JVM=========================================================================================================
- 大对象,通过-XX:PretenureSizeThreshold可以指定大对象的标准
- 年龄超过一定数值的对象,通过-XX:MaxTenuringThreshold来设定年龄标准
- survivor空间中相同年龄的对象大小总和大于Survivor空间的一半,则年龄大于等于该年龄的对象可进入老年区
大部分的对象都是朝生夕灭的,所以应该把长时间存活的对象和短时间存活的对象分开管理,这也体现了分治的思想,分而治之,老年代负责存放年龄大的对象,新生代存放存活时间短的对象。
新生代使用的是标记复制算法,标记复制算法就是开辟两块survivor空间,一块eden空间,每次进行minor GC的时候就将一块s区的对象和e区的对象复制到另一块s区去,如果这块s区放不下了,就将对象晋升到老年区中去。
优点:不会产生内存碎片的问题
大部分对象的存活时间很短的话,复制的仅仅只需要占少部分对象,适合新生代
缺点:平时只能有90%的空间可以利用,浪费了10%的空间
如果对象大多都是活的,那么复制带来的性能损耗会很严重,并且复制浪费了10%的空间,这也是为什么老年代不使用标记-复制算法的原因
根据经验统计,在新生代中有98%的对象不能挺过第一次GC,所以不必1:1分配空间的。并且需要两块S区,才可以防止内存碎片问题,并且由于复制算法在大部分对象都是需要挥回收的情况下,效率是比整理算法高的,这也是新生代不采用整理算法的原因。
老年代使用的是标记整理算法,标记整理算法就是把存活的对象给移动到一端,保证内存空间连续,并且清除除这些以外的对象。移动对象的操作耗费性能,所以必须停止用户线程。为什么老年代采用的是这种算法而不是标记复制算法,标记复制算法必须要有10%的空间浪费,并且对存活时间长久的对象,操作损耗也会很严重,所以为了效率和空间,老年代更适合标记整理算法。
优点:不会产生内存碎片问题
缺点:必须暂停用户线程
在发生MinorGC之前,JVM会检查老年代最大的连续空间是否大于新生代所有对象的总空间,如果不成立的话会看-XX:HandlePromotionFailure参数是否设置成了允许担保失败,如果允许的话会检查老年代最大的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于的话进行MinorGC。如果小于或者不允许担保失败,则会进行一次FullGC
泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉,如在代码中定义List<Object>和List<String>等类型,在编译后都会变成List
public class Test {
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList<String>();
list1.add("abc");
ArrayList<Integer> list2 = new ArrayList<Integer>();
list2.add(123);
// 同为 class java.util.ArrayList
System.out.println(list1.getClass() == list2.getClass());
}
}- 强引用:是
Object obj = new Object()这种使用new方式创建出来的对象属于强引用,这种引用的方式是只要引用关系还在,GC的时候就不会清除 - 软引用:实现
SoftReference接口的,这类引用是还有用,但是没有必要的,只要没有内存溢出,就可以一直存在,在发生内存溢出错误之前,会将此类引用对象回收 - 弱引用:实现
WeakReference接口的对象,这类引用类似上面的软引用,但是不同的是此类引用无论当前内存是否足够,在进行GC的时候都会将其进行垃圾回收 - 虚引用:无实际意义,只是为了能够让对象在JVM进行GC的时候能够收到一个通知
记录数组的长度
JVM通过这个来确认这个对象是哪个类的实例
- hashcode
- GC分代年龄
- 锁状态标志
- 线程持有的锁
- 偏向线程ID
采用OOPMAP的数据结构,一旦类加载的动作完成之后,Hotspot会把对象内什么偏移量上是什么类型的数据计算出来
基于标记-清除算法,步骤有以下四步:
- 初始标记:把和GCROOT能直接关联的对象给标记起来,必须STW
- 并发标记:从GCROOT开始遍历对象图,把可达的对象都给标记起来,不用STW
- 重新标记:防止并发标记过程,用户线程改变了对象引用,所以会进行修正的一个标记,必须STW
- 并发清除:将上面的标记过程中判定死亡的对象进行清除,不用STW
并发收集、低停顿
- 并发标记的时候会占用CPU的一部分的计算能力导致用户进程变慢
- 无法清除浮动垃圾,浮动垃圾就是由于CMS在并发清理的时候,用户线程没有STW,所以也可能产生垃圾,这部分就叫做浮动垃圾。这部分垃圾就会等着下一次GC的时候进行清理
- 空间碎片:由于CMS基于“标记-清除”算法,所以可能会造成空间碎片的问题,如果碎片过多,分配大对象的时候就没有空间,那么只有触发full gc才能清理
G1的混合回收过程可以分为标记阶段、清理阶段和复制阶段。
- 初始化标记:和CMS一样,将和GCROOT对象直接关联的对象进行标记,必须STW
- 并发标记阶段:并发标记阶段是指从GC Roots开始对堆中对象进行可达性分析,找出存活对象。该阶段是并发的,即应用线程和GC线程可以同时活动。并发标记耗时相对长很多,但因为不是STW,所以我们不太关心该阶段耗时的长短。
- 再标记阶段:重新标记那些在并发标记阶段发生变化的对象。该阶段是STW的。
- 清理阶段:清点出有存活对象的分区(Region)和没有存活对象的分区(Region),统计各个Region的回收成本根据用户指定的STW时间(默认为200ms)来指定回收计划,该阶段不会清理垃圾对象,也不会执行存活对象的复制。该阶段是STW的。
- 将决定回收的Region中存活对象复制到空的Region中,清理掉旧的Region的全部空间
- 不会产生内存碎片:整体的清除算法是基于“标记-整理”算法,局部(从Region看)是采用的”标记-复制“算法的,但是这两者都不会产生内存碎片的问题
- region 大小和大对象很难保证一致,这会导致空间的浪费。特别大的对象是可能占用超过一个 region 的。并且,region 太小不合适,会令你在分配大对象时更难找到连续空间,这是一个长久存在的情况。
- 处理跨代引用的时候,记忆集更大
MySQL=========================================================================================================
参考ICP和MRR
给表(id,a,b,c)中(a,b,c)起一个联合索引的话,如果执行下面的语句
select * from table where a=1 and b>1 and c=1这个如果使用索引下推的话,查询的过程就是,首先在a索引遍历的时候,同时b会进行一个过滤,都是在非主键索引b+树中完成的,减少了回表的次数。
这个SQL走索引的情况
查询的字段有索引,走行锁,没有索引走表级锁。
- 使用or的时候,所有待匹配字段必须全加上索引,否则不走索引
- like以%开头的不走索引
- 复合索引没有使用最左列的时候不走索引
- 需要类型转换,比如待匹配字段为字符串,但是实际上给的条件为数字,不走索引
- where子句中对索引列进行运算即select * from table where a+1=5,此时不走索引,应该改成a=4才会走索引(a加上了索引的情况)
- where子句中使用了函数,不走索引
- 在数据量比较少的情况下,使用索引反而会增大消耗,所以mysql在数据量小的情况下进行的是全表扫描而非索引
可参考binlog格式
mysql支持用户自定义redolog什么时候从log buffer刷到磁盘中去,通过设置innodb_flush_log_at_trx_commit,而这个参数有三个值:0,1,2。
- 事务提交的时候把log buffer每秒写入os buffer然后调用
fsync()将os buffer中的日志持久化到磁盘上的redolog ,如果mysql挂掉的时候,会丢失大约1s的数据。 - 默认的参数,每次事务提交的时候都写入os buffer 并且调用
fsync()将redolog持久化到磁盘上,系统崩溃也不会出现丢失,但是IO性能比较差 - 设置为2的时候,每次提交都仅仅写入os buffer,不会写入log buffer,每秒的调用
fsync()将redolog持久化到硬盘上
Java=========================================================================================================
- nums.length < 47 使用插入排序
- 47 < nums.length < 286 进行快速排序
- nums.length > 286 进行归并排序,归并排序之前会看数组是否高度结构化(即有序部分的数组多不多),每次遇到这样的数组就把cnt+1,当cnt大于67,表示不具备结构,则使用快排,否则使用归并排序
在使用SimpleDateFormater的时候会导致多线程环境下的日期出错,因为这个类调用parse()方法的话,会导致其他的线程时间被clear,导致时间不对,所以我们需要在每一个线程都new一个simpledateformater对象,但是可以使用ThreadLocal的initialvalue来给每一个线程创建一个副本,提高了性能
在调用set()方法的时候,会调用getMap(),返回的是当前线程的threadLocals对象,其实就是每个线程都会创建一个ThreadLocalMap对象,然后get()或者set()的时候,就给当前线程的ThreadLocalMap加值和取值
public void set(T value) {
// 获取当前的线程
Thread t = Thread.currentThread();
// 获取当前线程ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null) {
map.set(this, value);
} else {
createMap(t, value);
}
}
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
// ThreadLocalMap的key-value 是 ThreadLocal 和 Entry
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}虽然叫Map,但是并没有实现Map接口,只有一个Entry数组,而且它的Entry是弱引用的,解决hash冲突的方式是使用线性探测法
实际是以ThreadLocal为key,然后value即set进来的值
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k); // 继承了弱引用,所以这里以一个弱引用指向ThreadLcoal对象k
value = v;
}
}ThreadLocal是被ThreadLocalMap以弱引用的方式关联着,因此如果ThreadLocal没有被ThreadLocalMap以外的对象引用,则在下一次GC的时候,ThreadLocal实例就会被回收,那么此时ThreadLocalMap里的一组KV的K就是null了,因此在没有额外操作的情况下,此处的V便不会被外部访问到,而且只要Thread实例一直存在,Thread实例就强引用着ThreadLocalMap,因此ThreadLocalMap就不会被回收,那么这里K为null的V就一直占用着内存。
如果一个线程死亡了,ThreadLocal应该被GC,内存泄漏就发生在服务器使用线程池一直使用这个线程,导致无法被回收
ThreadLocal.set(null)也会引起内存泄漏
如果Entry设置为强引用的话,那么就会出现Entry回收不了的情景
- 使用虚拟机进程状况工具jps,确定频繁Full GC现象
- 使用jmap,找出导致频繁Full GC的原因
- 使用MAT查看,定位到代码
这个问题就牵扯到了两个概念:
在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。原因是迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变 modCount 的值。迭代器在访问下一个值的时候都会看这个modCount是不是期待的modCount,如果不是就会抛出异常
// java.util.ConcurrentModificationException
for (Iterator<Integer> i = list.iterator(); i.hasNext(); ) {
Integer element = i.next();
list.remove(element);
}上面的删除方式是错误的,不能在使用迭代器的同时操作list删除元素
复制原来的容器,然后对新的容器进行迭代,在CurrentHashMap、CopyOnWriteArrayList就不会出现这种异常。
由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到
底层其实就是个HashMap,key就是add()方法的参数,而value是一个新建的Object对象
可能会导致内存泄漏,一个对象在被加入HashSet之后,就不能改变对应的对象的HashCode了,否则不能找到这个对象,从而导致内存泄漏
public class HashSetTest {
public static void main(String[] args) {
Set<Person> set = new HashSet<Person>();
Person p1 = new Person("唐僧", "pwd1", 25);
Person p2 = new Person("孙悟空", "pwd2", 26);
Person p3 = new Person("猪八戒", "pwd3", 27);
set.add(p1);
set.add(p2);
set.add(p3);
System.out.println("总共有:" + set.size() + " 个元素!"); //结果:总共有:3 个元素!
p3.setAge(2); //修改p3的年龄,此时p3元素对应的hashcode值发生改变
set.remove(p3); //此时remove不掉,造成内存泄漏
set.add(p3); //重新添加,居然添加成功
System.out.println("总共有:" + set.size() + " 个元素!"); //结果:总共有:4 个元素!
for (Person person : set) {
System.out.println(person);
}
}
}
public class Person {
private String username;
private String password;
private int age;
// ignored getter/setter and full-args constructor and toString()
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((password == null) ? 0 : password.hashCode());
result = prime * result + ((username == null) ? 0 : username.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (password == null) {
if (other.password != null)
return false;
} else if (!password.equals(other.password))
return false;
if (username == null) {
if (other.username != null)
return false;
} else if (!username.equals(other.username))
return false;
return true;
}
}- HashMap线程不安全,后者线程安全
- HashMap继承自AbstractMap抽象类,而HashTable继承Dictionary抽象类
- Hashtable的初始长度是11,之后每次扩充容量变为之前的2n+1(n为上一次的长度),而HashMap的初始长度为16,之后每次扩充变为原来的两倍
- Hashtable直接使用对象的hashCode,HashMap的hash算法是 key.hashcode^(key.hashcode>>>16);
- 使用ProcessBuilder的start()方法创建进程
- 使用Runtime的exec(String cmdarray[])方法创建进程
Spring=========================================================================================================
- singleton:不写的话默认也是这个,这个的意思就是,单例的,就是说,不管你new多少次,都是一个对象
- prototype:就是说每次new一个bean都是一个新的对象
- request:仅用于WebApplicationContext环境,即每个HTTP请求都会有各自的bean实例
- session:仅用于WebApplicationContext环境,同一个session共用一个bean,不同的session用不同的bean
- globalsession:仅用于WebApplicationContext环境
// Prepare this context for refreshing.
// 准备工作,记录下容器的启动时间、标记“已启动”状态、处理配置文件中的占位符
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
/*
这步比较关键,这步完成后,配置文件就会解析成一个个 Bean 定义,注册到 BeanFactory中,
当然,这里说的 Bean 来了,
注册也只是将这些信息都保存到了注册中心(说到底核心是一个还没有实例化,只是配置信息都提取出 beanName->beanDefinition 的 map)
*/
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
// 设置 BeanFactory 的类加载器,添加几个 BeanPostProcessor,手动注册几个特殊的bean
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
// Bean 如果实现了此接口,那么在容器初始化以后,
// Spring 会负责调用里面的 postProcessBeanFactory 方法。
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
// 执行 BeanFactoryPostProcessor 实现类的 postProcessBeanFactory(factory)的方法
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
// 注册beanPostProcessors,不是BeanFactoryPostProcessor
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
// 初始化所有的 singleton beans
// bean的生命周期在这个方法中得到了体现
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();https://juejin.im/post/5da7a0555188257a7306822d
使用ClasspathXmlApplicationContext启动时
- 调用父容器的构造方法为容器设置好 Bean 资源加载器
- 设置传进去的配置文件的路径,即XML文件的路径
- 刷新容器,此时会对实例对象属性上锁,即Object,防止另外一个ApplicationContext创建的时候再刷新导致线程安全的问题
- 设置 “正在创建”标记,校验XML文档
- 销毁之前的创建的容器,使用DefaultListableBeanFactory创建新的容器
- 通过loadBeanDefinitions()这个方法将Bean加载到BeanFactory中,通过给出的BeanFactory来创建XmlBeanDefinitionReader进而将BeanDefinition加载到BeanFactory中
- 使用XmlBeanDefinitionReader调用真正的加载方法,即loadBeanDefinitons()来执行真正的加载
- 通过XML文档解析器将Bean的配置写入BeanDefinition中,并且放进一个BeanName -> BeanDefinition的Map中去,真正的类加载的过程在之后进行
-
开始是单例的话要先清除缓存;
-
实例化bean,将BeanDefinition转换为BeanWrapper;createBeanInstance()
-
使用MergedBeanDefinitionPostProcessor,
@Autowired注解就是通过此方法实现类型的预解析 -
解决循环依赖问题;可参考Spring管理循环依赖
// 用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用 private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); // 存放 bean 工厂对象,用于解决循环依赖 private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16); // 存放原始的 bean 对象(尚未填充属性),用于解决循环依赖 private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
protected Object getSingleton(String beanName, boolean allowEarlyReference) { // 用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用 Object singletonObject = this.singletonObjects.get(beanName); // 获取的单例bean为空以及特殊的bean正在创建中 if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { synchronized (this.singletonObjects) { // 没有填充属性的bean,仅仅只是实例化了的对象 singletonObject = this.earlySingletonObjects.get(beanName); // 如果这也没找到 if (singletonObject == null && allowEarlyReference) { // 从 singletonFactories 中获取 objectFactory ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName); if (singletonFactory != null) { // 从objectFactory中获取object singletonObject = singletonFactory.getObject(); this.earlySingletonObjects.put(beanName, singletonObject); this.singletonFactories.remove(beanName); } } } } return singletonObject; }
总结上面的代码就是
- 先去singletonObjects中找,如果找到了就返回,此时的bean是已经填充好属性的bean了
- 如果没找到就去earySingletonObjects中找,如果找到了就返回,此时的bean是实例化但是没有填充属性的bean
- 如果没找到就去对应的ObjectFactory中实例化一个,并且将当前的ObjectFactory从map中移除,并且加到还没有填充属性,但是已经实例化的容器中。
- 如果还没找到的话返回null,此时会抛出异常
解决循环依赖的解决办法是:
- 首先A提前将自己曝光到
singletonFactories中去 - 然后发现自己依赖对象B,就去获取B的对象,发现对象B还没有被创建,所以创建B
- 创建B的时候将自己曝光到
singletonFactories中去 - 发现自己依赖对象A,就去获取对象,从
singletonFactories获取创建A的ObjectFactory,创建A,然后放到earlySingletonObjects,然后注入A到B中去 - 然后将B放到
singletonObjects中去,最后将A放到singletonObjects中去,循环依赖解决完成。
-
填充属性,将属性填充到bean实例中,populateBean()
-
调用initializeBean
-
注册DisposableBean;
-
创建完成并返回
所以综上所述可以得到:
- 实例化Bean
- 填充属性,即属性注入
- 如果bean实现了Aware接口,就会调用不同的aware接口的方法,可以设置beanName等功能,不同的aware接口也有不同的功能
- 前置BeanPostProcessor调用,这一步是在初始化之前
- 检查是否实现了InitializingBean接口和afterPropertiesSet方法,如果都实现了,就调用afterPropertiesSet()方法
- 检查是否配置了init-method属性,配置了就调用
- 后置BeanPostProcessor调用
- 注册必要的Destruction相关回调接口
- 使用
- 是否实现了DisposableBean接口
- 是否自定义了destroy()方法
- 调用destroy-method方法 ,这一步使用了适配器模式
创建
- 如果你使用
BeanFactory作为Spring Bean的工厂类,则所有的bean都是在第一次使用该Bean的时候实例化 - 如果你使用ApplicationContext作为Spring Bean的工厂类,则又分为以下几种情况:
- 如果bean的scope是
singleton的,并且lazy-init为false(默认是false,所以可以不用设置),则ApplicationContext启动的时候就实例化该Bean,并且将实例化的Bean放在一个map结构的缓存中,下次再使用该Bean的时候,直接从这个缓存中取 - 如果bean的scope是
singleton的,并且lazy-init为true,则该Bean的实例化是在第一次使用该Bean的时候进行实例化 - 如果bean的scope是
prototype的,则该Bean的实例化是在第一次使用该Bean的时候进行实例化
- 如果bean的scope是
销毁
singleton在容器销毁的时候被回收
prototype是在未被引用的情况下被JVM回收
ApplicationContext 继承自 BeanFactory,但是它不应该被理解为 BeanFactory 的实现类,而是说其内部持有一个实例化的 BeanFactory(DefaultListableBeanFactory)。以后所有的 BeanFactory 相关的操作其实是委托给这个实例来处理的。
BeanFactory中能完成的功能,ApplicationContext都能完成,并且还能完成BeanFactory没有的功能,比如加载资源文件的能力、发布事件给注册监听器的能力、国际化的能力
在Spring框架中,只要实现了BeanPostProcessor,就会调用这个接口的方法,所以自动注入就是通过这个方式来切入的。
主要的实现类是AutowiredAnnotationBeanPostProcessor,这个类实现了MergedBeanDefinitionPostProcessor接口,这个接口的方法postProcessMergedBeanDefinition调用是在doCreateBean的时候会调用,然后找到这个注解的元数据进行注入,不过不支持静态方法
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
// 找到元数据
InjectionMetadata metadata = findAutowiringMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
}
private InjectionMetadata findAutowiringMetadata(String beanName, Class<?> clazz, @Nullable PropertyValues pvs) {
// Fall back to class name as cache key, for backwards compatibility with custom callers.
String cacheKey = (StringUtils.hasLength(beanName) ? beanName : clazz.getName());
// Quick check on the concurrent map first, with minimal locking.
InjectionMetadata metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
synchronized (this.injectionMetadataCache) {
metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
if (metadata != null) {
metadata.clear(pvs);
}
// 前面的就是从缓存获取
// 绑定自动注入的属性
metadata = buildAutowiringMetadata(clazz);
this.injectionMetadataCache.put(cacheKey, metadata);
}
}
}
return metadata;
}
private InjectionMetadata buildAutowiringMetadata(final Class<?> clazz) {
List<InjectionMetadata.InjectedElement> elements = new ArrayList<>();
Class<?> targetClass = clazz;
do {
final List<InjectionMetadata.InjectedElement> currElements = new ArrayList<>();
ReflectionUtils.doWithLocalFields(targetClass, field -> {
AnnotationAttributes ann = findAutowiredAnnotation(field);
if (ann != null) {
// 不支持静态属性的注入
// log
// require 属性
boolean required = determineRequiredStatus(ann);
currElements.add(new AutowiredFieldElement(field, required));
}
});
ReflectionUtils.doWithLocalMethods(targetClass, method -> {
Method bridgedMethod = BridgeMethodResolver.findBridgedMethod(method);
if (!BridgeMethodResolver.isVisibilityBridgeMethodPair(method, bridgedMethod)) {
return;
}
AnnotationAttributes ann = findAutowiredAnnotation(bridgedMethod);
if (ann != null && method.equals(ClassUtils.getMostSpecificMethod(method, clazz))) {
// log
return;
}
// log
boolean required = determineRequiredStatus(ann);
PropertyDescriptor pd = BeanUtils.findPropertyForMethod(bridgedMethod, clazz);
currElements.add(new AutowiredMethodElement(method, required, pd));
}
});
elements.addAll(0, currElements);
targetClass = targetClass.getSuperclass();
}
while (targetClass != null && targetClass != Object.class);
return new InjectionMetadata(clazz, elements);
}- 开启一个计时器
- 从Spring.factories文件中加载监听器,发布应用启动开始的事件
- 设置输入的参数(main方法的args)
- 配置环境(profile)
- 根据不同的web环境,创建ApplicationContext,比如如果是servlet环境的话,创建
AnnotationConfigServletWebServerApplicationContext - 预处理ApplicationContext,为刚创建的容器对象做一些初始化工作
- 刷新ApplicationContext,注册BeanPostProcessor,调用BeanFactory的后置处理器
- 执行刷新容器后的后置处理逻辑(为空方法)
- 调用CommandLineRunner和ApplicationRunner接口的Run方法
- 返回容器对象
上面的启动流程中
- 在刷新ApplicationContext的步骤中,调用了refresh()方法
- 而这个refresh()方法调用了onRefresh()方法,这个方法是交给子类去实现的
- 而在ServletWebServerApplicationContext中实现了这个方法(onRefresh())
- 并且这个子类的实现的方法调用了createWebServer()
- createWebServer()调用了TomcatServletWebServerFactory的getWebServer()方法
- getWebServer()返回了一个新建的TomcatWebServer对象
- 而在这个TomcatWebServer对象的构造方法调用了initialize()方法
- initlize()方法调用了tomcat的start()方法,启动了Tomcat服务器
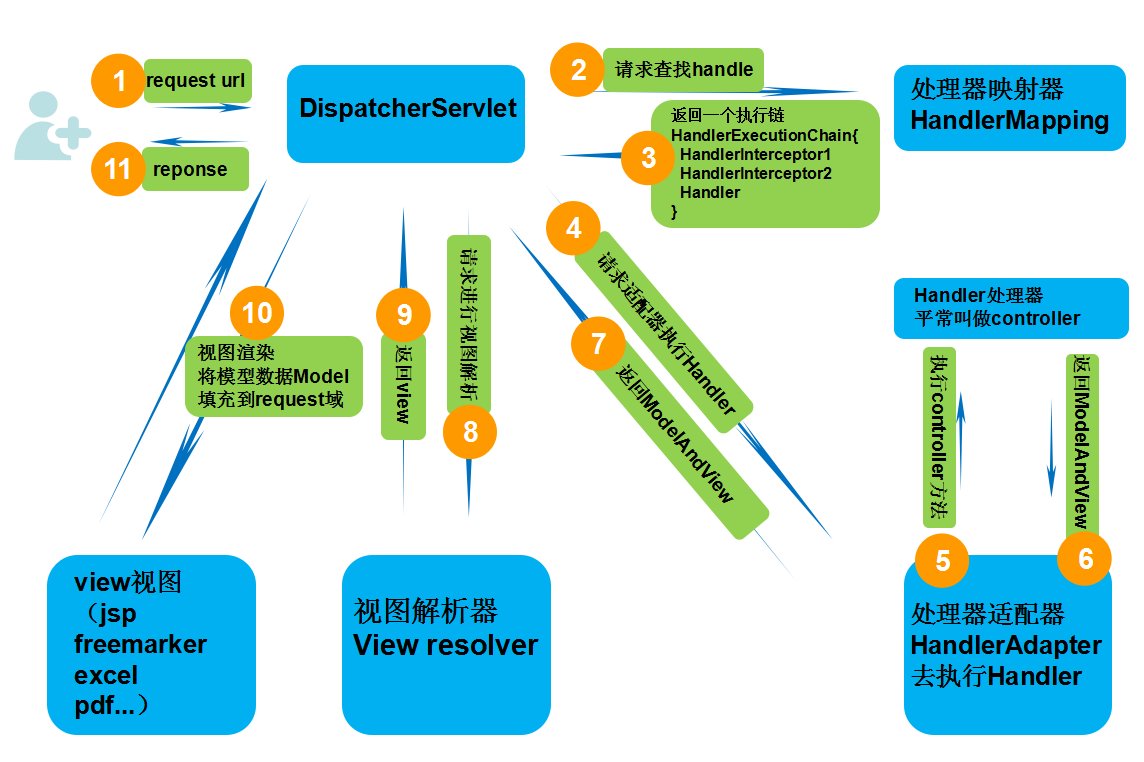
主要运用了DispatcherServlet,处理流程如下:
- 请求到了DispatcherServlet之后,会根据路径在HandlerMapping去找到对应的处理器执行链(HandlerExecutionChain),并且返回给DispatcherServlet
- HandlerMapping会把请求映射为一个Handler处理链即 一个Handler,多个HandlerInterceptor,采用了策略模式
- 返回给DispatcherServlet之后,就去找对应HandlerAdapter,由HandlerAdapter去找对应的控制器即Controller
- Controller返回ModelAndView给HandlerAdapter,并且返回给Dispatcher
- 由DispatcherServlet去找视图解析器,返回view
- DispatcherServlet根据view去寻找视图文件返回给前端
调用接口:HandlerMapping
在 DispatchServlet 中,springboot 注册了一个 HandlerMapping 列表。请求过来时,会循环该列表,来解析url获取handler方法,获取到之后即跳出循环。
调用接口:HandlerMethodArgumentResolver 在 InvocableHandlerMethod 中,springboot 注入了一个 HandlerMethodArgumentResolverComposite 对象,该对象中有多个解析器放在列表中,解析参数时同样是循环列表,来找出第一个可以解析的解析器进行解析。
调用接口:HandlerMethodReturnValueHandler
在 ServletInvocableHandlerMethod 中,springboot 注入了一个HandlerMethodReturnValueHandlerComposite 对象,该对象中有多个返回值处理器在列表中,处理返回值时,首先同样是循环列表,找到处理器,再进行返回值处理。
- 回滚的时候没有抛出RuntimeException而是其他的异常,回滚失效
- 调用了没加@Transactional注解的方法
- 没有抛出异常,被catch掉了
- 拦截器基于反射实现,过滤器基于函数的回调
- 拦截器不依赖于servlet容器,而过滤器依赖servlet容器
- 拦截器不能拦截文件请求,而过滤器可以过滤文件请求
- 拦截器能获取IOC的bean,而过滤器不行(正常情况下)
Netty=========================================================================================================
操作系统在进行TCP通信的时候,会有一个缓冲区,如果一次请求发送的数据量比较小,没达到缓冲区大小,TCP则会将多个请求合并为同一个请求进行发送,这个叫做粘包;如果太大了超过了缓冲区,则会进行拆包
实现FixedLengthFrameDecoder解码器,这个解码器会每次读取固定长度的消息,如果当前读取的消息长度不足指定消息长度,则会等下一个消息到达之后进行补足
Redis=========================================================================================================
在redis集群当中,一个客户端获取了一个分布式锁,此时redis的主机挂掉了,从机顶替上来成为了主机,分布式锁怎么样呢?
这个就是redlock算法需要解决的问题了,在加锁的时候,主机会向过半的从机发送set(key,value,nx=True,ex=xxx)指令,只要过半的节点set成功了,就说明加锁成功,在归还锁的时候,主机向所有的节点发送del指令。当然细节不仅仅只是这些,还有重试等等细节。
首先做一个快照同步再做一个增量同步
将指令存到本机的内存buffer中,发送这些指令给从机,从机一边执行主机发送过来的指令流,一边向主机反馈自己的执行进度。
由于内存buffer是环形的数组,如果指令太多了,后面的指令会覆盖前面的指令,在网络拥塞的时候很可能就会发生指令丢失的情景。
使用bgsave指令,将当前的内存数据存放在磁盘上,然后发送给从机,从机在接收完成之后,会立马将当前内存数据清空,并且进行一个全量加载,然后通知主机做增量同步。
在快照同步的时候,同时主机也在写内存buffer准备增量同步,所以也可能会造成指令覆盖的问题,这就会造成快照同步之后无法进行增量同步,从而从机又会发起快照同步,形成死循环,解决这个问题的关键是设置正确buffer的大小
如果队列为空,那么使用lpop/rpop 会导致cpu空转,如果有很多客户端都在发送这个指令的话,Redis的QPS会很高。解决办法:让客户端的线程休眠一定的时间。
但是休眠线程之后会导致消息接收有延迟,所以使用阻塞pop也就是brpop/blpop,没有数据会自动休眠,有数据会立刻醒过来。
但是如果阻塞的太久了,redis会认为这个连接是一个闲置连接,会自动断开这个连接,断开之后再使用brpop/blpop会抛出异常。
Redis会将设置了过期时间的key放在一个字典里面,然后定时遍历(10s)这个字典,删除过期的key
除了定时遍历还会采用惰性删除的方法,惰性删除:在客户端访问一个key的时候,redis检测这个key有没有过期,如果过期了,就会删除,并且告诉客户端这个key过期了。
每10s遍历一次字典
- 从字典中选取20个key
- 删除这20个key的过期的key
- 如果过期的key超过了1/4,就会重复步骤1,当然上面可能会出现死循环,所以redis设置了扫描时间的上限为25s,如果扫描时间超过了25s就会退出扫描。
在conf文件中可以看到下面的内存淘汰策略
volatile-lru -> 从过期的key中挑选最久未使用,没有设置过期时间的key不会被淘汰,这样就可以在增加内存空间的同时保证需要持久化的数据不会丢失。
allkeys-lru -> 从所有的key中lru
volatile-lfu -> 从过期的key中lfu (最小频率访问的数据最先被淘汰)
allkeys-lfu -> 所有的key挑选lfu
volatile-random -> 从设置了过期时间的数据集中随机挑选淘汰
allkeys-random -> 在所有的key中随机挑选一个淘汰
volatile-ttl -> 从设置过期时间的数据集,从中挑选将要过期的数据淘汰,ttl值越大越优先被淘汰。
noeviction -> 报错
int select (int n/* */, fd_set *readfds/* 读文件标识符 */, fd_set *writefds/* 写文件标识符 */, fd_set *exceptfds/* 异常文件标识符 */, struct timeval *timeout/* 超时时间 */);一个socket就是一个fd(文件描述符),而上面的readfds、writefds、exceptfds是位图的数据结构。
假如说fd有5个,且数据分别是 2 1 3 4 5,那么readfds可以表示成 011111,及第一位有数据、第二位有数据、第三位有数据·······,在调用select函数的时候,操作系统会将readfds拷贝一份到内核态,让内核态来进行判断对应的fd有没有数据,有数据就将readfds对应的位置为1,置位完成就返回,当select函数返回后,可以通过遍历fd_set,来找到就绪的描述符
缺点:内核态和用户态拷贝需要开销、bitmap最大是1024位、fd_set不可重用
int poll (struct pollfd *fds, unsigned int nfds, int timeout);struct pollfd{
int fd; /* 和上面的fd是一样的 */
short events; /* 对fd是写还是读 */
short revents; /* 对events的反馈 */
}和select一样,拷贝完成之后在内核态置pollfd.revents,然后返回,对fd_set进行遍历查看哪个是就绪的。
从上面看,select和poll都需要在返回后,通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
3. epoll
int epoll_create(int size);创建一个监听的数目的大小
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);对对应的fd进行操作
多线程=========================================================================================================
独占式获取资源
首先当前线程会尝试获取同步状态,如果获取同步状态失败了就会生成一个Node节点使用尾插法用CAS插入CLH队列当中去,然后就会开始自旋,在队列当中的每一个节点都是会自旋的去获取同步状态,如果当前节点的前驱节点不是头节点的话,就会进入等待状态,直到线程被中断或者前驱节点被释放,才会去进行自旋,如果前驱节点是头节点的话,就去尝试获取同步状态,如果获取失败了,就会让进程进入等待状态,如果获取成功,则会将当前节点设置为头节点。
共享式
底层使用MonitorEnter和MonitorExit来控制锁的获取以及释放。提一句,wait和notify也是通过这种方式来进行线程的唤醒和堵塞,所以wait才只能在同步块中进行调用。
锁的分类:无锁、偏向锁、轻量级锁、重量级锁。
下面就是对象头中的Mark Word的存储内容
| 锁状态 | 29 bit 或 61 bit | 1 bit 是否是偏向锁? | 2 bit 锁标志位 |
|---|---|---|---|
| 无锁 | 0 | 01 | |
| 偏向锁 | 线程ID | 1 | 01 |
| 轻量级锁 | 指向栈中锁记录的指针 | 此时这一位不用于标识偏向锁 | 00 |
| 重量级锁 | 指向互斥量(重量级锁)的指针 | 此时这一位不用于标识偏向锁 | 10 |
| GC标记 | 此时这一位不用于标识偏向锁 | 11 |
无锁就是没有锁的意思。
偏向锁:锁总是偏向于第一次获取锁的线程。在锁的对象头的mark word中,有一个记录偏向锁的位置,存放的是线程的ID。如果一个线程遇见锁(synchronized)了,会去检查锁的对象头的偏向锁的记录是不是当前的线程ID,如果是的话,就直接略过锁不用CAS来进入和退出锁,如果不是的话,就表明有线程竞争,那就使用CAS来替换偏向锁记录的线程ID为当前的线程ID,成功了的话就不会进行锁升级,如果失败的话就进行锁升级。
轻量级锁:不存在锁竞争,没有线程堵塞。栈的局部变量表中有存放对象的引用,也可以理解为一种指针。所以在检测到是轻量级锁的情况之后,JVM会把锁对象的Mark Word复制到自己新建的用于存储锁的记录空间,然后线程就尝试使用CAS来改变轻量级锁中Mark Word中指向栈帧的锁记录的指针,如果成功了就表示当前的线程获得到了锁,如果失败了就一直自旋等待获取锁的线程释放锁,但是不会一直自旋,如果自旋了很久就升级成重量级锁。
重量级锁:使用操作系统的互斥量(mutex)实现的,一个线程获取锁,其他的线程堵塞。上面自旋的线程进行阻塞,等待之前线程执行完成并唤醒自己
上面都已经说过了,这里概括一下。
- 一个线程在获取共享资源的时候,会检查锁的对象头的Mark word中的偏向锁存放的是不是自己的线程ID,如果是的话就为偏向锁,如果不是就使用CAS来替换线程ID,如果成功了就不会锁升级,失败了通知之前线程暂停,之前线程将Markword的内容置为空,进行锁升级
- 使用CAS的方式来替换Mark Word中指向栈帧中锁记录的指针,成功了就表示获取了锁,失败了就一直自旋,如果自旋了很久了就会升级成重量级锁。
- 临界区只能有一个线程在执行
- synchronized无法知道线程是否获取到锁
- 临界区因为IO或者sleep方法等原因阻塞了,当前线程也没有释放锁就会导致所有的线程被阻塞
| newCachedThreadPool | newFixedThreadPool | newSingleThreadExecutor | newScheduledThreadPool |
|---|---|---|---|
| 不会创建核心线程,线程池最大的大小是Integer.MAX_VALUE | 核心线程数量和总线程数量相等,都是传入的参数nThreads | 有且仅有一个核心线程 | 创建一个定长线程池,支持定时及周期性任务执行。 |
| 只能创建核心线程 | |||
| 采用SynchronousQueue | 采用LinkedBlockingQueue | 使用了LinkedBlockingQueue(容量很大) | 采用了DelayedWorkQueue |
ThreadPoolExecutor在创建线程时,会将线程封装成工作线程worker,并放入工作线程组中,然后这个worker反复从阻塞队列中拿任务去执行。
- 前者为减法计数器,后者为加法计数器
- 前者是调用countdown()方法的线程不会被阻塞,等到计数器为0的时候,才会让调用await()方法的线程继续运行,而后者是将调用await()方法的线程都加入到阻塞队列,只有阻塞队列的长度到加法计数器指定的数字的时候,才会按照FIFO的算法从阻塞队列中调度线程
参考银行的业务办理流程。
AbortPolicy:抛出异常
CallerRunsPolicy:只用调用者所在的线程来运行任务;如果执行程序已关闭,则会丢弃该任务
DiscardOldestPolicy:该策略将丢弃最老(队列前面的任务)的一个线程请求,并且运行来的任务
DiscardPolicy:默认情况下将丢弃被拒绝的任务,丢弃将要加入队列的任务
https://blog.csdn.net/u011389515/article/details/80656813
线程池处在RUNNING状态时,能够接收新任务,以及对已添加的任务进行处理。
线程池的初始化状态是RUNNING。换句话说,线程池被一旦被创建,就处于RUNNING状态,并且线程池中的任务数为0
线程池处在SHUTDOWN状态时,不接收新任务,但能处理已添加的任务。
调用线程池的**shutdown()**方法时,线程池由RUNNING -> SHUTDOWN
线程池处在STOP状态时,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。
调用线程池的**shutdownNow()**方法时,线程池由(RUNNING or SHUTDOWN ) -> STOP
当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING状态。
ThreadPoolExecutor中有一个控制状态的属性叫ctl,它是一个AtomicInteger类型的变量。
当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理,可以通过重载terminated()函数来实现。
当线程池在SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由 SHUTDOWN -> TIDYING。 当线程池在STOP状态下,线程池中执行的任务为空时,就会由STOP -> TIDYING。
线程池彻底终止,就变成TERMINATED状态。
线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING -> TERMINATED。
处于NEW状态的线程此时尚未启动。这里的尚未启动指的是还没调用Thread实例的start()方法。
反复调用同一个线程的start()方法是否可行?
假如一个线程执行完毕(此时处于TERMINATED状态),再次调用这个线程的start()方法是否可行?
在start()内部,这里有一个threadStatus的变量。如果它不等于0,调用start()是会直接抛出异常的,在调用一次start()之后,threadStatus的值会改变。所以都不行。
包括running和ready状态
线程正在等待一个事件结束,比如一个线程遇见synchronized就要等待别的线程释放这个锁
调用了wait()方法就是这个状态,如果别的线程没有调用notify()或者notifyAll()就会一直是这个状态
调用sleep()方法就变成这个状态,等待一段时间之后,拥有了争抢锁的资格。
线程终止状态
线程状态转换图

当前CPU正在运行此进程
条件都有,等待CPU来运行了
等待某个事件完成,没有运行条件

每个线程都有自己的工作空间,需要数据的话就去主存取,改变完成之后就将这个值放回主存,这也就是voliate关键字产生的原因。
前置知识
为了同步处理器和内存的访问速度,所以需要缓存,然后再将缓存当中的数据放入内存当中,如果加了voliate关键字的话,JVM就会告诉CPU要将缓存当中的数据放入内存当中去了。
原因
上面的操作也是会有问题的,一个线程处理好的数据放回内存当中之后,别的线程也不知道这个值是不是改变了,所以就有下面的机制。
总线嗅探,每个处理器通过嗅探总线上传播的数据来判断自己的缓存是否过期了,如果过期了就将自己的缓存行设置为过期,当处理器对这个数据进行处理的时候从内存当中取值放到缓存当中
RocketMQ=========================================================================================================
采用幂等性,在redis中维护一个set,如果被消费了就把消息的id放进redis,如果没有消费就消费。
计算机网络=========================================================================================================
100:这个状态码是告诉客户端应该继续发送请求
200:这个是最常见的http状态码,表示服务器已经成功接受请求,并将返回客户端所请求的最终结果
202:表示服务器已经接受了请求,但是还没有处理,而且这个请求最终会不会处理还不确定
204:服务器成功处理了请求,但没有返回任何实体内容 ,可能会返回新的头部元信息
301:客户端请求的网页已经永久移动到新的位置
302:客户端请求的网页已经暂时移动到新的位置
303:该状态码表示由于请求对应的资源存在着另一个URL,应使用GET方法定向获取请求的资源
404:请求失败,客户端请求的资源没有找到或者是不存在
主要功能是为应用软件提供了不同的服务,比如电子邮件有SMTP协议、POP协议,远程登陆有SSH协议,文件传输有FTP协议
将应用处理的信息转换成能够网络传输的格式,或者将下一层的数据转换成上层能够处理的格式。所以主要功能是进行数据格式的转换。
主要功能是控制连接的建立和断开的时机,以什么方式建立连接
TCP/UDP协议就在这一层用来管理两个节点的数据传输,保证传输的可靠性,UDP是不可靠的,实际的管理两个节点的连接和关闭
地址管理和路由选择,主要是IP协议,两个主机通过网络连接,那么如何互相找到主机的位置就是网络层做的事
在这些通过网络介质相连的设备进行传输,主要有arp协议,arp协议是将IP地址映射为MAC地址,局域网进行数据通信靠的就是MAC地址
将数据的01转换成电压和脉冲光的传输介质
参考HTTP版本比对
- 只支持
GET请求方式:由于不支持其他请求方式,因此客户端是没办法向服务端传输太多的信息 - 没有请求头概念:所以不能在请求中指定版本号,服务端也只具有返回 HTML字符串的能力
- 服务端相响应之后,立即关闭TCP连接
- 新增了请求方式,POST,HEAD等方式
- 增添了请求头和响应头的概念,在通信中指定了 HTTP 协议版本号,以及其他的一些元信息 (比如: 状态码、权限、缓存、内容编码)
- 扩充了传输内容格式,图片、音视频资源、二进制等都可以进行传输
- 不可复用TCP连接,即一次HTTP连接就需要进行一次三次握手和四次挥手
- 长连接:可以设置Connection: keep-alive保持长连接
- 管道化:后面的请求不用关心前面的请求响应,发送当前请求就可以了
- 缓存处理:当浏览器请求资源时,先看是否有缓存的资源,如果有缓存,直接取,不会再发请求
- 断点传输
- 新增PUT、DELETE、OPTIONS等请求方式
- 可能会造成队头阻塞
- 二进制分帧
- 多路复用: 在共享TCP连接的基础上同时发送请求和响应
- 头部压缩
- 服务器推送:服务器可以额外的向客户端推送资源,而无需客户端明确的请求
https采用了混合加密的模式:非对称加密和共享公钥加密
- 首先服务器向证书认证机构发送公钥
- 认证机构用自己的私钥向服务器部署签名以及证书
- 服务器和客户端通信的时候就将证书发送至客户端,客户端收到证书之后先使用认证机构的公钥确认证书是否可信,从而确认服务器的公钥是否有效
- 客户端验证通过之后,使用服务器的公钥对报文进行加密
- 服务器在收到客户端发送的报文之后,使用私钥对这个报文解密
- 客户端向服务端发送自己支持的ssl版本和加密算法
- 服务端收到客户端发送的ssl版本和加密算法,从中筛选出ssl版本和加密算法,并且发送给客户端
- 服务端发送证书给客户端
- 最后服务端发送一个报文给客户端表示ssl握手阶段协商结束
- 客户端验证证书是否正确,并且生成一个随机数,提取公钥对这个随机数进行加密,加密后的字符串为pre master secret,并且发送给服务端
- 接着客户端会发送一个报文给服务端表示之后的报文加密会使用上面的那个随机数作为公钥对称加密
- 客户端发送finish报文,如果服务器能够解密这次的报文则说明握手成功,否则握手失败
- 服务端收到之后如果能够使用私钥解密pre master secret,也会发送同样的使用pre master secret进行加密的报文,并且此后就会使用pre master secret作为共享密钥进行加密解密操作。
- 服务端发送finsh报文表示ssl握手结束
确定服务器的名称和文件名
查询浏览器的缓存DNS,查询hosts文件,没有的话就查询本地的DNS服务器,查询本地的DNS服务器是递归查询,如果本地的DNS中查不到,就找根域名的DNS服务器,这个查询方式是迭代查询,根域名的DNS根据域名返回给本地DNS他应该找哪个DNS服务器c去找,c返回给本地DNS服务器他该去哪个DNS服务器去找,依次类推下去才得到IP地址
PUT请求:如果两个请求相同,后一个请求会把第一个请求覆盖掉。(所以PUT用来改资源)
Post请求:后一个请求不会把第一个请求覆盖掉。(所以Post用来增资源)
- get主要是为了获取数据,而post是为了提交数据。两者虽然都有给服务器传输数据的功能,但是意义是不一样的。
- get拼接在url后,post的数据放入body的param内
- GET的目的是是读取,所以,服务器对应的接口应该有幂等性。即:多次请求的数据,不会因为我的get改变。同时,因为幂等,所以就可以对GET请求的数据做缓存。
- get在url上传递参数,默认是ascii,不支持中文,要经过其他配置,而post内的编码可以是unicode-8,支持中文。
- URL的最大长度是2083个字符,path的部分最长是2048个字符。不过其实是ie8规定的,http协议没有这一点。
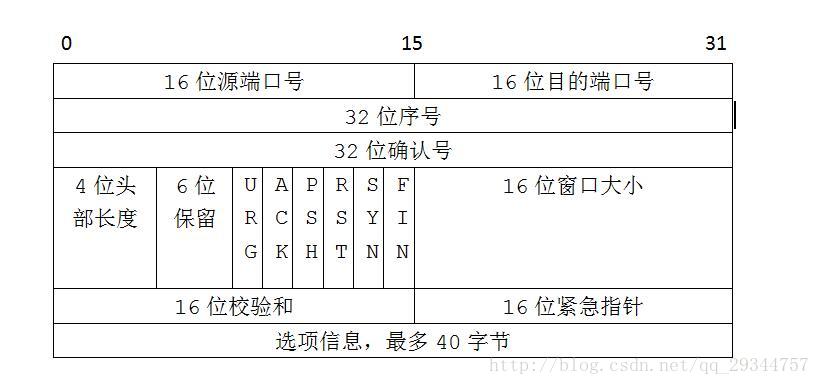
主要有下面几个:
- 16位源端口号
- 16位目的端口号
- 32位序号
- 32位确认号
- 4位头部长度
- 标志位:URG、ACK、PSH、RST、SYN、FIN
- 16位滑动窗口大小
- 16位校验和
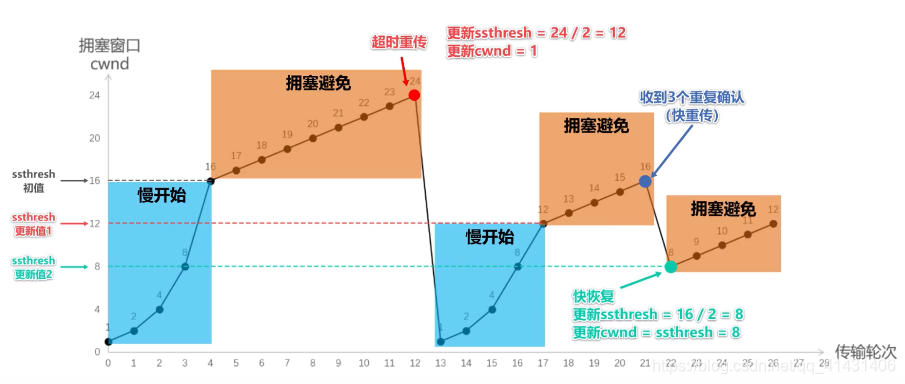
TCP开始传输的时候,如果发送方一开就传输大量的报文,假如这个时候网络拥塞很严重,发送大量的数据的时候同时也会加剧拥塞的效应,同时也会产生大量的丢包的情况,会产生大量的超时重传,所以TCP为了可靠传输就会有拥塞控制
- 慢开始:TCP在开始发送数据的时候首先会发送少量的数据探探路,然后再决定用什么样的速率传输。而速率取决于拥塞窗口的大小,开始拥塞窗口为1,每次收到ACK报文的时候,就让拥塞窗口大小变为原来的2倍。当窗口值=慢开始门限初始值(一般为16)
- 拥塞避免:每次收到一个ACK报文,拥塞窗口+1,如果遇到了超时重传的情况,让新的慢开始门限值变为原来的一半,将拥塞窗口设置为1,依次往复就会让网络传输的拥塞程度大大降低。
- 快重传:发送方连续接受到三个一样的ACK报文就会启动快重传
- 快恢复:当发送方收到三个连续确认时,就执行”乘法减小”算法,把”慢开始门限”减半,并且将拥塞窗口设置为慢开始门限值,注意接下来不会执行慢开始算法,而是执行拥塞避免的算法。
设置一个计时器,超时时间比往返时间RTT稍微长一点。如果超时重传之后的数据,还需要再超时重传,那么就是上一次重传时间的2倍。如果两次超时了,就说明网络不好,就不会发送了。
为了解决上面超时重传的超时时间周期较长的缺点,又有了快速重传。
简单而言就是,发送方发送数据,接收方接收数据,如果发送方发送的不是接收方想要的数据,接收方此时的ack会一直发送给发送方,如果发送方接收到了3次同样的ack报文,就会在计时器时间耗尽之前触发重传。
可是这种方式也会带来一个问题,发送方接受到ack报文之后,该发送ack想要的报文还是这个ack之后的所有报文。进而又有一个SACK方法来解决这个问题。
简单来说就是将缓存中接收到的报文都放进SACK字段中,发送方接收到了三次相同的ACK报文之后出发了快速重传,就会检查SACK字段有哪些报文,直接重传丢失的报文,而不用发送所有已经发送过的报文。
TCP是一次发送一次应答,但是这样的效率很底,所以就有了滑动窗口,在发送窗口之内,发送方不需要等待接收方的应答,直接发送数据。
发送方是根据接收方的接收能力来设立滑动窗口的大小的。在建立连接的时候接收方就会告诉发送方一个窗口大小的值。连接建立之后,每次应答的时候都会告诉发送方一个新的滑动窗口的值。

如果接收方发送的滑动窗口为0,则发送方就会一直等待接收方发送新的滑动窗口的值,如果接收方发送的报文丢失,则发送方便会一直等待导致死锁,解决的办法也是采用一个计时器,从发送方的滑动窗口为0值开始计时,如果超时了就会发送一个探测报文,接收方如果收到了探测报文段就会发送一个新的窗口值,如果发送的还是0,接收方就会再开启一个计时器,一般最多重复3次,如果超过了3次就会发送RST报文终止连接。

上图中ACK=600的报文如果丢失了也不会重传,因为可以通过下一次的ack来确定,途中的最后一次ack=700表示700之前的数据我都接收到了,这个就叫累计应答
全连接队列叫做SYN队列,半连接队列叫做Accept队列。
服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用accept 函数时把连接取出来。
当TCP最大全连接队列满了之后,服务端会抛弃后面进来的TCP连接。当服务器并发大的时候,如果TCP全连接队列太小了就容易溢出,溢出了请求就会被丢弃。
如果半连接队列满了,并且没有开启 tcp_syncookies,则会丢弃;
若全连接队列满了,且没有重传 SYN+ACK 包的连接请求多于 1 个,则会丢弃
如果没有开启 tcp_syncookies,并且 max_syn_backlog 减去 当前半连接队列长度小于 (max_syn_backlog >> 2),则会丢弃;
SYN泛洪攻击时,攻击方不停地建连接,但是建连接的时候只做第一步,第二步中攻击方收到server的syn+ack后故意扔掉什么也不做,导致server上这个队列满其它正常请求无法进来
发送方将ip数据报进行一个分组,然后分组传输给路由器,路由器根据路由表存储转发给下一跳的路由器,以此类推直到发送到目的地址的主机,目的主机对ip数据报进行重排序
路由表中有目的主机的网络号和下一跳的路由器的地址,可以通过rip协议和ospf协议来完善路由表

操作系统=========================================================================================================
BIO:同步阻塞IO,一个连接就是一个线程。线程上下文切换会有消耗,并且如果一个线程没有读取到东西,那么这个线程就会一直阻塞在读方法。
NIO:同步非阻塞IO,非阻塞IO是面向缓冲区的,对于NIO,如果TCP RecvBuffer有数据,就把数据从网卡读到内存,并且返回给用户;反之则直接返回0,永远不会阻塞。然后通过轮询的方式来询问缓冲区是否有数据了,多路复用有select、poll、epoll,区别见多路复用IO的对比
AIO:异步非阻塞IO。基于事件和回调机制实现的,应用操作会返回不会阻塞在方法中,当完成时,操作系统通知相关线程执行完毕,进行后续操作。和信号驱动的方式IO的区别是:数据拷贝fd的时候是同步的,所以整个IO并不是异步的。
- 进程是资源分配的最小单位,线程是程序执行的最小单位
- 进程有自己的独立地址空间,线程使用相同的地址空间
- 线程之间的通信更方便,进程通信方式
**互斥条件:**资源是独占的且排他使用,进程互斥使用资源,即任意时刻一个资源只能给一个进程使用,其他进程若申请一个资源,而该资源被另一进程占有时,则申请者等待直到资源被占有者释放。
**不可剥夺条件:**进程所获得的资源在未使用完毕之前,不被其他进程强行剥夺,而只能由获得该资源的进程资源释放。
**请求和保持条件:**进程每次申请它所需要的一部分资源,在申请新的资源的同时,继续占用已分配到的资源。
**循环等待条件:**在发生死锁时必然存在一个进程等待队列{P1,P2,…,Pn},其中P1等待P2占有的资源,P2等待P3占有的资源,…,Pn等待P1占有的资源,形成一个进程等待环路,环路中每一个进程所占有的资源同时被另一个申请,也就是前一个进程占有后一个进程所申请的资源。
epoll:有事您说,cpu来做。
在操作系统内核和linux应用程序之间开辟了一个空间,这个空间既不属于内核也不属于应用程序,所以就免去了用户态->内核态的切换的开销。但是这样还不够,select 和 poll 都是通过CPU轮询fd(文件描述符)的方式来进行操作的,但是epoll就和上面说的一样,有事了就喊一声CPU,cpu就去处理。
在Linux下
ps -ef | grep java上面的指令应该是很常用的,而中间的「|」就是管道,前一个进程的输出就是后一个进程的输入。
其实管道的实现是将输出放在内核的缓存中,一端只能写,一端只能读,而父进程和子进程都能同时写入管道,那么就会出现写入混乱的情况。管道一端只能写一端只能读,所以这个特性和队列是一致的。
在shell中输入上面的指令,其实是创建了两个子进程,一个进程只能写入,而另一个进程只能读。
首先父线程调用pipe(int fd[])创建管道,然后再fork()出来一个子线程,子线程也继承了父线程的管道,两者才能通信。
- 简单
- 通信效率低,不适合频繁两个进程之间频繁通信的场景
- 单向通信
- 传输的数据是无格式的字节流且大小受限
是通过内核中的消息链表实现的,所以消息队列生命周期随内核,没有关机或者关闭操作系统,消息队列便会一直存在。
- 双向通信
- 消息队列不适合比较大数据的传输
- 消息队列通信过程中,存在用户态与内核态之间的数据拷贝开销
为了解决消息队列存在用户态 -> 内核态的拷贝开销,所以在内存中单独开辟了一个内存空间。即两个进程分别在自己的虚拟内存空间中挑一块出来,映射到相同的物理内存中去,这样就可以进行双向通信了。
在linux中,可以通过kill -9使用9号信号来强制中断应用进程,-9(强制关闭)就是9号信号,-15(非强制关闭)就是15号信号
简历上写了一些大学的必修课,比如操作系统,计算机网络,组成原理
操作系统=========================================================================================================
多个进程是共享cpu和内存的,所以操作系统使用了虚拟内存来管理内存,防止内存泄漏。虚拟内存就是操作系统对主存概念的抽象。
虚拟内存为每一个进程提供了一个一致的、完整的地址空间,让每一个进程都产生了一种觉得自己是在独享内存的错觉。
虚拟内存有下面三个好处:
- 把主存看作为一个存储在硬盘上的虚拟地址空间的高速缓存,并且只在主存中按需缓存。
- 为每一个进程都提供了一个独立的地址空间,保护每一个进程的地址空间不会被别的进程破坏。
一个程序被执行永远只是一个CPU在执行它
计算机网络=========================================================================================================
- TCP是可靠传输(包括TCP的所有保证可靠传输的特性都没得),UDP不保证可靠传输
- TCP是面向字节流的,UDP是面向报文的
- TCP需要连接,UDP不需要连接
- TCP是点对点通信,而UDP可以1对1,也可以1对多
- TCP首部较长并且是变长的,UDP首部只有8个字节并且是定长的
- 校验和:将发送的数据段都当做一个16位的整数。将这些整数加起来。并且前面的进位不能丢弃,补在后面,最后取反,得到校验和。
- 超时重传
- 序列号/确认应答
- 拥塞控制:全局的调整,涉及到所有的主机、路由器,以及与降低网络传输性能有关的所有因素。
- 流量控制:点对点的调整,流量控制所要做的就是抑制发送端发送数据的速率,以便使接收端来得及接收
- 客户端发送一个SYN报文(SYN=1),同时会初始化一个序号,这个序号是随机的(seq=x),此时处于SYN_SENT状态
- 服务端如果接受到这个SYN的报文,会把相关的信息存放在半连接队列,并且会响应给客户端一个ACK报文(ACK=1),以及SYN报文(SYN=1)并且服务端也会初始化一个随机的序号(seq=y),并且返回的ack(小写的)= 客户端发送的序号+1(ack=x+1),此时服务器进入SYN_RCVD状态
- 客户端收到服务端的ACK响应报文之后,就可以真正的开始发送数据了,此时也会响应服务端一个ACK报文(ACK=1,ack=y+1),发送后客户端变成ESTABLISHED状态,当服务器收到这个报文之后也会进入ESTABLISHED状态。如果这时全连接队列没满,那么从半连接队列拿出相关信息放入到全连接队列中
服务端无法接收到客户端发送的ACK报文,就会处于SYN_RECVD状态,而客户端的状态则是ESTABLISHED状态,服务端是会超时重传SYN和ACK报文给客户端的,在Linux系统下重传的最大次数为5次,如果5次都失败了,这个时候服务端是会发送RST报文给客户端,并且自动关闭连接进入CLOSED状态,而客户端有两个选择,1. 是一直等待,等到操作系统检测到这个是一个死亡连接就会自动关闭 2. 如果客户端发送数据的话,则会一直重传这个数据包,默认15次,失败则会断开连接。
RST报文:用于复位因某种原因引起出现的错误连接,也用来拒绝非法数据和请求
由于网络阻塞,所以在客户端发送了两次SYN报文之后,旧的SYN报文会比新的SYN报文先到达,所以服务端先收到了旧的SYN,返回一个ACK报文给客户端,同时更新序号,客户端收到ACK报文之后校验序号不是自己想要的,所以会发送RST报文给服务端,只有收到正确的序号的报文才能继续握手。
为了同步序列号,所以不使用四次握手
如果只有两次握手的话,如果第一次客户端发送SYN报文之后,由于网络阻塞服务端没有收到SYN报文,客户端就会重发SYN报文,那么这个时候如果网络通顺了,就会进行两次连接的建立,导致资源被浪费。
造成资源浪费以及无法避免历史连接。假设之前连接了一次,客户端向服务端发送SYN包,但是由于网络堵塞,客户端重新发送一个SYN包给服务端,此时网络通畅,服务端发送了一个ACK包,此时连接建立,但是之前的SYN包此时又发送过来了,所以导致又重新建立连接。
不会怎么样,但是三次握手是最佳选择,避免再多一次发送报文浪费资源。
- 客户端发送一个FIN报文,此时客户端处于FIN_WAIT_1状态
- 服务端收到这个报文之后发送一个ACK报文,此时服务端可以继续发送数据,服务端处于CLOSED_WAIT状态
- 客户端收到了服务端发送来的ACK报文会处于FIN_WAIT_2状态
- 如果服务端发送完成之后想关闭连接,会发送一个FIN报文给客户端,服务端处于LAST_ACK状态
- 客户端收到这个报文之后,此时会开始计时一个2MSL(报文最大存活时间*2)的计时器,并且会响应一个ACK报文给服务端,并且处于TIME_WAIT状态
- 服务端收到ACK报文,关闭。
- 客户端经过了2MSL的时间就关闭了。
如果最后一次的客户端发送给服务端的ACK报文丢失或者被堵塞,服务端在一段时间内没有收到客户端传过来的ACK报文,会重新发送FIN报文,此时由于有一个等待时间,所以客户端可以再重发ACK报文,并且重新计时。
如果没有这个等待时间的话,服务端没有收到客户端发来的ACK报文,就会一直超时重传。
还有一个原因是,MSL是报文最大生存时间,如果没有这个时间的话,之前发送的报文由于网络堵塞,可能在下次连接的时候刚好发送到客户端,此时客户端是可能接收这个报文的。
JAVA=========================================================================================================
Hashmap的底层数据结构是数组+链表+红黑树,并且数组(哈希桶)的默认容量为16,负载因子是0.75,也就是说如果节点数(整个hashmap键值对数量不是哈希桶的占用个数)超过了16*0.75个就会扩容。如果链表长度大于8则将链表转换成红黑树,如果红黑树的数量小于6则退化成链表
- 红黑树首先是一个平衡二叉查找树,左子树的值比根节点的值小,右子树的值比根节点的要大
- 每个节点要么是红色要么是黑色
- 根节点是黑色的
- 每个叶子节点(null节点)为黑色
- 每个红色节点的两个子节点都是黑色的
- 任意节点到叶子节点的路径都包括了相同数量的黑色节点
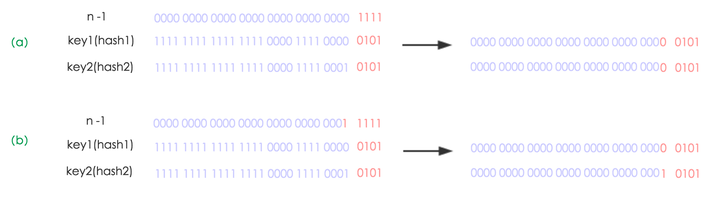
扩容是只对哈希桶进行扩容。
扩容的过程是:创建一个长度为原来的数组长度*2的数组,然后将原来的数组元素一个一个rehash放进新的数组,rehash在jdk1.8的时候是采用这种方式:由于每次扩容数组的元素都是2倍增长的,所以新的数组容量比原来的数组容量多了一位而已,如果新增的那一位为0,则该节点在新的数组中的位置和原来数组中的位置一样,否则为原来的数组位置+原来数组长度大小。
比如原来的容量为16,(16-1)=1111,扩容之后的大小为32,(32-1)=11111,然后用原来的hash值&新的容量,如果多出来的那位为1,则为原来的数组位置+原来的数组长度,否则不变。
根据key计算出hash,然后用这个hash^(n-1)来计算在数组中的位置,比较头节点,如果相等(哈希值相等并且对象的地址相等或者对象的equals相等)就返回,如果不相等就遍历链表或者红黑树,直到找到对应的key所对应的value
计算hash的方法是:key==null?key.hashcode^(key.hashcode>>>16),这个方法是一个扰动函数,能够减少hash碰撞,能够保留hashcode的高位特征和低位特征,让hash分布均匀,从而降低hash&(n-1)碰撞概率
首先判断数组是否为空,如果为空的话就进行扩容(初始化长度为16的数组)
如果不为空,就计算hash值并且判断该位置上有没有元素,如果有元素的话,就判断key值是否相等(hashcode和equals),如果相等就直接覆盖,如果不相等就遍历后边的元素,并且使用尾插法进行插入。如果没有元素的话就新建一个节点。如果一条链表的元素个数大于8,那么就转换成红黑树,不过有一个前提就是要整个map的所有键值对的个数都要大于64,不然就执行扩容。红黑树变回链表的条件是元素个数小于等于6个。

底层数据结构在jdk1.8的时候是和hashmap一样的数组+链表+红黑树。保证线程安全的方式是采用了CAS+synchronized来确保线程安全的,取代了jdk1.7中的分段锁的这种方式。
put方法调用的是putval方法,putval方法有三个参数:key、value、onlyIfAbsent:表示只有在key对应的value不存在时才将value加入。
如果给定的key对应的哈希桶为空(table[i] == null),使用CAS来设置头节点,如果头节点的哈希值为MOVED(hash(table[i] ) == -1),说明在扩容,就会帮着扩容,否则锁住链表的第一个节点,遍历后边的节点,看是否需要进行红黑树转换,并且插入节点。
1.8 支持并发扩容,HashMap扩容在1.8中由头插改为尾插(为了避免死循环问题),ConcurrentHashmap也是,迁移也是从尾部开始,扩容前在桶的头部放置一个hash值为-1的节点,这样别的线程访问时就能判断是否该桶已经被其他线程处理过了。
Jvm=========================================================================================================
堆、栈、方法区、本地方法栈、程序计数器
堆、方法区是公有的
程序计数器、Java虚拟机栈是线程私有的
类型信息,静态变量,常量,即时编译的代码缓存
- 检查常量池中是否有这个对象的符号引用
- 如果没有的话执行类加载的过程,如果有的话,就从堆中分配内存
- 分配内存完成之后就初始化0值
- 设置对象头,比如hashcode、年龄信息、是哪个对象的引用等等
- 执行对象的构造方法
- 投入使用
在虚拟机栈中的本地方法表中存放了引用类型,通过引用类型来查找,这个引用类型查找的方式有两种。
第一种是引用类型存放的都是直接指针,这样直接指向了Java堆中的对象实例,实例中存放了指向方法区的类型信息的指针。
第二种是使用句柄的方式来查找,栈中存放的引用类型是指向Java堆中的句柄指针,句柄又存放了到堆中对象实例的指针和指向方法区中的类型信息的指针。
MySQL=========================================================================================================
同上
可重复读
- 脏读:读取未提交数据
- 不可重复读:在一个事务中,读取同一行的结果不一样
- 幻读:在一个事务中,读取表的数据前后不一样(增加或者减少了一行)
可参考事务的实现
在事务提交的时候会将更新记录写到redolog当中,然后再去修改缓冲池里面的真正数据页。为了确保redolog写成功,mysql会强制调用fsync将redolog写到磁盘上。
事务是有持久性的,持久性是由redolog保证的,事务提交之后写了redolog就代表完成了,之后持久化到硬盘这个操作可能不会立刻完成,等到空闲的时候来进行持久化硬盘
表锁有元数据锁和表级锁。
元数据锁不需要显式的加上,每次对表进行CRUD的时候会自动加上元数据读锁,对表的结构进行修改的时候会加上元数据写锁,读锁不会线程互斥的,写锁是线程互斥的
显式的执行对这个表的锁操作,语法:lock table read/write,读锁不会互斥,写锁会互斥,并且写锁仅仅值能让加上这个锁的线程进行写,其他的线程无法读写。
行锁是锁住这一行的,有读锁和写锁,读锁不互斥,写锁互斥。
行锁由于有两段锁协议所以只能在事务提交的时候释放,如果数据库的设置auto_commit = 1的话,一个SQL语句就是一个事务,也就是说这样的话一个写语句也会堵塞其他的事务。
解决幻读的问题。给数据的间隙加上锁,就不让新插入的数据能让其他的事务更新了。
Redis=========================================================================================================
string set hash zset hyperloglog 布隆过滤器
每次添加key的时候使用3个函数,让得到的值余上数组长度,然后将对应的位置置为1,添加就完成了。过滤就反其道而行之,看对应的位置是否为0,有一个为0的话,那么就表示不存在这个key
推送的时候可以使用布隆过滤器来避免推送了用户的浏览历史内容
数组,类似于ArrayList的底层实现
为什么不问spring的那些东西
只要基础好,spring给两天时间就能会,深入的得看源码
JVM=========================================================================================================
- 标记清除算法
- 标记复制算法
- 标记整理算法
- 本地变量表(存放在虚拟机栈中)中引用的对象比如临时变量,参数变量
- 引用类型的静态变量
- 常量池中引用的对象
- JVM内部的引用对象(比如一些异常类OutOfMemoryError,Class对象)
- 被Synchronized上锁的对象
首先先进行标记阶段,标记有两次标记,第一次看这个对象能否和GC ROOT对象关联起来,如果没有关联就会做上第一次标记,随后看这个对象是否执行finitialize()方法,如果执行过了就没必要执行了,如果没执行的话,就将这个对象放入F-QUEUE。第二次标记的过程,会依次调用队列中的对象的finitialize()方法,如果和GCROOT对象产生了关联就不会被标记,如果还是没有关联的话就要被清除了。然后对这些被标记上的对象进行清除。
优点:实现比较的简单
缺点:1.执行效率不稳定,在堆中如果有很多对象都要被清除,那么效率就会下降
2.可能产生内存碎片的问题
加载->验证->准备->解析->初始化->使用->卸载
- 通过类名称获取这个类的二 进制字节流
- 将二进制字节流的静态存储结构转化成方法区的运行时数据结构
- 在内存中(java堆)生成一个Class对象,作为方法区的数据的入口
对于数组类而言,数组类本身是JVM直接在内存中动态构造出来的,但是对于数组的元素类型的不同也有不同的策略。
如果元素是引用类型的话,就递归的调用上面的加载过程
如果是基本数据类型的话,就调用引导类加载器加载。
验证的步骤有下面几步:
- 文件格式验证(比如魔数、版本号等等)
- 元数据验证(比如这个类是否有父类、这个类的父类是否继承了final修饰的类等语法检查)
- 字节码验证
- 符号引用验证 是否能够通过符号来找到字段中引用的类,字段的类是否能够被当前类访问到
就是给静态变量进行初始化0值,如果使用final修饰的话,就会直接赋值,并不会变成0值
解析是将常量池中的符号引用转换为直接引用的过程
符号引用是可以以任何形式定位到目标的字面量,各种虚拟机的实现的内存布局可以各不相同,但是接收的符号引用必须相同
指向目标的指针、相对偏移量、句柄都是直接引用
- 类和接口解析
- 字段解析
- 方法解析
- 接口方法解析
调用<clint>()的过程,即静态代码块的调用
- 魔数和class文件的版本号
- 常量池:包括字面量和符号引用,字面量就是字符串的文本,被标识为final的变量,而符号引用包括package名称、字段的名称和描述符、类和接口的全限定类名
- 访问标志:标识当前类的访问权限
- 类索引:用来确定该类的全限定类名
- 字段表集合:比如访问权限、作用域、是否被标记为final、是否有voliate和transient修饰
- 方法表集合:和字段表集合类似
如果类加载器收到了类加载的请求,首先并不会自己去执行加载的过程,而是委托给父加载器,每一个层次都是这样。
层次从上到下分别是:启动类加载器、扩展类加载器、应用程序加载器、自定义加载器
首先介绍一下SPI技术,SPI是(service provider interface)的缩写,为了某个接口寻找实现类的一种机制,比如在JDBC里面,在jar包的META-INF/service文件夹下有一个java.sql.Driver的文件,里面写了这个接口的实现类的全限定类名com.mysql.cj.jdbc.Driver,所以在调用接口的时候就会去找这个类,下面的代码
// com.spi.SPIService 存放在/META-INF/services/下,内容是
// com.spi.SPIServiceImpl01
// com.spi.SPIServiceImpl02
public interface SPIService{
void say();
}
public class SPIServiceImpl01 implements SPIService{
@Override
public void say() {
System.out.println("第一个实现类");
}
}
public class SPIServiceImpl02 implements SPIService{
@Override
public void say() {
System.out.println("第二个实现类");
}
}
public class SPIDemo {
public static void main(String[] args) {
ServiceLoader<SPIService> services = ServiceLoader.load(SPIService.class);
for (SPIService service : services) {
service.say(); // 调用两个实现类的方法,需要构造方法才能够加载
}
}
}回到正题,如何打破双亲微派模型呢?这个还是看看源码就知道了。下面是ServiceLoader.load()方法的代码
@CallerSensitive
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return new ServiceLoader<>(Reflection.getCallerClass(), service, cl);
}
@CallerSensitive
public ClassLoader getContextClassLoader() {
if (contextClassLoader == null)
return null;
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
ClassLoader.checkClassLoaderPermission(contextClassLoader,
Reflection.getCallerClass());
}
return contextClassLoader;
}通过线程上下文加载器来进行打破,这个加载器可以在线程创建的时候设置,如果没有设置的话那么就会从父线程继承一个,那么这个加载器就是应用程序加载器,在JDK1.6之前的SPI技术是父加载器请求子加载器加载的行为,已经违反了双亲委派模型,因为JNDI服务需要在classpath下面去找JNDI服务提供者接口,但是JDNI的代码是由bootstraploader加载的,但是bootstraploader加载不了classpath下面的代码,只能请求子类加载器去加载,所以违反了双亲委派模型。但是上面的SPI实现是符合双亲委派模型的。
是由SystemClassLoader加载的,ExtClassLoader是加载ext/目录下的class文件
MySQL=========================================================================================================
A(原子性):一个事务中的操作要么一起成功要么一起失败
C(一致性):事务前后数据的完整性必须保持一致
I(隔离性):不同事务之间不能相互干扰,事务的隔离级别有:读未提交、读提交、可重复读、可串行化
D(持久性):事务提交之后就算发生故障也不会影响这个结果
B+树
- 只有叶子节点存放的是数据,其他的节点存放的都是索引,这样的好处就是一次性读入内存的数据更多
- 查询效率更稳定
- B+树的数据都存储在叶子结点中,各个叶子节点有兄弟指针,所以,扫库的时候很方便,只需要扫一遍叶子结点即可
可能产生页分裂,减小存储空间的利用率
由于B+树的特点是叶子节点的一个节点存放了多个数据,如果要插入的数据刚好是在这个满了的节点,就会导致这个节点的数据都分散开来,本来一页能存放的数据,变成了两页存放,所以就会导致页分裂并空间利用率降低了50%
Redis=========================================================================================================
https://www.cnblogs.com/yangmingxianshen/p/8054094.html
使用object encoding {key} 查看编码
String有 int(value是数字,并且不带引号的时候的编码),embstr(字符串比较短的时候的编码),raw(字符串比较长的编码),如果string超过44字节就从embstr变成raw
Hash有ziplist:当field个数比较少且没有大的value时,内部编码为ziplist;hashtable:当有value大于64个字节或者当field个数超过512,内部编码会由ziplist变为hashtable
list有ziplist:当元素个数较少且没有大元素时,为ziplist;linkedlist:当元素个数超过512个或者当某个元素超过64个字节,内部编码变为linkedlist
set有intset:整数集合,当元素比较少的时候并且都是整数的时候,内部编码是intset ;hashtable:当元素个数超过512个,或者某个元素不为整数的时候,内部编码为hashtable
缓存
Spring=========================================================================================================
使用field注入的话,遇到循环依赖会解决不了这个问题
https://segmentfault.com/a/1190000022119546
- 开启一个计时器
- 从Spring.factories文件中加载监听器,发布应用启动开始的事件
- 设置输入的参数(main方法的args)
- 配置环境(profile)
- 根据不同的web环境,创建ApplicationContext,比如如果是servlet环境的话,创建
AnnotationConfigServletWebServerApplicationContext - 预处理ApplicationContext,为刚创建的容器对象做一些初始化工作
- 刷新ApplicationContext,注册BeanPostProcessor,调用BeanFactory的后置处理器
- 执行刷新容器后的后置处理逻辑(为空方法)
- 调用CommandLineRunner和ApplicationRunner接口的Run方法
- 返回容器对象
使用@Transactional加在方法上
Spring有7种传播机制:
- 如果存在一个事务则支持这个事务,如果不存在则开启一个事务
- 总是开启一个事务,如果当前有事务则将这个事务挂起
- 有事务则支持这个事务,没有就不以事务的方式进行
- 有事务则支持,没事务抛出异常
- 总是以非事务的方式进行,挂起任何存在的事务
- 总是以非事务的方式进行,如果存在事务则抛出异常
- 如果一个活动的事务存在,则运行在一个嵌套的事务里面,如果没有事务按照第一种方式进行
可以加,但是没有意义。
Spring事务是使用AOP实现的,如果加在了private方法上的话,生成的代理对象调用的方法并不会调用到这个方法。
可以参考设计模式
单例?太简单了。介绍一下装饰器模式
public class SingletonPattern{
// 取消指令重排
private volatile Object instance;
private SingletonPatern(){
}
// 双重判断,线程安全
public static synchronized Object getInstance(){
if(instance == null){
instance = new SingletonPattern();
}
return instance;
}
}interface Car{
void name();
}
interface CarFactory{
Car getCar();
}
class Tesla implements Car{
@Override
public void name(){
}
}
class BMW implements Car{
@Override
public void name(){
}
}
class TeslaFactory implements CarFactory{
@Override
public Car getCar(){
return new Tesla();
}
}
class BMWFactory implements CarFactory{
@Override
public Car getCar(){
return new BMW();
}
}在响应头中有一个content-length记录了这个报文的长度,如果没有content-length字段,计算方法来源于 RFC2616 4.4节,找了一个博客比较的好理解,content-length
Content-Length首部指示出报文中实体主体的字节大小. 但如在请求处理完成前无法获取消息长度, 我们就无法明确指定Content-Length, 此时应该使用Transfer-Encoding: chunked,数据是以一系列分块的形式发送的,每一块的chunk都有对应的长度,且终止块的长度为0
下面的图应该是最全的了

通过pipe(int fd[])来创建管道,fd[1]为写入端,fd[0]为输出端,通常由父进程进行管道的创建,然后fork()出来子进程,并且子进程也继承了父进程的管道,父进程向管道写,子进程从管道读
消息不丢失要分三端来看:
-
默认情况下,可以通过同步的方式阻塞式的发送,check SendStatus,状态是OK,表示消息一定成功的投递到了Broker,状态超时或者失败,则会触发默认的2次重试。此方法的发送结果,可能Broker存储成功了,也可能没成功
-
采取事务消息的投递方式,并不能保证消息100%投递成功到了Broker,但是如果消息发送Ack失败的话,此消息会存储在CommitLog当中,但是对ConsumerQueue是不可见的。可以在日志中查看到这条异常的消息,严格意义上来讲,也并没有完全丢失
-
RocketMQ支持 日志的索引,如果一条消息发送之后超时,也可以通过查询日志的API,来check是否在Broker存储成功
-
消息支持持久化到Commitlog里面,即使宕机后重启,未消费的消息也是可以加载出来的
-
Broker自身支持同步刷盘、异步刷盘的策略,可以保证接收到的消息一定存储在本地的内存中
-
Broker集群支持 1主N从的策略,支持同步复制和异步复制的方式,同步复制可以保证即使Master 磁盘崩溃,消息仍然不会丢失
- Consumer自身维护一个持久化的offset(对应MessageQueue里面的min offset),标记已经成功消费或者已经成功发回到broker的消息下标
- 如果Consumer消费失败,那么它会把这个消息发回给Broker,发回成功后,再更新自己的offset
- 如果Consumer消费失败,发回给broker时,broker挂掉了,那么Consumer会定时重试这个操作
- 如果Consumer和broker一起挂了,消息也不会丢失,因为consumer 里面的offset是定时持久化的,重启之后,继续拉取offset之前的消息到本地
- producer在发送消息的时候可以判断sendstatus是否为OK,如果为OK则表示发送成功,如果失败了就重试,默认重试两次。
- 采用事务的方式,发送之后如果检查sendstatus不是ok的,则消息会存储在Commtlog当中,但是对消费者不可见
有一个方案就是强迫用户不使用这么简单的密码,剩下的方案待完善
图示如下:

XSS攻击是指利用网页开发的漏洞,通过一些方法将恶意的指令注入到网页,就比如可以使用JS来插入一些恶意脚本,恶意代码未经过滤,与网站正常的代码混在一起;浏览器无法分辨哪些脚本是可信的,导致恶意脚本被执行。
参考维基百科NAT协议
为了解决IPV4地址短缺的问题,所以就有了NAT协议,这个协议的功能是将内部网络的IP地址转换成万维网上面的IP地址
buffers 就是存放要输出到disk(块设备)的数据,缓冲满了一次写,提高io性能(内存 -> 磁盘)
cached 就是存放从disk上读出的数据,常用的缓存起来,减少io(磁盘 -> 内存)
buffer是即将要被写入磁盘的,cache是被从磁盘中读出来的
使用索引的目的是加快查询的速度,扫描的行数越少用的时间越少,所以就越快,所以问题就出在了扫描行数上面。同一个索引上面出现的不同的数字越多,索引的区分度就越大,这个数量叫做基数(cardinality),具体可以使用show index from table来查看这个数据。MySQL统计这个数字的方法是采样统计,选择N个数据页,统计这些页面上不同的值,得到一个平均值,然后乘上索引的页面数就得到了这个数量。这个数量是不准确的,所以需要定时的来执行analyze table来刷新这个数据,保证索引选择的正确性