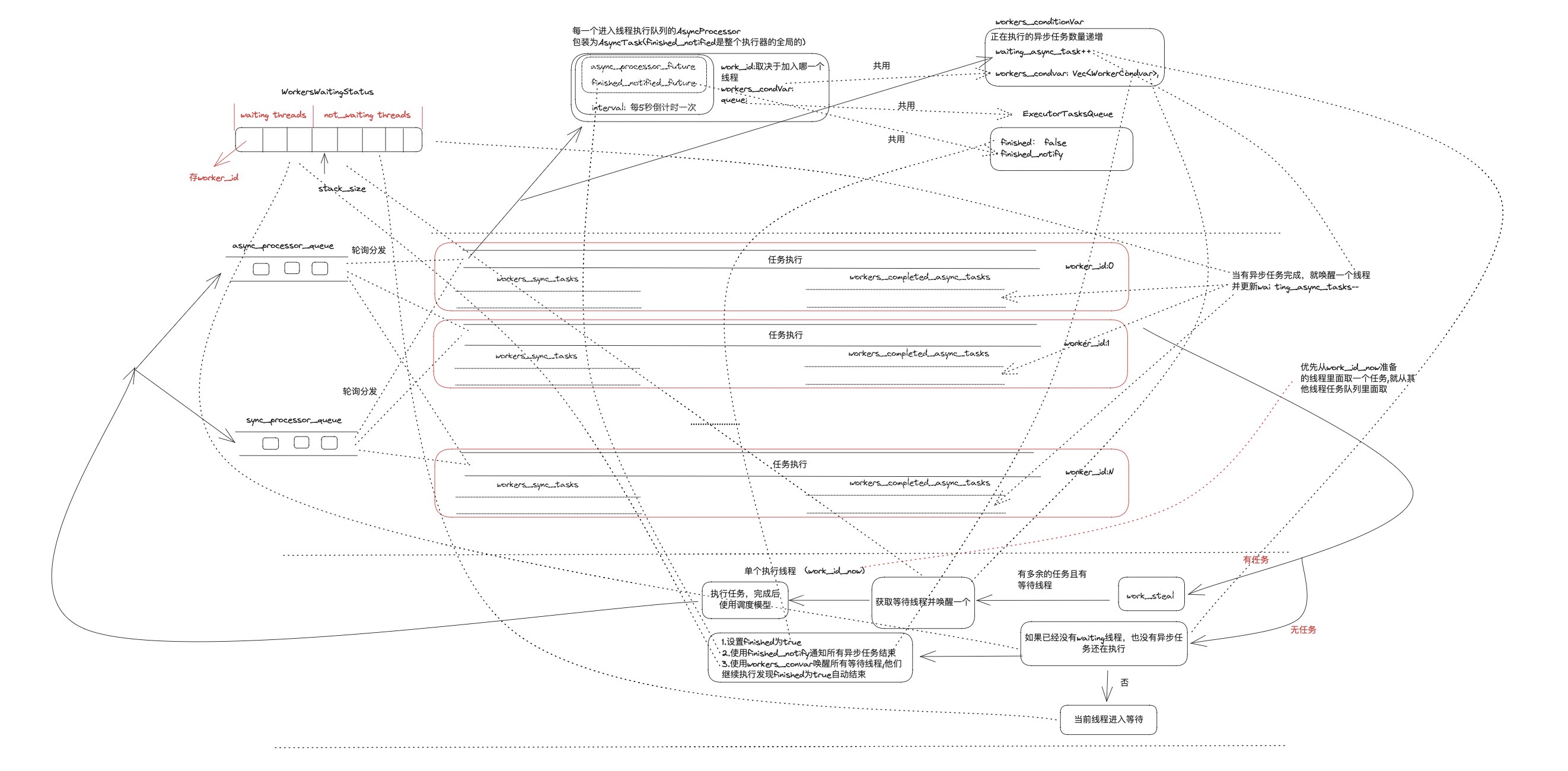
限时机制其实是比较简单的,其主要的作用就是限制 sql 的 pipeline 执行的时间在规定时间内完成, +如果超时则自动终止.这个机制底层实现就是用了一个异步任务来跟踪,一旦超时就通知整个执行模型结束,这里对应的就是执行模型流程图里面的 finish。
+以上便是 databend 的机遇状态机和 work-steal 机制的并发调度模型实现.
+ + + + + + + + +作者:zhyass | Databend Labs 成员,数据库研发工程师
+Databend 将存储引擎抽象成一个名为 Table 的接口,源码位于 query/catalog/src/table.rs。
Table 接口定义了 read、append、alter、optimize、truncate 以及 recluster 等方法,负责数据的读写和变更。解释器(interpreter)通过调用 Table trait 的方法生成物理执行的 pipeline。
通过实现 Table 接口的方法,可以定义 Databend 的存储引擎,不同的实现对应不同的引擎。
Storage 主要关注 Table 接口的具体实现,涉及表的元信息,索引信息的管理,以及与底层 IO 的交互。
| 包名 | 作用 |
|---|---|
| common/cache | 定义与管理缓存,包括磁盘缓存和内存缓存。类型包含表 meta 缓存、查询结果缓存、表数据缓存等。 |
| common/index | 定义与使用索引,目前支持 bloom filter index、page index、range index。 |
| common/locks | 管理与使用锁,支持表级别的锁。 |
| common/pruner | 分区剪裁算法,包括 internal column pruner、limiter pruner、page pruner、topn pruner、range pruner。 |
| common/table_meta | 表 meta 的数据结构定义。 |
| hive | hive 表的交互 |
| iceberg | iceberg 交互 |
| information_schema、system | 系统表定义 |
| memory、null、random | 用于开发和测试的引擎 |
| view | 视图相关 |
| stage | stage 数据源的读取 |
| parquet | 把 parquet 文件作为数据源 |
| fuse | fuse 引擎模块 |
| fuse/src/io | table meta、index、block 的读写 IO 交互 |
| fuse/src/pruning | fuse 分区裁剪 |
| fuse/src/statistics | column statistics 和 cluster statistics 等统计信息 |
| fuse/src/table_functions | table function 实现 |
| fuse/src/operation | fuse 引擎对 table trait 方法的具体实现。并包含了如 ReadSource、CommitSink 等 processor 算子的定义 |
以下以 fuse 引擎中 read partitions 的实现流程为例,简要分析 Storage 相关源码。
+Partitions 的定义位于 query/catalog/src/plan/partition.rs。
pub struct Partitions {
+ // partitions 的分发类型。
+ pub kind: PartitionsShuffleKind,
+ // 一组实现了 PartInfo 接口的 partition,
+ pub partitions: Vec<PartInfoPtr>,
+ // partitions 是否为 lazy。
+ pub is_lazy: bool,
+}
+Table 接口中的 read_partitions 通过分析查询中的过滤条件,剪裁掉不需要的分区,返回可能满足条件的 Partitions。
#[async_trait::async_trait]
+impl Table for FuseTable {
+ #[minitrace::trace]
+ #[async_backtrace::framed]
+ async fn read_partitions(
+ &self,
+ ctx: Arc<dyn TableContext>,
+ push_downs: Option<PushDownInfo>,
+ dry_run: bool,
+ ) -> Result<(PartStatistics, Partitions)> {
+ self.do_read_partitions(ctx, push_downs, dry_run).await
+ }
+}
+Fuse 引擎会以 segment 为单位构建 lazy 类型的 FuseLazyPartInfo。通过这种方式,prune_snapshot_blocks 可以下推到 pipeline 初始化阶段执行,特别是在分布式集群模式下,可以有效提高剪裁执行效率。
pub struct FuseLazyPartInfo {
+ // segment 在 snapshot 中的索引位置。
+ pub segment_index: usize,
+ pub segment_location: Location,
+}
+分区剪裁流程的实现位于 query/storages/fuse/src/pruning/fuse_pruner.rs 文件中,具体流程如下:
push_downs 条件构造各类剪裁器(pruner),并实例化 FusePruner。FusePruner 中的 pruning 方法,创建 max_concurrency 个分批剪裁任务。每个批次包括多个 segment 位置,首先根据 internal_column_pruner 筛选出无需的 segments,再读取 SegmentInfo,并根据 segment 级别的 MinMax 索引进行范围剪裁。SegmentInfo 中的 BlockMetas,并按照 internal_column_pruner、limit_pruner、range_pruner、bloom_pruner、page_pruner 等算法的顺序,剔除无需的 blocks。TopNPrunner 进行过滤,从而得到最终剪裁后的 block_metas。pub struct FusePruner {
+ max_concurrency: usize,
+ pub table_schema: TableSchemaRef,
+ pub pruning_ctx: Arc<PruningContext>,
+ pub push_down: Option<PushDownInfo>,
+ pub inverse_range_index: Option<RangeIndex>,
+ pub deleted_segments: Vec<DeletedSegmentInfo>,
+}
+
+pub struct PruningContext {
+ pub limit_pruner: Arc<dyn Limiter + Send + Sync>,
+ pub range_pruner: Arc<dyn RangePruner + Send + Sync>,
+ pub bloom_pruner: Option<Arc<dyn BloomPruner + Send + Sync>>,
+ pub page_pruner: Arc<dyn PagePruner + Send + Sync>,
+ pub internal_column_pruner: Option<Arc<InternalColumnPruner>>,
+ // Other Fields ...
+}
+
+impl FusePruner {
+ pub async fn pruning(
+ &mut self,
+ mut segment_locs: Vec<SegmentLocation>,
+ delete_pruning: bool,
+ ) -> Result<Vec<(BlockMetaIndex, Arc<BlockMeta>)>> {
+ ...
+ }
+}
+剪裁结束后,以 Block 为单位构造 FusePartInfo,生成 partitions,接着调用 set_partitions 方法将 partitions 注入 QueryContext 的分区队列中。在执行任务时,可以通过 get_partition 方法从队列中取出。
pub struct FusePartInfo {
+ pub location: String,
+ pub create_on: Option<DateTime<Utc>>,
+ pub nums_rows: usize,
+ pub columns_meta: HashMap<ColumnId, ColumnMeta>,
+ pub compression: Compression,
+ pub sort_min_max: Option<(Scalar, Scalar)>,
+ pub block_meta_index: Option<BlockMetaIndex>,
+}
+Databend 的存储引擎设计采用了抽象接口的方式,具有高度的可扩展性,可以很方便地支持多种不同的存储引擎。Storage 模块的主要职责是实现 Table 接口的方法,其中 Fuse 引擎部分尤为关键。
+通过对数据的并行处理,以及数据剪裁等手段,可以有效地提高数据的处理效率。鉴于篇幅限制,本文仅对读取分区的流程进行了简单阐述,更深入的解析将在后续的文章中逐步展开。
+ + + + + + + + +数据库中的索引就像书后附录提供的索引一样,有助于快速定位记录并读取需要的信息。本文简要梳理了索引相关的内容。
+在很多书籍的附录中会包含一份索引,记录了关键字/词组/主题在书中出现的页码。如果需要查阅特定主题的内容,只需要打开索引检索主题,并翻到对应页码即可。
+那么对于数据库来说,如果计划访问具有某些特征的记录,则可以通过索引找出其所对应的数据块,通过读取数据块得到对应的记录。
+在上面的过程中,可以清楚看到索引的一个显著 优点 是:加快数据查询的速度。
+但是,设想你正在撰写一本技术书,并不得不为数百上千个关键字建立索引。显而易见,索引也有一些 缺点 :创建和维护索引会耗费一定的时间,且索引还需要占据额外的空间。
+书籍中的索引常常会按关键字的字典序进行排列,对应到数据库中,这类基于值的顺序编排的索引被称作 顺序索引 。
+随着索引量的增大,即便是按顺序查找仍然会需要耗费大量时间,通过引入一些相对更复杂的索引技术,可以解决此问题。常见的是 散列索引 ,基于散列函数将值分布到若干散列桶。
+数据库系统中往往会存在不止一种索引技术,不同数据库系统之间的索引技术可能也不同。评估并对比不同的索引可以考虑以下几个指标:
+越来越多的数据库产品提供分布式解决方案,那么什么是分布式?
+分布式系统是由一组计算节点通过网络链接组成的服务系统,作为整体对外提供服务。由于计算节点可能存在异构、分区等问题,还需要解决系统中存在的通讯和共识问题。
+作为一个松耦合的系统,分布式系统具有以下特点:
+从某种视角上看,分布式系统与 MPP 系统有着惊人的相似。比如:通过网络连接、对外作为整体提供服务、计算节点拥有资源等。但是这两种架构仍然会有一些不同。
+查询在数据库系统中的调度与执行方式同样会深刻影响到数据库的性能表现。本文简要梳理了查询流程中与执行相关的内容,希望能够帮助大家更好理解查询引擎的工作原理。
+首先一起来回顾一下查询的基本流程。
+
如上图所示,查询往往需要经历下述几个阶段:
+1990 年发表的 Volcano, an Extensible and Parallel Query Evaluation System 中提出 Volcano Model 并为人熟知。
+
Volcano 是一种基于行的流式迭代模型,简单而又优美。拉取数据的控制命令从最上层的算符依次传递到执行树的最下层,与数据的流动方向正好相反。
+next() 调用,虚函数嵌套对分支预测并不友好,会破坏 CPU 流水线并造成 Cache 和 TLB 失效。时至今日,内存容量突飞猛进,数据可以直接存放在内存中,负载从 IO bound 转向 memory bound ;而 CPU 单核效率面临瓶颈,多核能力日益重要,更需要关注 CPU 执行效率。向量化执行/编译执行等方式开始绽放异彩。
+尽管 Volcano Model 受限于当时尚未成熟的硬件环境(CPU 并行能力不足、内存容量小且 IO 效率低下),但它的设计仍然值得借鉴,在现代一些 state of the art 执行器方案中,仍然可以看到它的影子。
+Databend 的执行器部分主要借鉴了 Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age 这篇论文。
+
Morsel 有「小块」的意思,意味着任务会被拆解成大小合适、可动态调整的一系列算子,比如表达式的计算、聚合函数的计算等。而 Morsel-Driven Parallelism 提供了一种自适应的调度执行方案,在运行时确定任务的并行度,按流水线的方式执行操作,并通过调度策略来尽量保证数据的本地化,在实现 load balance 的同时最小化跨域数据访问。
+汽车的流水线生产需要各个部门、各种零件配合,查询的高效执行也离不开不同算子的组合。
+这时就需要引入一个调度器(Dispatcher)为并行的 Pipeline 控制分配计算资源。Dispatcher 维护着各个查询传递而来的 Pipeline Jobs,每个任务都相当于查询的一个子计划,会对应到底层需要处理的数据。在线程池请求分发 Task 时,Dispatcher 会遵循调度策略,根据任务执行状态、资源使用情况等要素,来决定什么时候 CPU 该执行哪个 Transform 。
+Morsel-Driven Parallelism 的研究不仅仅关注执行框架的改进,还涵盖一些特定算法的并行优化,比如 Hash Join、Grouping/Aggregation 以及排序。
+在 Morsel Wise 思想的指导下,Morsel-Driven Parallelism 执行框架解决了多核时代中负载均衡、线程同步、本地内存访问以及资源弹性调度的问题。
+向量化执行自 MonetDB/X100(Vectorwise)开始流行,MonetDB/X100: Hyper-Pipelining Query Execution 这篇论文也成为了必读之作。而在 2010 年之后的 OLAP 系统,基本上都是按列式存储进行数据组织的。
+
OLAP 系统需要处理的查询通常涉及大量的数据,采用列式存储方案在提高 IO 效率方面具备天然优势。
+向量化执行的优势在于可以充分利用 CPU 缓存,从而设计更为高效的分析查询引擎。
+谈到向量化执行,不可避免要用到 SIMD(单指令多数据)。传统的方式是查询指令集,然后手工编写指令;而在 Databend 中,采用以下方式:
+std::simd 提供关于 SIMD 指令的抽象封装,可以编写易于理解的代码。++以下内容整理自 @fkuner 和 @zhang2014 的一次对话。
+
Databend 中如何保证 numa-local ?
+答:numa-local 在 aggregator processor 中是 core 独享的。pipelines size 和 executor worker size 1:1 对应也是为了numa local 。在调度时,尽量不会切换线程。一个任务从头调度到尾,将新产生的支线任务放入全局调度。
+Pipeline 如果需要等待 IO 是如何调度的?
+答:Databend 通过感知数据状态来调度 Pipeline,如果数据没有准备好不会调度。至于 IO ,会被调度到 global io runtime 中,通过 Rust Async 阻塞等待。
+任务、Pipeline 和 Processor 的对应关系是怎样的?
+答:论文中的模型是:一个任务处理一个 Pipline ,而一个 Pipeline 可以由多个 Processor 组成。而 Databend 可以在 Processor 级别做任务窃取,任务切割到 Processor 级别可切分的情况下,调度是更灵活的。虽然是在调度器中调度Processor,但这个 Processor 在运行状态中具体对应到的就是一个 Data Block 。类似论文中 Pipeline 的 Job 切分。
+Databend 中对 numa-local 倾向性的调度处理是如何做的?
+答:理想状态下执行线程应该互不干扰,但考虑到任务可能存在倾斜。当其中某个线程提前完成任务时,为了加速整个执行流程可能需要该线程窃取剩下的任务。在调度时,执行器会存在一个 local context ,不会在线程间存在任何共享。
+大规模并行处理是大数据计算引擎的一个重要特性,可以提供高吞吐、低时延的计算能力。那么,当我们在讨论大规模并行处理时,究竟在讨论什么?
+企业或个人都可能会收集和存储大量的数据,特别是近年来大数据技术的兴起,人们拥有更多接触数据和利用数据的机会和意愿,那么随着数据量的增长,对存储容量和计算能力的要求也进一步提高了。
+大规模并行处理(MPP,Massively Parallel Processing)意味着可以由多个计算节点(处理器)协同处理程序的不同部分,而每个计算节点都可能具备独立的系统资源(磁盘、内存、操作系统)。
+计算节点将工作拆分成易于管理、调度和执行的任务执行,通过添加额外的计算节点可以完成水平拓展。随着计算节点数目的增加,对数据的查询处理速度就越快,从而减少大数据集上处理复杂查询所需的时间。
+采用大规模并行处理架构设计的系统往往具备以下特性:
+查询优化是数据库系统的一个重要话题。本文介绍了查询优化的相关概念及发展历史,Cascades 优化器以及云数仓所面临的查询优化挑战。
+++本文根据 @leiysky 的分享整理而来,略去了查询优化的细节,详细的 PPT 可以参考 SQL Processing & Query Optimization 。
+
查询优化指的是为给定的查询选择最佳执行计划。
+那么什么样的执行计划称得上是最佳计划呢?
+目前有两种主要的查询优化方案,一种是基于关系代数和算法的等价优化方案,一种是基于评估成本的优化方案。
+根据命名,不难看出优化的灵感来源和这两种方案在优化上的取舍。
+查询优化通常包含以下四个步骤:
+世界上第一个查询优化器是 IBM System R 的优化器。
+其建立背景是:
+PostgreSQL 是世界上最成功的开源 RDBMS 之一,有着悠久的历史(1996 年首次发布)。
+SQL Server,由微软和 Sybase 在 20 世纪 90 年代开发的商业 RDBMS 。
+Goetz Graefe(Volcano/Cascades的作者)为 SQL Server 设计了 Cascades 查询优化框架。
+该优化器框架已被广泛用于微软开发的不同查询系统(如 SQL Server、SQL Server PDW、Cosmos SCOPE、Synapse)。
+世界上最好的查询优化器(也许)。
+枚举计划并评估成本的探索框架。
+在这篇文章中,概述了存储的一些基本内容并简要回答「数据库如何进行存储」,为大家了解存储系统提供一个基本的视角。
+综合存储介质的性能和成本,大致可以得到一个如下图所示的层次结构:
+
常见存储介质
+根据数据访问频率的划分
+缓存和主内存是基本存储,只有存放在基本存储中的数据才能被直接访问和处理;其他正在使用/将要使用的数据往往会存放在闪存和磁盘上,这两类存储介质可以视作是二级存储,也就是联机存储;对于备份或不常访问的数据,则会依赖光盘和磁带进行存储,它们也被称作是三级存储或者是脱机存储。
+根据存储易失性的划分
+缓存和主内存通常被认为是易失性存储,这表示它们在断电后会丢失所有数据;而其他几个视作非易失性存储。为了保存数据,必须将数据写入到非易失性存储中。
+DAS 直接连接存储,是一种以服务器为中心的存储方案,对外和多个主机连接,对内连接多个磁盘,并实现 RAID 技术,形成一个磁盘阵列。
+SAN 存储区域网,通过专用高速网将一个或多个网络存储设备和服务器连接起来的专用存储系统。通常情况下,SAN 方案会采用 RAID 技术提供一个的大逻辑存储视图。
+NAS 附网存储系统是另一类集成系统、存储和网络技术的方案,可以看作是一个装有优化的文件系统和瘦操作系统的专用数据存储服务器,提供跨平台的文件共享功能。通过 NFS、CIFS 等协议为用户提供一个文件系统视图。
+这一部分仅仅是作为一个引子,帮助我们将视角从传统的物理机进一步扩展到云。
+云存储能够支持远程保存数据和文件,并通过网络连接进行访问。云供应商负责托管、和维护相关的基础设施并提供访问性保证。不仅可以节约拓展物理器件所带来的人力物力消耗,并能够提供更好的弹性以便于即时增减容量,还支持按需按量付费从而做到更好的成本管理与控制。
+化繁为简,精心编排。
专设基础知识导读,即刻开启无痛学习。
能用 -> 易用 -> 好用。
以 Databend 为例,揭示现代云数仓特性。
在 Real World 中寻找版本答案。
透过 Databend 深入数据库设计与实现。
为 Databend 添砖加瓦。
一起学习如何为开源现代云数仓做贡献。
从 0 到 1 ,构建属于你的实时数仓。
从 Minibend 开始数据库内核研发之旅。
不定期的论文/技术研讨会。
关注数据库、分布式等相关领域新动态。
TLDR: 本站不使用 Cookies 且不收集任何个人数据。
+如果你有任何疑问,请随时联络 psiace@datafuselabs.com 进行沟通。
+生效日期: 2022 年 5 月 1 日
+ +